评估大语言模型(LLM)
在训练完大模型后,需要评估其效果,根据用途的不同需要进行不同类型的评估。下面将先讲解如何选择评估方式,再以一个实际案例讲解如何在平台中进行评估。
如何选择评估方式
在评估大语言模型的能力时,需要从多个维度全面考量其性能表现。这不仅涉及到利用多样化的任务来测试模型的各种能力,还需要针对性地选择合适的评测指标,以确保准确衡量模型的性能。
常见的性能考量维度有:
- 流畅合理的文本生成能力
- 代码生成能力
- 上下文理解能力
- 知识推理能力
- 生成内容的无害性、真实性
- 通用知识(人类常识)的储备
- 准备选用扩展工具的能力
常见的评测指标包括:
- 精确率(Precision):计算模型预测为正例的样本中真正为正例的比例。
- 召回率(Recall):计算真正例的样本中被模型正确预测的比例。
- F1 分数(F1 Score):综合衡量模型输出的精确率和召回率。
- 困惑度(Perplexity,PPL):衡量模型对参考文本的建模概率。
- BLEU(Bilingual Evaluation Understudy):衡量机器翻译与参考翻译之间的重叠度。
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation):衡量机器摘要对参考摘要的覆盖度。
- 准确率(Accuracy):衡量模型预测的正确答案的比例。
- 成功率(Success Rate):衡量模型成功完成任务的比例。
- Pass@k:估计模型生成的 k 个方案中至少能通过一次的概率。
- Elo 等级分:衡量模型在候选者中的相对水平。
- 模型评估: 使用能力更强的LLM来评测答案。
再根据需要考察的模型性能维度来搜集相关数据集,使用合适的评测指标在这些数据集上进行评估,即形成了综合评估指标,如:
- MMLU 是一个综合性的大规模评测数据集,涵盖了人文科学、社会科学、自然科学和工程技术等多个领域,通过选择题的形式对模型能力进行检验。
- Chatbot Arena 采用匿名的方式,允许人类用户与两个匿名大模型进行聊天并标注回答质量,通过这些人类产生的样本计算模型的Elo评分。
一些常用的Benchmark如下图所示(引用自:arXiv:2303.18223 [cs.CL]):
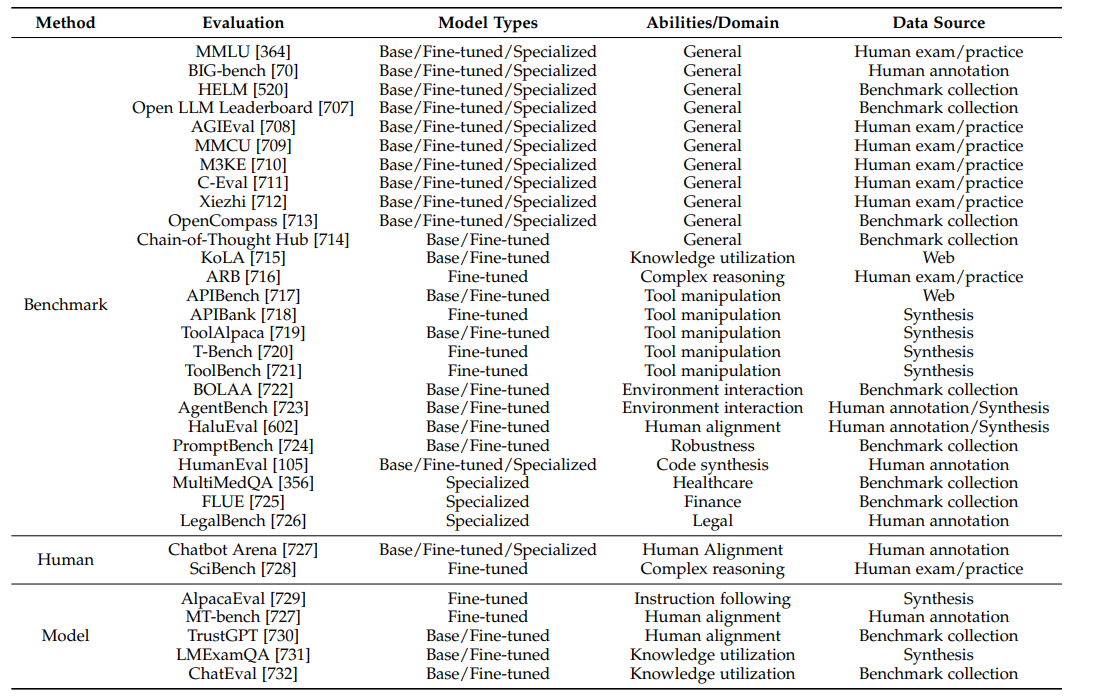
需要注意的是,出现较早的Benchmark都会有或多或少的数据泄露,导致模型对这些评测方式过拟合,选择比较新出现的Benchmark会得到更可靠的评估结果。
综上,在选择具体评测指标时候,需要根据自身的场景特点选择性能考量维度,再进一步选择评估方式。
评估案例
