开发态Serverless
通过算力包和Serverless架构的强强结合,推出了一款专为大型模型开发者设计的IDE插件—Aladdin(Alaya AI Addin)。该插件实现了本地开发环境与云端弹性容器集群之间的无缝对接,使得开发者可以轻松利用云端的强大算力,而无需担心基础设施的管理问题。无论是进行大规模的数据处理还是复杂的模型训练与推理,Aladdin都能提供流畅且高效的开发体验,
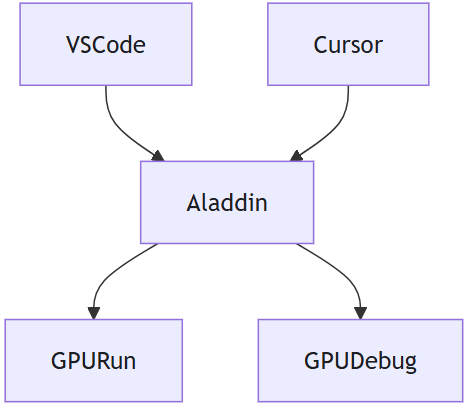
Workshop基于CPU/GPU资源运行,开发者可专注于代码开发,Aladdin支持用户构建算法原型,其低资源消耗特性既降低了使用成本,又便于长时间稳定运行,尤其适合大模型的开发阶段。
- 高效率开发环境和所需GPU算力开箱即用,免除运维烦恼。直连云端算力集群,代码调试、模型训练如在本地进行般丝滑。
- 高弹性根据任务需求智能弹性调度算力资源,实现算力资源充足高效供给,任务完成即释放算力。
- 低成本算力包按量计费,小投入即可玩转百亿大模型微调,彻底告别资源闲置,开发成本不再“开机即烧钱”。
训练态Serverless
系统为用户提供了两种启动GPU训练服务的方式,示意图如下:
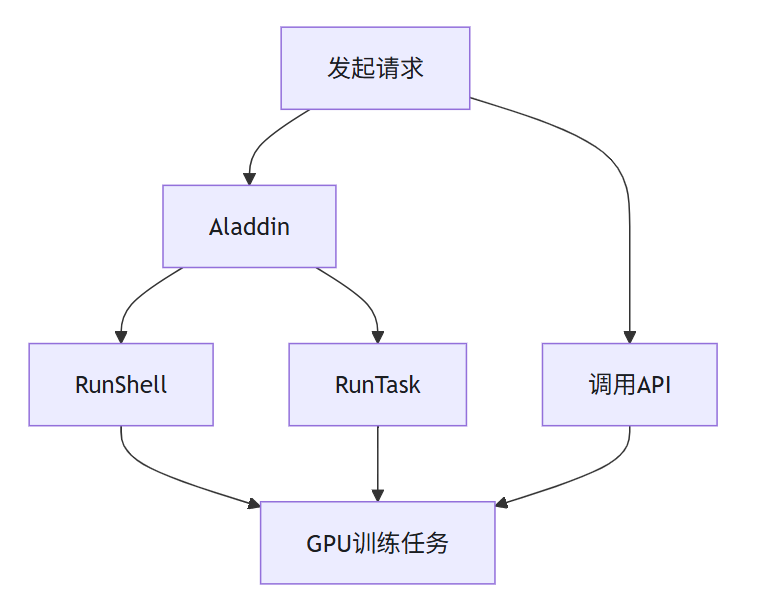
通过Aladdin启动GPU训练任务:Aladdin在Serverless训练态应用场景中展现出卓越的适用性。用户仅需上传训练数据,即可在Aladdin上快速启动GPU训练任务,无需手动搭建复杂的运行环境,真正实现“即传即训”,大幅提升训练效率与使用体验,点击Aladdin了解更多。
通过调用API启动GPU训练服务:依托弹性容器集群提供的高效管理能力与秒级冷启动特性,我们推出了全新的OpenAPI产品。该产品专为AI训练与微调场景打造,可显著简化并加速AI模型从开发、训练到优化的全流程,助力开发者高效构建智能化应用。 通过Open API,开发者可以快速部署和弹性扩展计算资源,高效进行模型训练与调优,同时享受无缝集成与自动化运维带来的便捷体验。无论您是进行小型实验还是大规模生产部署,Open API都能提供强有力的支撑与保障,点击任务相关了解更多。
通过调用API启动GPU训练服务:依托弹性容器集群提供的高效管理能力与秒级冷启动特性,我们推出了全新的OpenAPI产品。该产品专为AI训练与微调场景打造,可显著简化并加速AI模型从开发、训练到优化的全流程,助力开发者高效构建智能化应用。 通过Open API,开发者可以快速部署和弹性扩展计算资源,高效进行模型训练与调优,同时享受无缝集成与自动化运维带来的便捷体验。无论您是进行小型实验还是大规模生产部署,Open API都能提供强有力的支撑与保障,点击任务相关了解更多。
- 业务能力覆盖模型开发、训练和推理等AI全生命周期,可以快速启动训练任务,多LoRA部署快速上线服务,加速模型迭代。
- 基于Serverless架构,实现秒级算力计费和弹性伸缩,根据实时业务流量在线动态扩缩容,无请求时无需支付费用。
- 符合标准Open API规范,保证接口的兼容性和可维护性,降低业务系统集成的复杂性。
推理态Serverless
系统为用户提供了两种灵活部署GPU推理服务的方法,示意图如下。
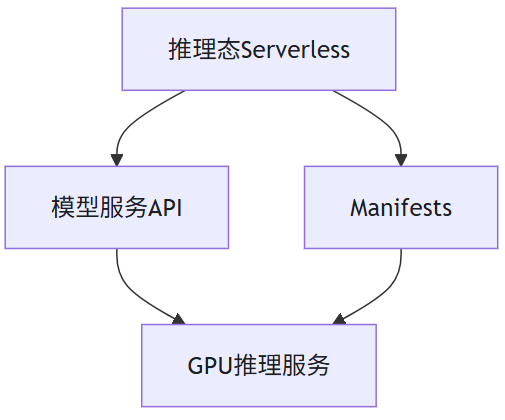
通过调用API方式创建GPU推理服务:用户可以通过简单的API调用来快速启动GPU推理服务,无需关心底层资源的细节。该方式极大地简化了操作流程,使用户能够专注于其核心业务,点击模型服务了解更多。
私有化部署VKS(弹性容器集群):系统支持用户在自己的环境中私有化部署VKS,利用Kubernetes Manifests(清单)轻松创建GPU推理服务。这种方法不仅让用户可以运行自定义代码、管理数据以及集成应用,而且免去了对底层基础设施运维与管理的关注。此外,通过这种部署方式,用户可以高效地实现GPU推理服务的Serverless部署,无需进行额外的安装和配置,点击VKS Serverless了解更多。
- 集低成本与高安全于一身,多集群资源和数据隔离,按需扩缩容算力资源降低算力成本,一键快速部署降低运维成本。
- 弹性容器集群支持用户快速部署Serverless推理服务,可以根据业务流量等不同策略实现推理服务实例的动态扩缩容。
- 平台支持基于流量的自动扩缩容机制,具备缩容至零的能力,在低负载或无负载期间大幅降低计算资源开销。