单机实验
在深度学习模型微调过程中,存储介质的选择对训练效率、系统性能及数据管理具有重要影响。本文以相同微调策略在不同存储类型上进行实验,即分别使用内存临时文件系统(/dev/shm)与大容量存储作为部署环境,对同一模型进行微调。通过对比两者在模型加载耗时、数据集加载耗时及整体微调耗时等方面的表现,分析上述两类存储对微调的影响,旨在为用户在使用大模型服务时提供合理的存储选型参考。
前提条件
- 用户已经获取Alaya New企业账户和密码,可点击 进行快速注册。
- 用户已在VS Code/Cursor代码编辑器内安装Aladdin插件, 安装详情可参考安装Aladdin。
实验步骤(单机单卡)
- 用户可参看单机单卡微调示例/准备工作章节完成下载模型、LLaMA Factory准备、下载数据集工作。
- 可视化工具选择“SwanLab”,准备工作可参考“可视化工具/SwanLab”,获取SwanLab的API Key并添加安装SwanLab的命令行,如下图高亮①所示。
- /dev/shm
- 大容量存储
-
在
start.sh文件页面保留下图高亮②所示的命令,将模型和数据集上传到/dev/shm目录。后续操作步骤可参看单机单卡微调示例/操作步骤(SwanLab),在操作过程中统计模型加载耗时、数据集加载耗时及整体微调耗时。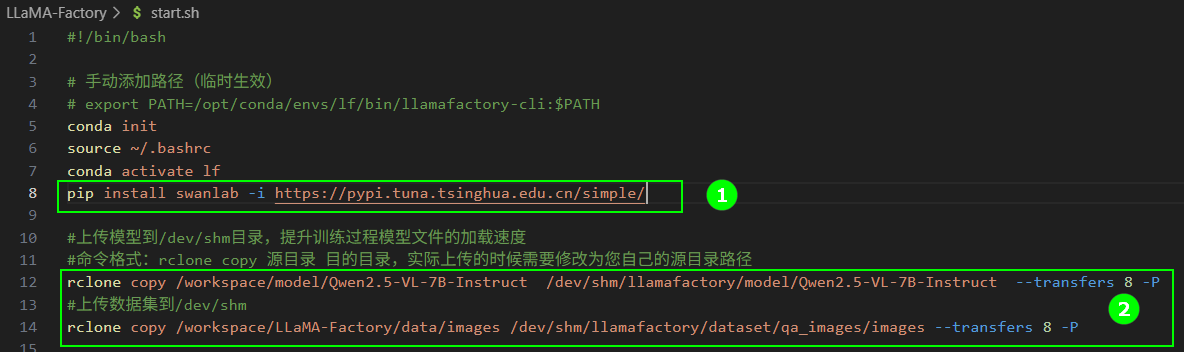