由于具体场景与评估方式都很多样,但是在平台中的使用方式都是类似的,本教程中仅以MMLU为例做说明。
-
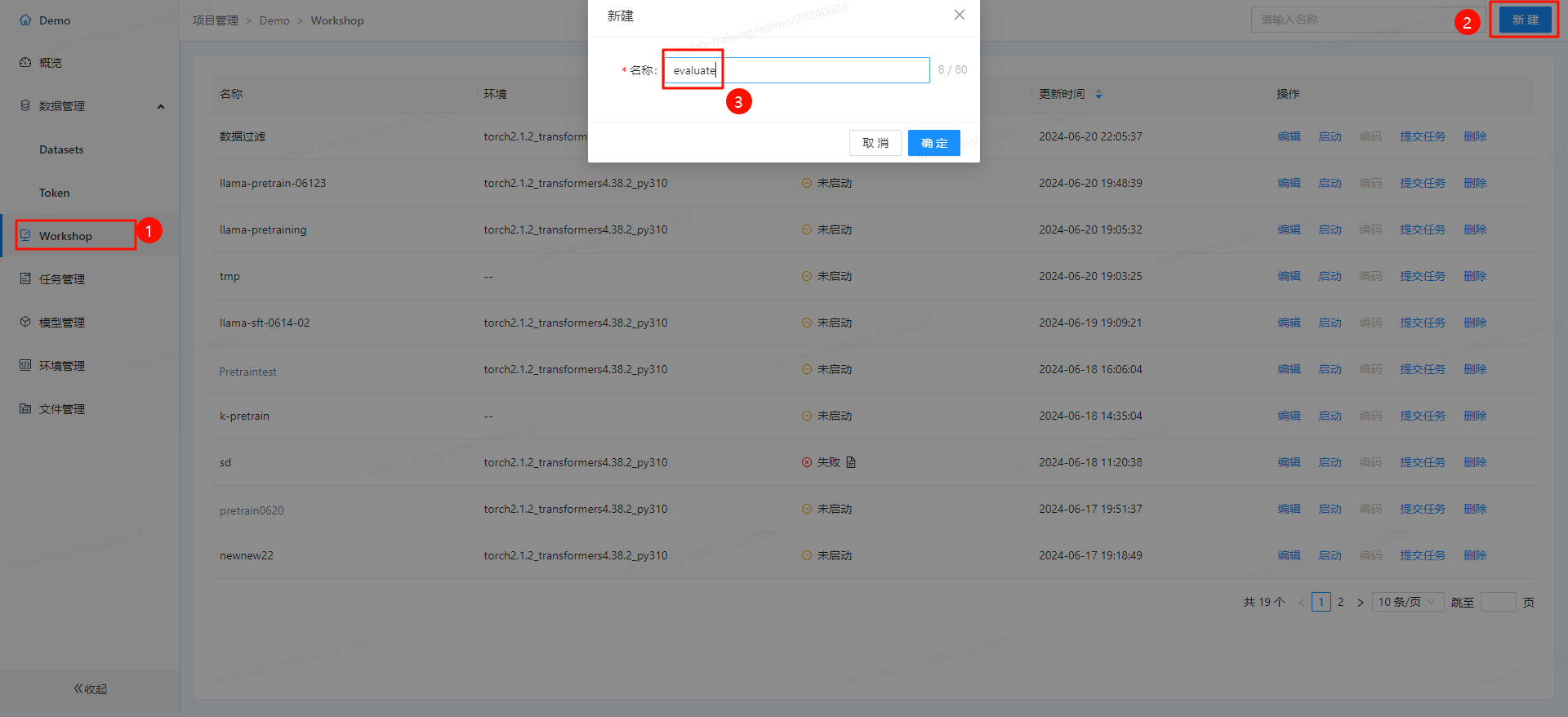
进入训练LLM所在的项目,在workshop中新建项目 “evaluate”
-
再在其中开发评估代码,本例中使用 “instruct-eval” 框架进行评估:
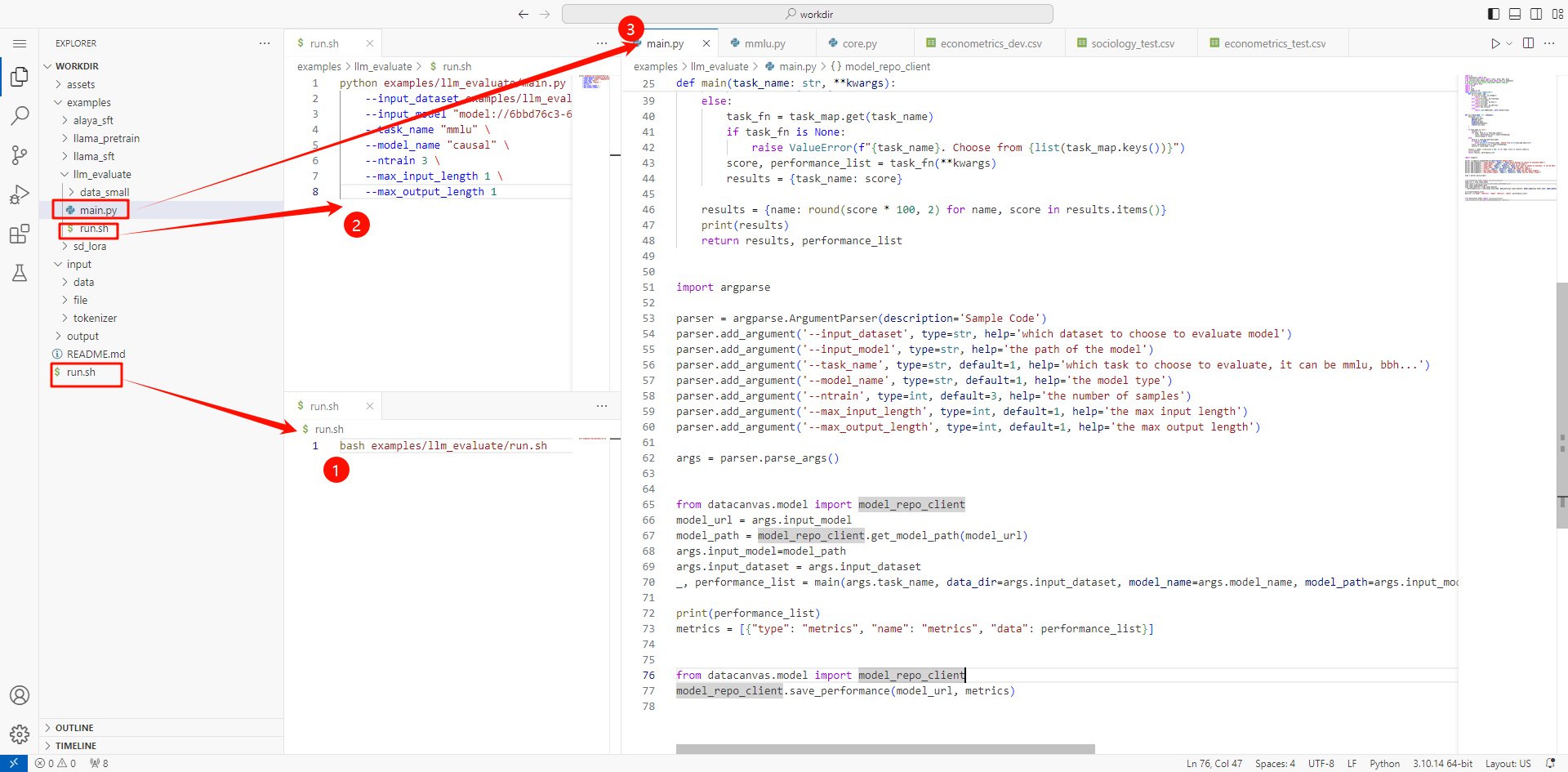
入口代码为:以下代码内容缩进一级,文档不调了markdown缩一级不好缩,格式会乱
import os
from datacanvas import doc
from instruct_eval.utils import crass, drop, bbh, mmlu
from instruct_eval.human_eval.main import main as humaneval
from fire import Fire
import torch
import os
import json
import numpy as np
class (json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.bool_):