rclone copy /workspace/model/Qwen2.5-VL-7B-Instruct /dev/shm/llamafactory/model/Qwen2.5-VL-7B-Instruct --transfers 8 -P
rclone copy /workspace/LLaMA-Factory/data/images /dev/shm/llamafactory/dataset/qa_images/images --transfers 8 -P -
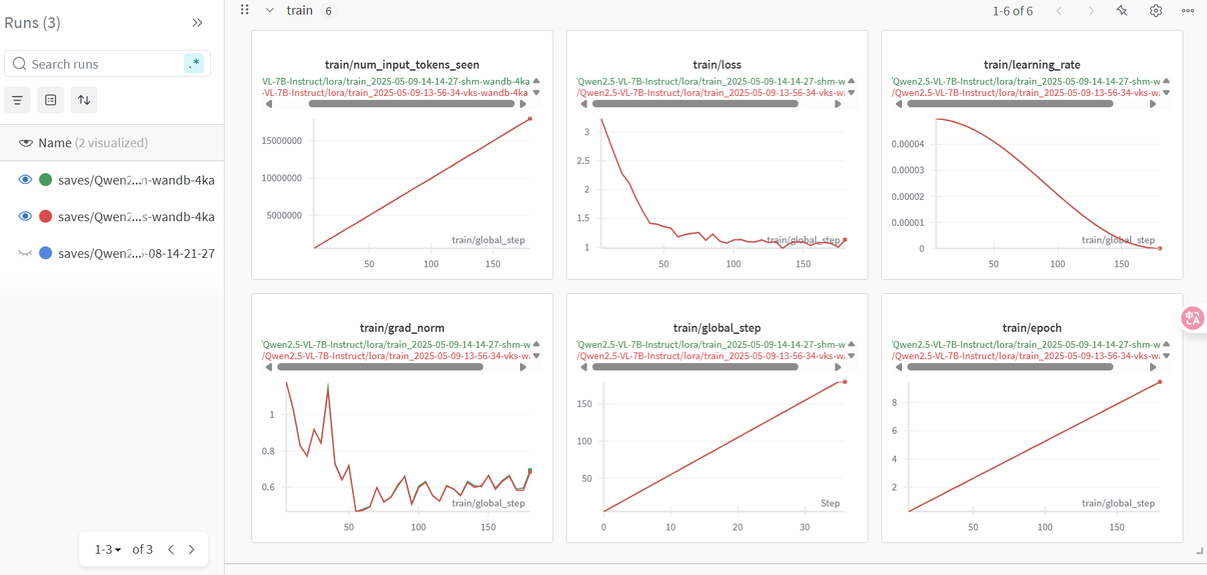
用户可通过SwanLab观察Train标签下的监控图表,涉及图表有:loss,learning_rate等,示例页面如下图所示。
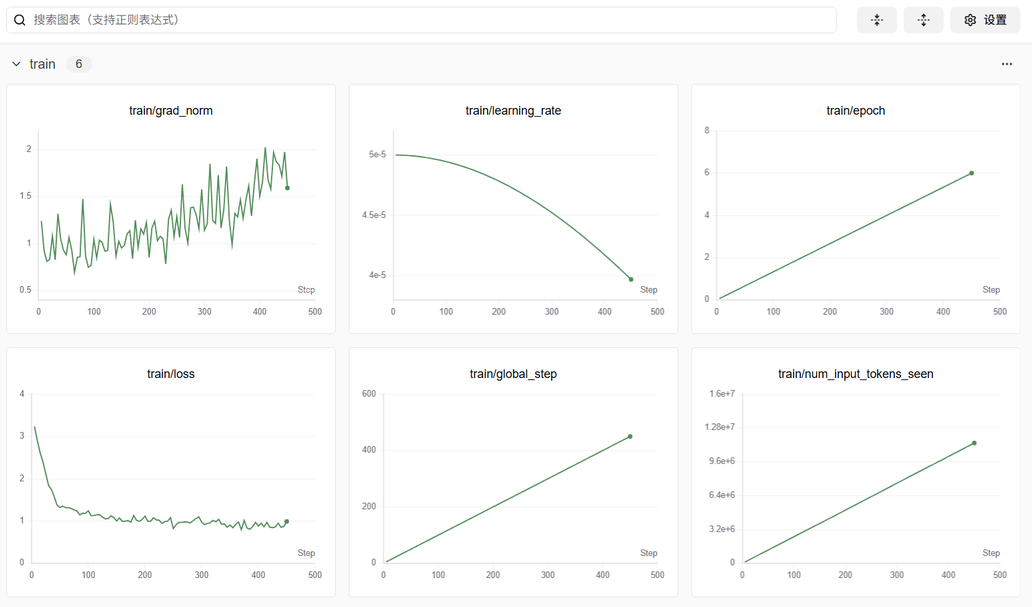
-
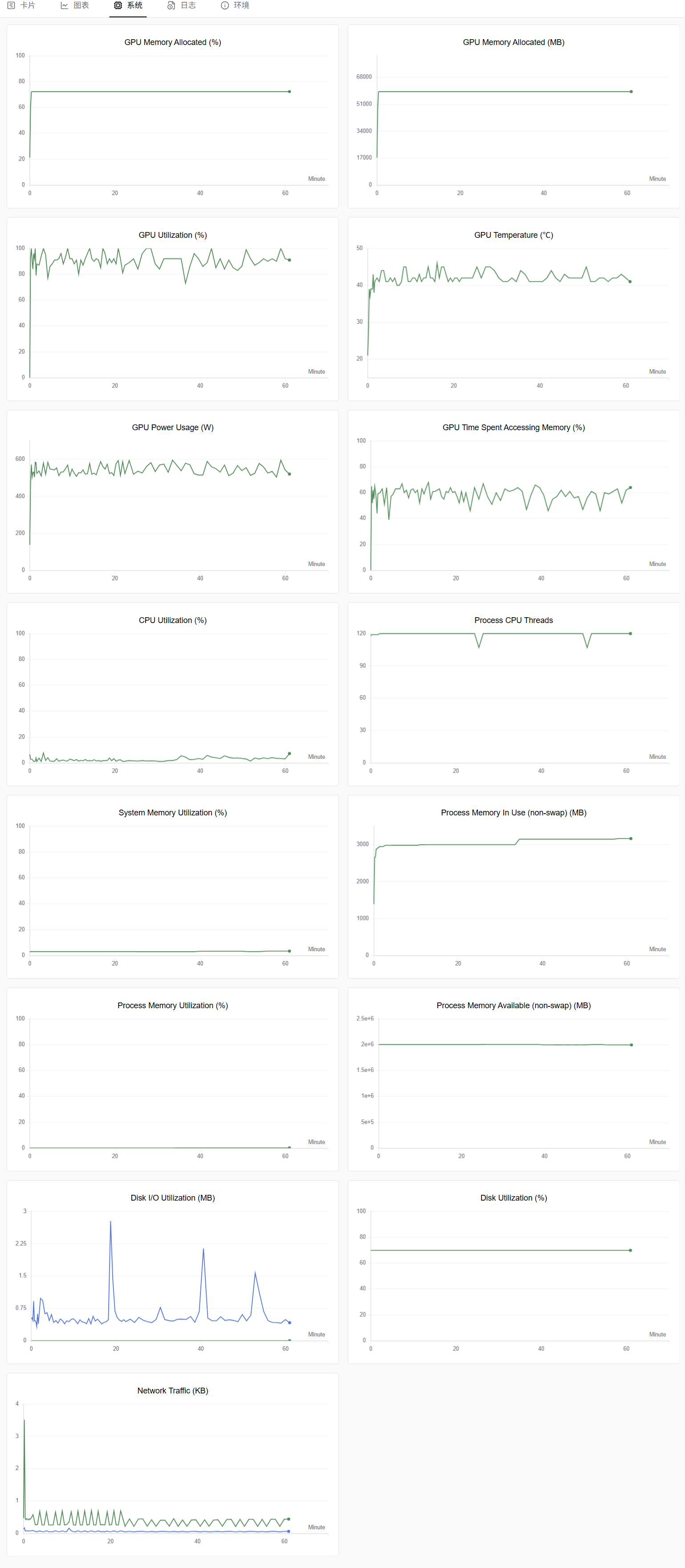
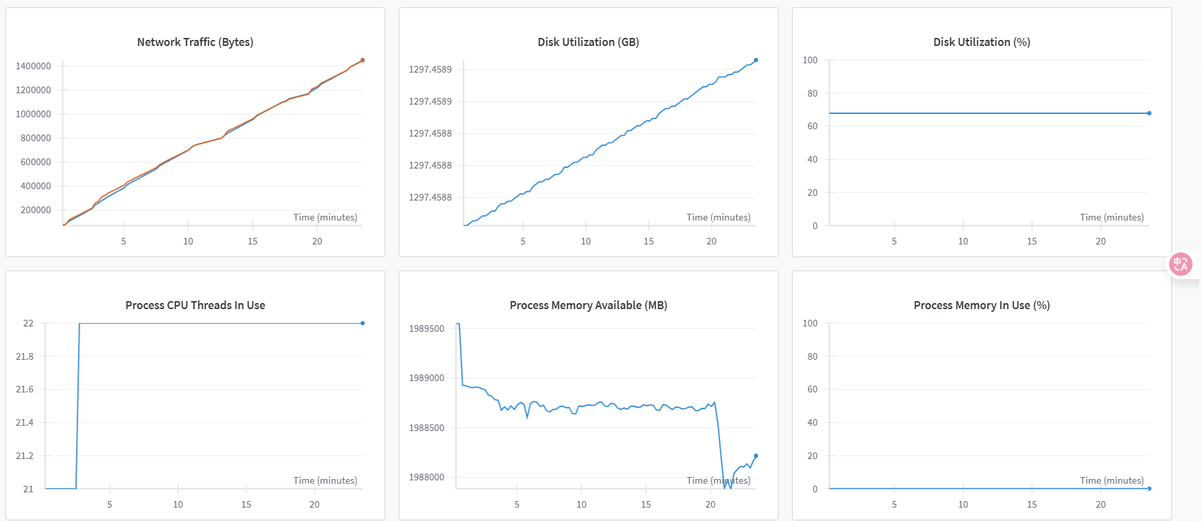
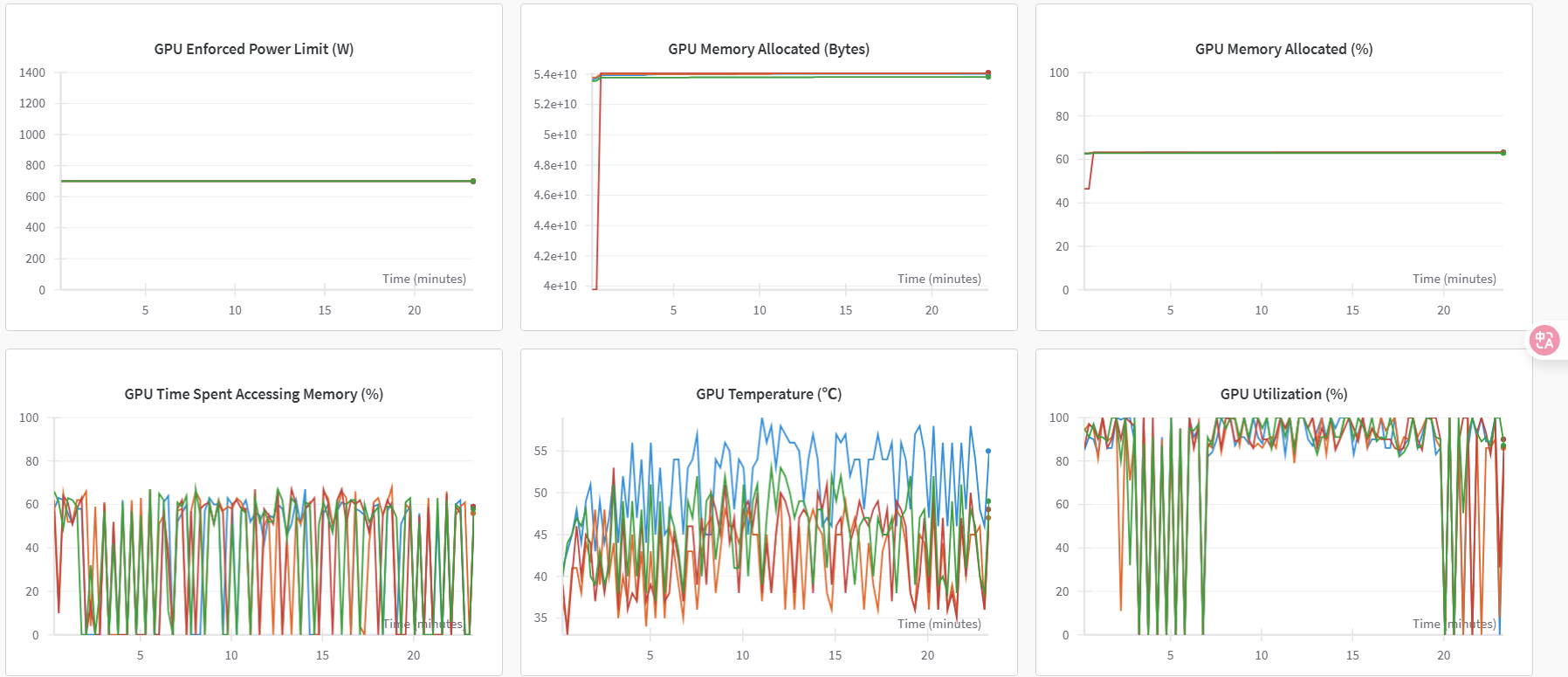
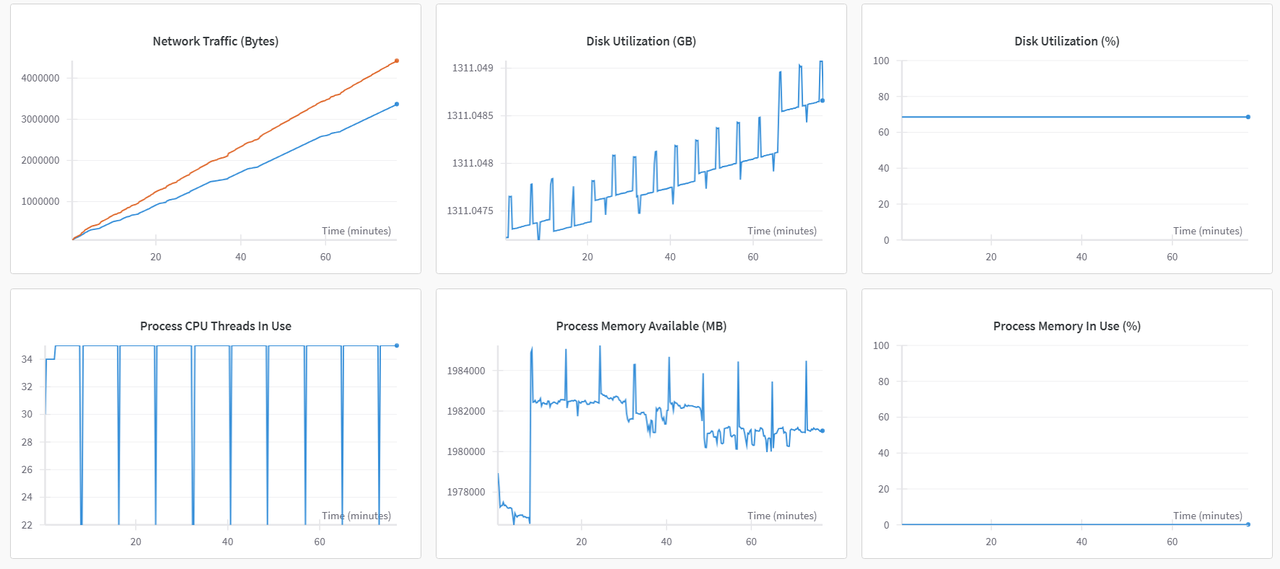
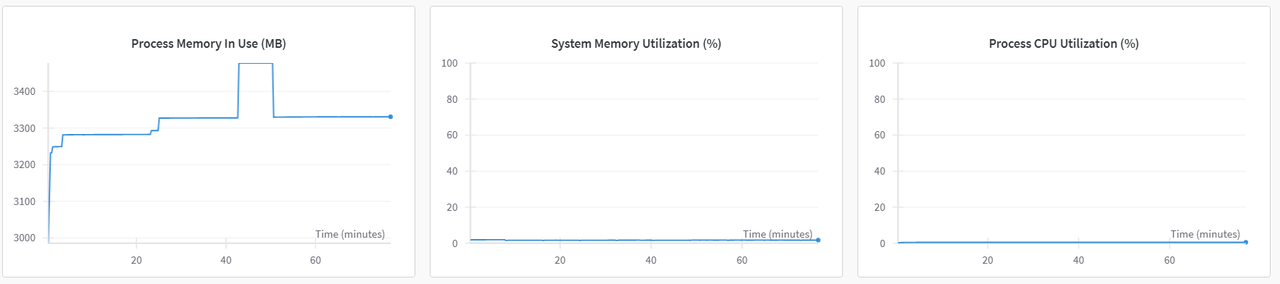
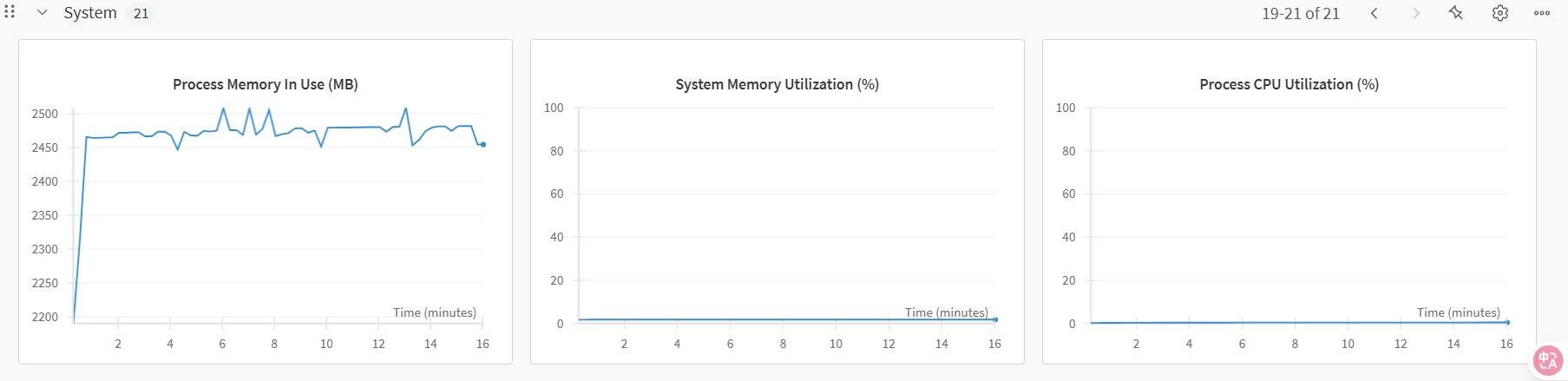
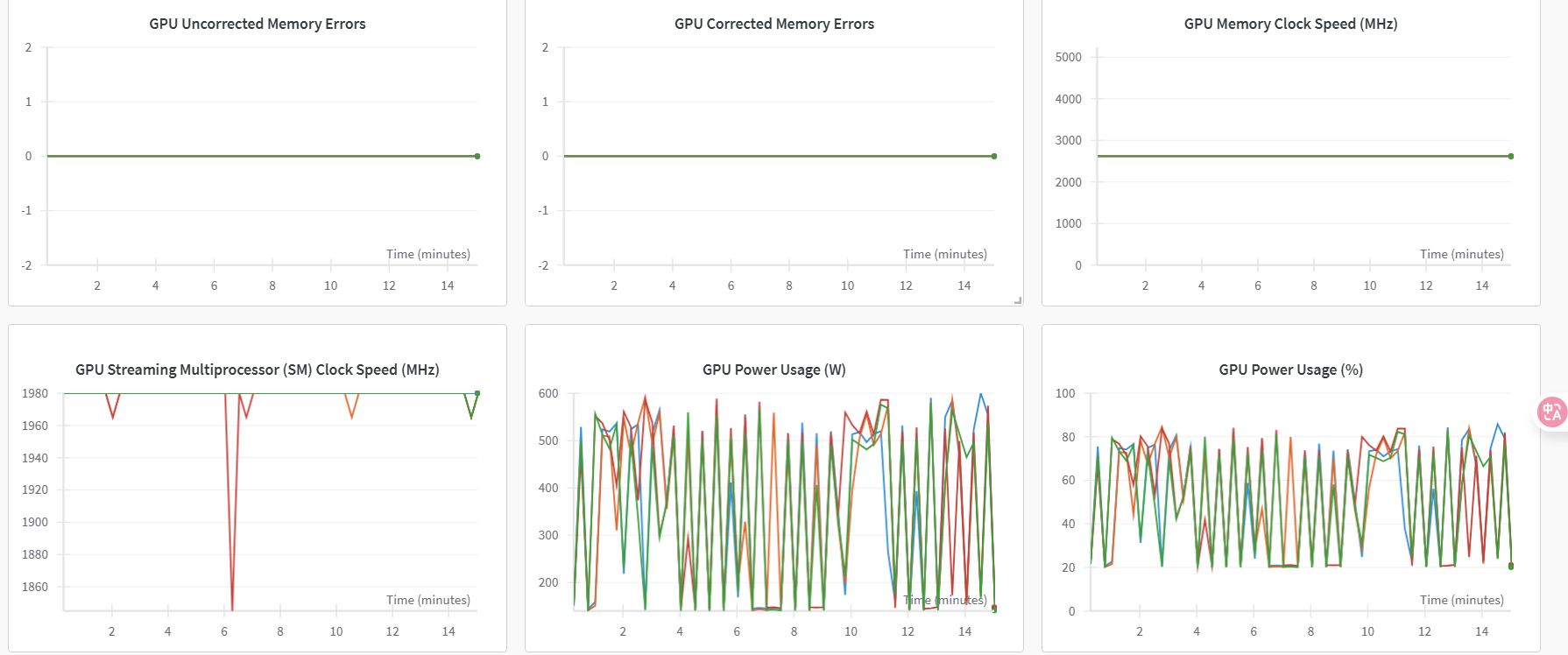
切换至“系统”监控图表,可查看各类资源利用率图表,例如:GPU Memory Allocated(%)、GPU Memory Allocated(MB)、GPU Utilization(%)、CPU Utilization(%)等,示例如下图所示。
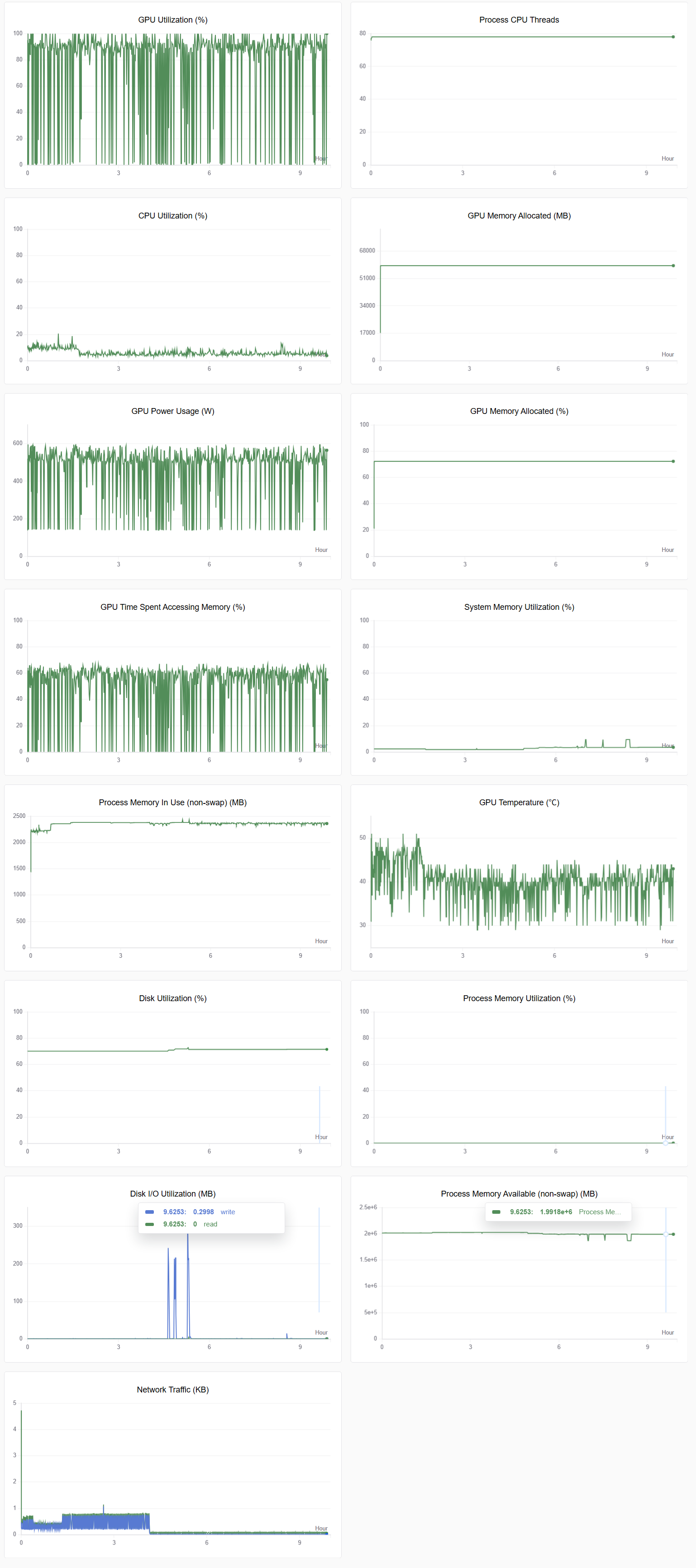
-
如果用户在LLaMA Factory源码文件该路径(
/src/llamafactory/webui/runner.py)下,在下图高亮的代码之间添加dataloader num workers=12并保存。然后重新执行单机单卡微调示例/操作步骤(SwanLab)。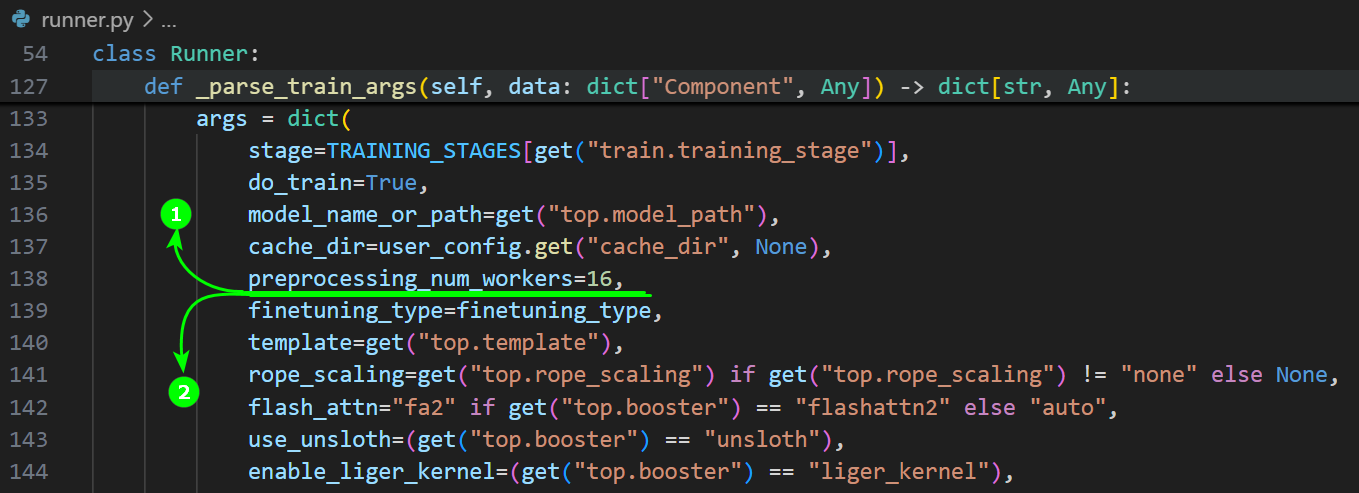
-
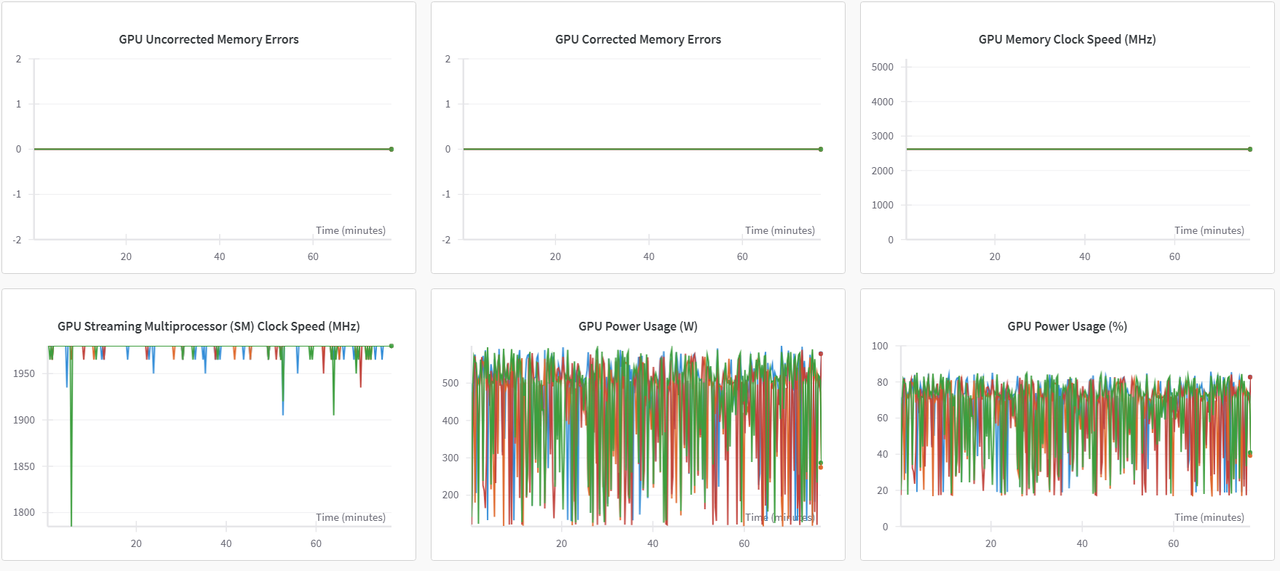
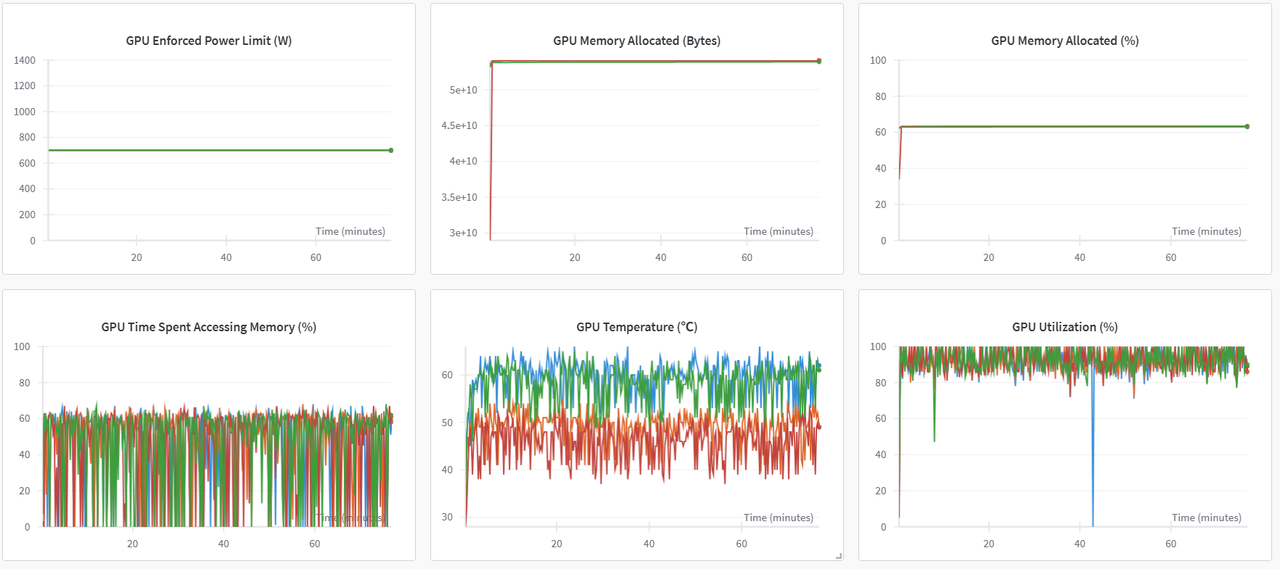
SwanLab切换至“系统”监控图表,可查看各类资源利用率图表,示例如下图所示。同时在操作过程中统计模型加载耗时、数据集加载耗时及整体微调耗时。
结论一
从步骤5、步骤7的系统监控图表中可以看出,在单机单卡示例中将dataloader_num_workers=12设置为CPU核心数减1,例如:用户在final.sh启动文件执行Run Shell时GPU资源为:13C 200G 1GPU,则设置dataloader_num_workers的值为12。可以有效提高使用GPU训练时的利用率。
-
在
start.sh文件页面移除下图高亮②所示的命令,将模型和数据集保存到大容量存储。后续操作步骤可参看单机单卡微调示例/操作步骤(SwanLab),在操作过程中统计模型加载耗时、数据集加载耗时及整体微调耗时。 -
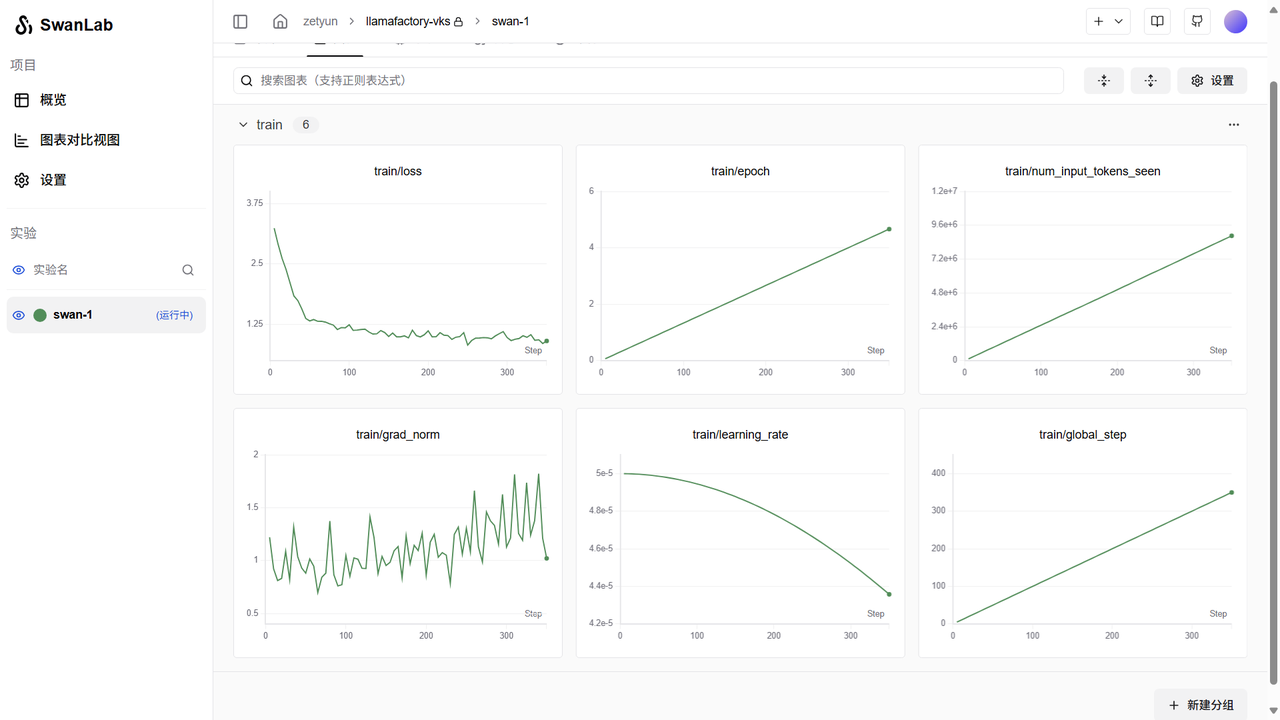
用户可通过SwanLab观察“Train”标签下的监控图表,涉及图表有:loss,learning_rate等,示例页面如下图所示。
- 切换至“系统”监控图表,可查看各类资源利用率图表,例如:GPU Memory Allocated(%)、GPU Memory Allocated(MB)、GPU Utilization(%)、CPU Utilization(%)等,示例如下图所示。
-
如果用户在LLaMA Factory源码文件该路径(
/src/llamafactory/webui/runner.py)下,在下图高亮的代码之间添加dataloader num workers=12并保存。然后重新执行单机单卡微调示例/操作步骤(SwanLab)。 -
SwanLab切换至“系统”监控图表,可查看各类资源利用率图表,示例如下图所示。同时在操作过程中统计模型加载耗时、数据集加载耗时及整体微调耗时。
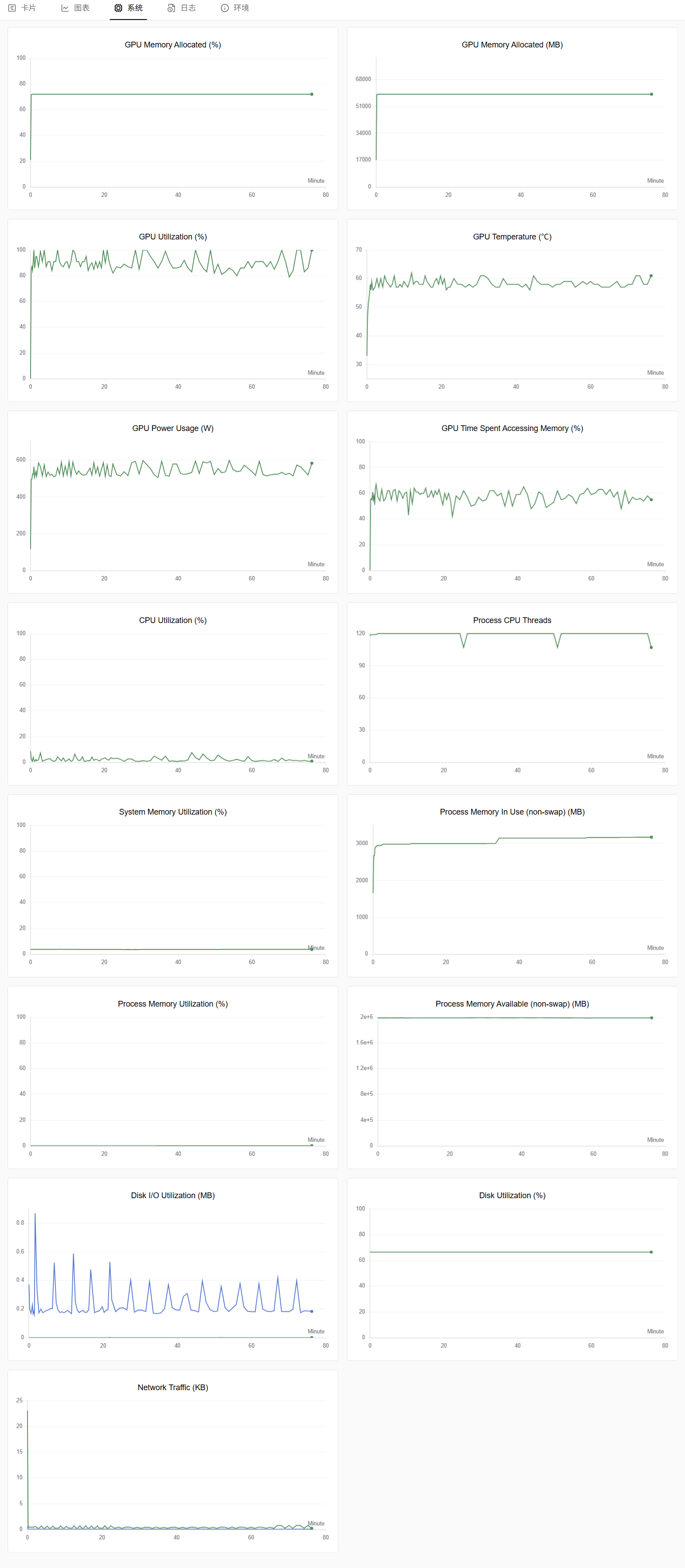
基于上述操作获取的模型加载耗时、数据集加载耗时及整体微调耗时,详细的数据如下表所示。
| 配置项 | dev/shm(100G) | 大容量存储 |
|---|---|---|
| epoch | 10 | 10 |
| 数据集 | 2000+多模态图片数据(1928×1208) | 2000+多模态图片数据(1928×1208) |
| 微调方式 | LoRA | LoRA |
| batchsize | 2 | 2 |
| 数据加载耗时/batchsize | 1.42s | 1.64s |
| 模型加载耗时(模型大小16G) | 6.77s | 72.05s |
| 微调耗时 | 4:10:22 | 4:27:23 |
弹性容器集群中,单张卡提供的内存大小为200GB,通过Aladdin使用时,dev/shm默认最大为内存的一半大小,即100GB。/dev/shm是tmpfs文件系统的一个实例,具有非常快的读写速度。
结论二
实验对比显示,在数据量小于100GB的场景下,使用/dev/shm进行单batch数据加载的效率提升了13%;而在模型加载速度方面,则达到了传统存储方式的约10倍。整体微调过程的训练耗时也因此减少了约17分钟。
由此可见,在数据量小于100GB的大模型微调任务中,将数据集和模型存储于/dev/shm中能够显著提升训练效率。因此,推荐采用该方式以实现更优的性能表现。
实验步骤(单机多卡)
- 用户可参看单机多卡微调示例/准备工作章节完成下载模型、LLaMA Factory准备、下载数据集工作。
- /dev/shm
- 大容量存储
- 解压脚本文件,在
start.sh文件页面配置可视化工具配置“WanDB”,脚本如下所示,脚本位置如下图高亮①所示;保留下图高亮②所示的命令,将模型和数据集上传到/dev/shm目录。
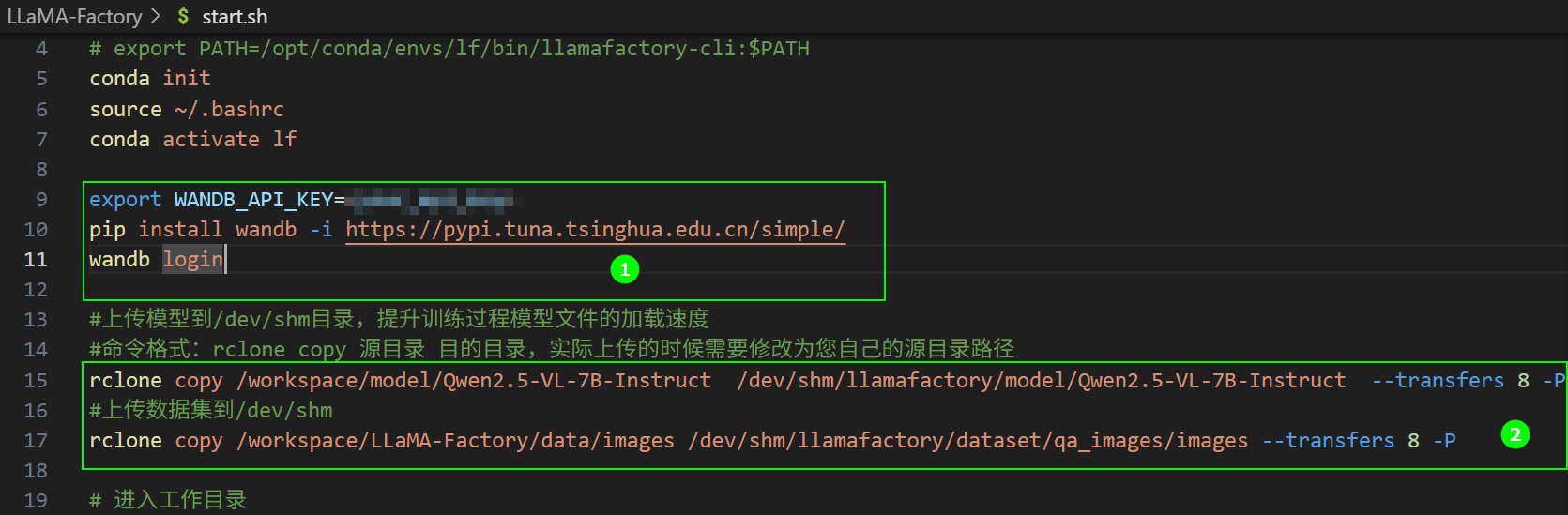
export WANDB_API_KEY=<your_api_key>
pip install wandb -i https://pypi.tuna.tsinghua.edu.cn/simple/
wandb login
-
在
final.sh文件编辑界面中,右键点击页面的空白处,在弹窗菜单中选择“Run Shell”,如下图所示,在参数配置页面配置环境、资源等参数,其中资源配置(52C 800G 4GPU),点击展开“Advanced”配置,点击“Add External Access”,新增一个端口为7860的外部访问。
-
参数配置完成后,单击“Submit”按钮,即可开始模型微调,在微调过程中统计模型加载耗时、数据集加载耗时及整体微调耗时。
-
用户可通过WanDB观察Train下的监控图表,涉及图表有:loss,learning_rate等,示例页面如下图所示。
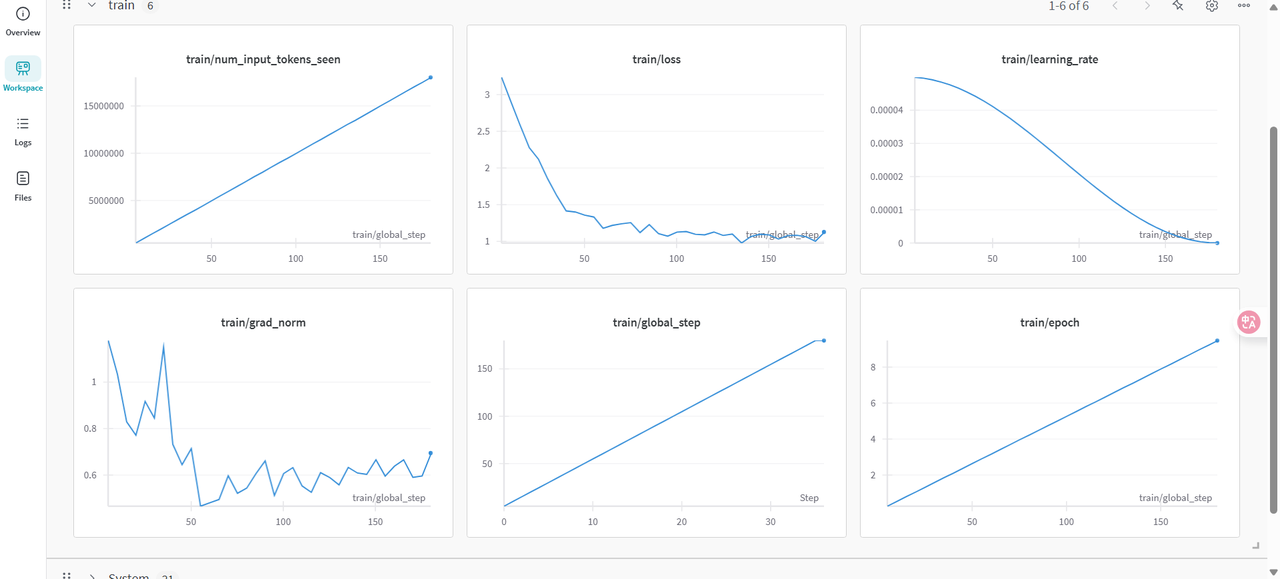
-
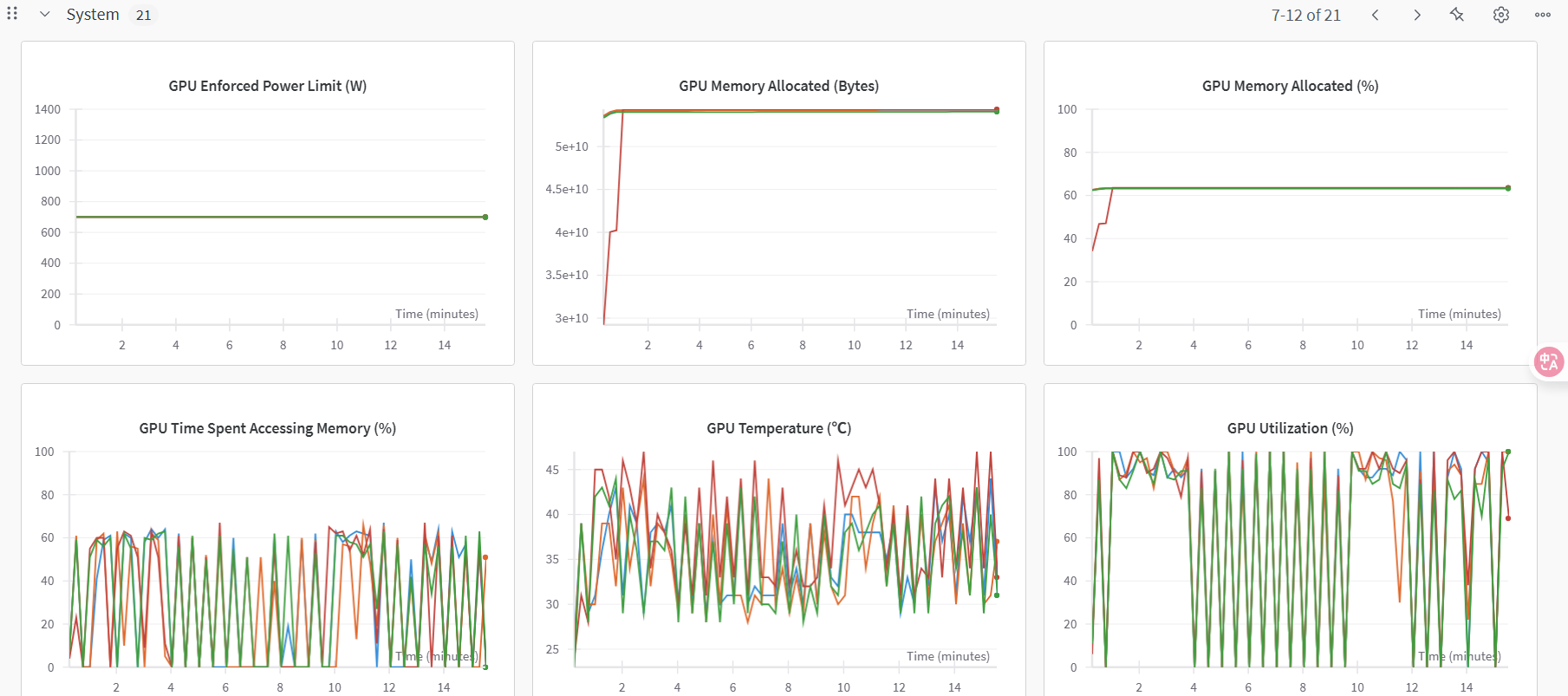
切换至“系统”监控图表,可查看各类资源利用率图表,例如:GPU Memory Allocated(%)、GPU Memory Allocated(MB)、GPU Utilization(%)、CPU Utilization(%)等,示例如下图所示。
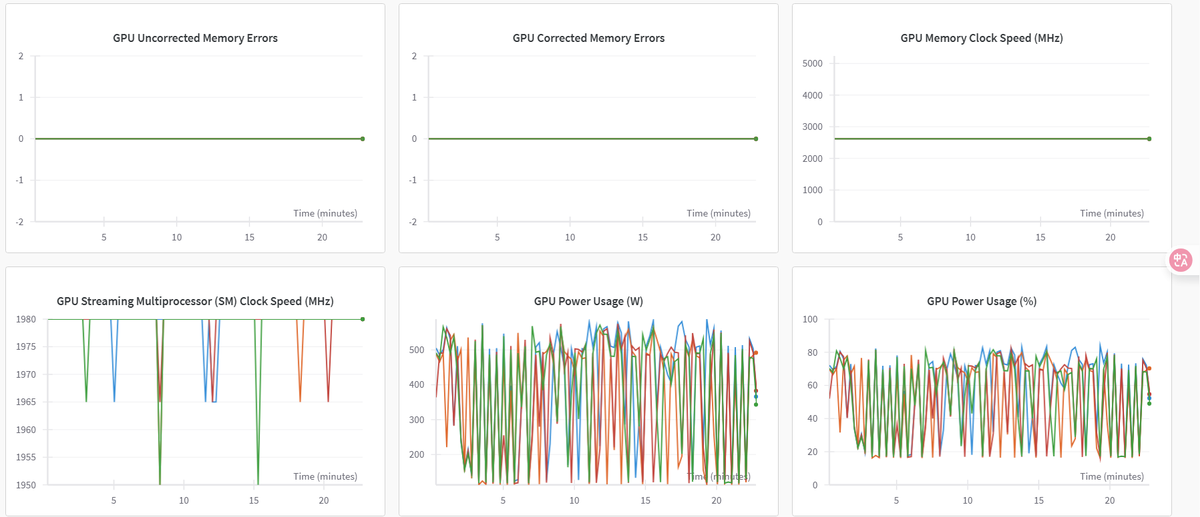

-
如果用户在LLaMA Factory源码文件该路径(
/src/llamafactory/webui/runner.py)下,在下图高亮的代码之间添加dataloader num workers=51并保存。然后重新执行单机多卡微调示例/操作步骤(WanDB)。 -
WanDB切换至“系统”监控图表,可查看各类资源利用率图表,示例如下图所示。同时在操作过程中统计模型加载耗时、数据集加载耗时及整体微调耗时。
使用WanDB时,请用户根据实际需求合理配置网络环境,以保障服务的稳定性与性能。
结论一
从步骤6、步骤8的系统监控图表中可以看出,在单机多卡示例中将dataloader_num_workers=51设置为CPU核心数减1,例如:用户在final.sh启动文件执行Run Shell时GPU资源为:52C 800G 4GPU,则设置dataloader_num_workers的值为51。可以有效提高使用GPU训练时的利用率。
-
在
start.sh文件页面移除下图高亮②所示的命令,将模型和数据集保存到大容量存储。后续操作步骤可参看单机多卡微调示例/操作步骤(WanDB),在操作过程中统计模型加载耗时、数据集加载耗时及整体微调耗时。 -
用户可通过SwanLab观察“Train”标签下的监控图表,涉及图表