return bool(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(NpEncoder, self).default(obj)
def main(task_name: str, **kwargs):
task_map = dict(
mmlu=mmlu.main,
bbh=bbh.main,
drop=drop.main,
humaneval=humaneval,
crass=crass.main,
)
if task_name == "all":
results = {}
for name, task_fn in task_map.items():
score, performance_list = task_fn(**kwargs)
results[name] = score
else:
task_fn = task_map.get(task_name)
if task_fn is None:
raise ValueError(f"{task_name}. Choose from {list(task_map.keys())}")
score, performance_list = task_fn(**kwargs)
results = {task_name: score}
results = {name: round(score * 100, 2) for name, score in results.items()}
print(results)
return results, performance_list
import argparse
# 读取参数
parser = argparse.ArgumentParser(description='Sample Code')
parser.add_argument('--input_dataset', type=str, help='which dataset to choose to evaluate model')
parser.add_argument('--input_model', type=str, help='the path of the model')
parser.add_argument('--task_name', type=str, default=1, help='which task to choose to evaluate, it can be mmlu, bbh...')
parser.add_argument('--model_name', type=str, default=1, help='the model type')
parser.add_argument('--ntrain', type=int, default=3, help='the number of samples')
parser.add_argument('--max_input_length', type=int, default=1, help='the max input length')
parser.add_argument('--max_output_length', type=int, default=1, help='the max output length')
args = parser.parse_args()
# 读取模型并评估
from datacanvas.model import model_repo_client
model_url = args.input_model
model_path = model_repo_client.get_model_path(model_url)
args.input_model=model_path
args.input_dataset = args.input_dataset
_, performance_list = main(args.task_name, data_dir=args.input_dataset, model_name=args.model_name, model_path=args.input_model, max_input_length=args.max_input_length, max_output_length=args.max_output_length, ntrain=args.ntrain)
print(performance_list)
metrics = [{"type": "metrics", "name": "metrics", "data": performance_list}]
# 将评估结果写回到模型
from datacanvas.model import model_repo_client
model_repo_client.save_performance(model_url, metrics)
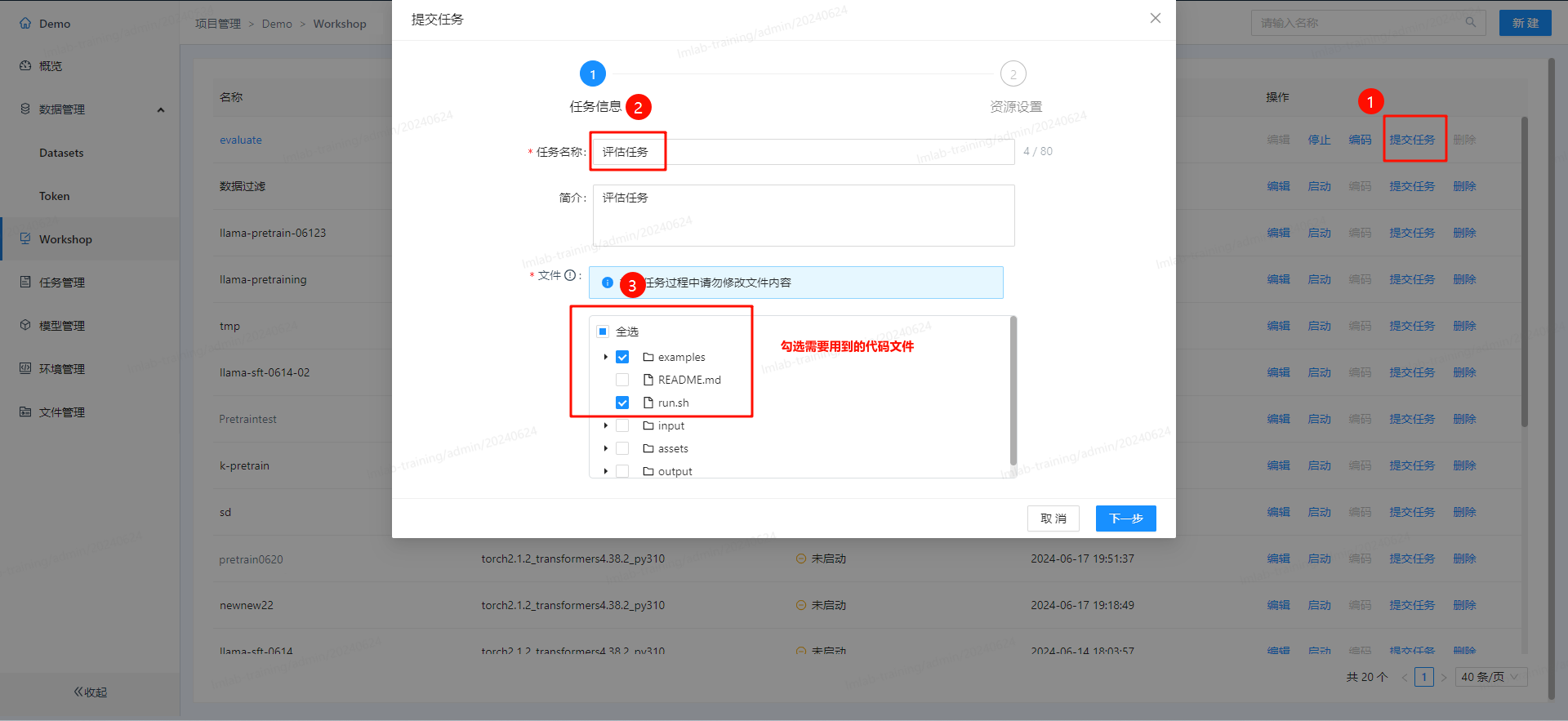
- 发布项目运行:
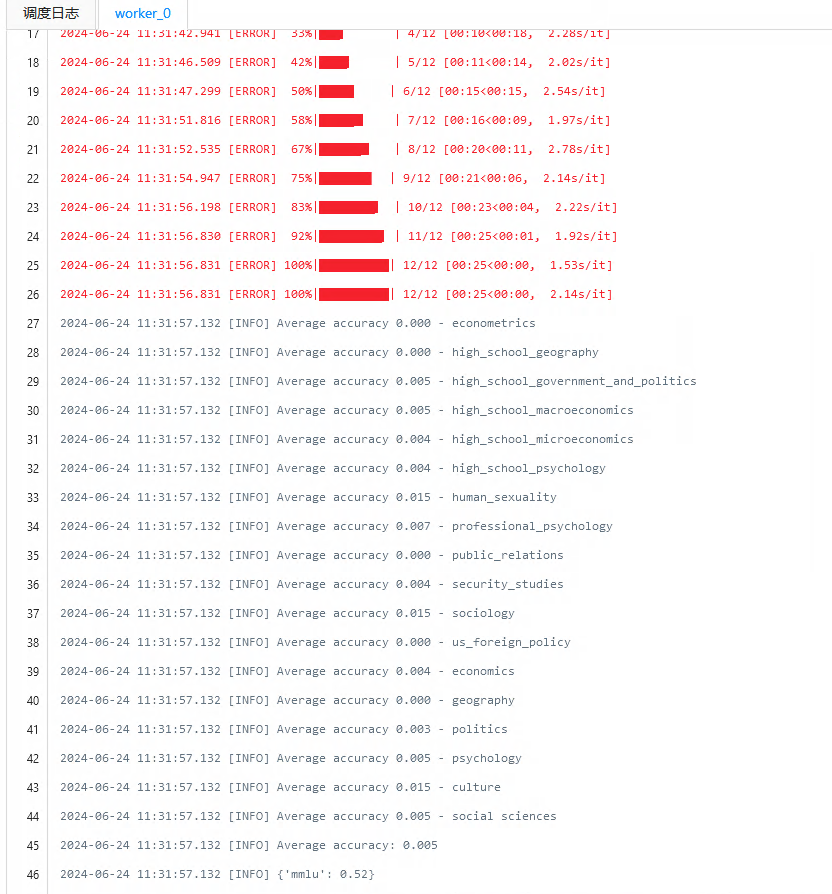
- 查看评估任务的日志:
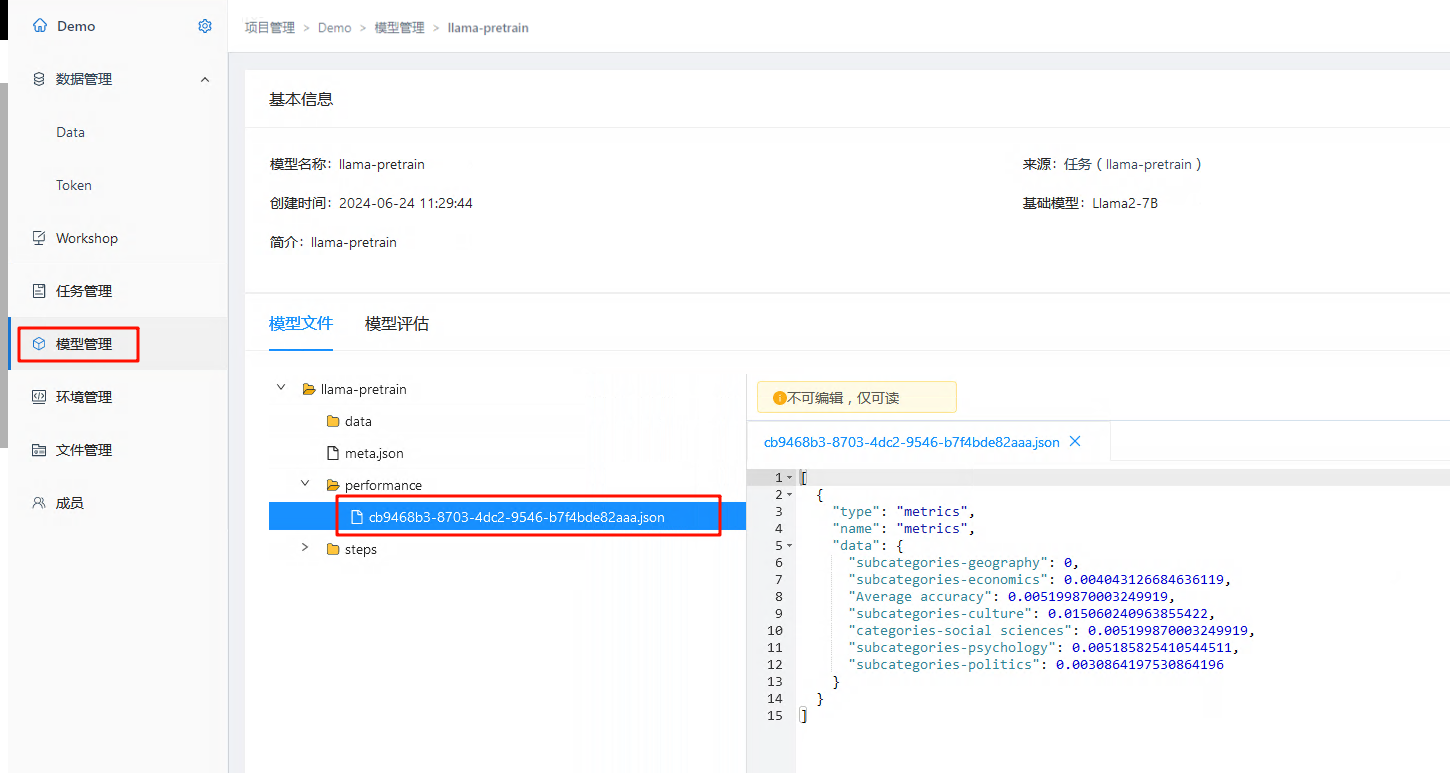
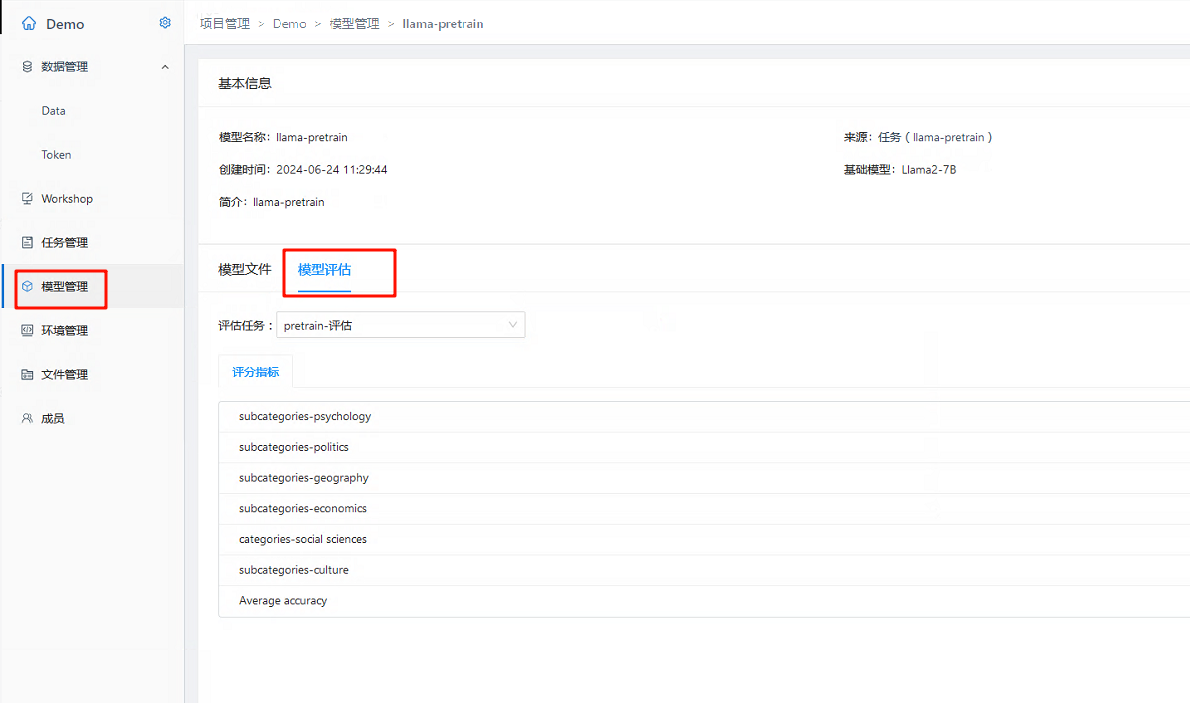
- 当评估任务执行完成后,可以在模型管理中看到提交的评估结果: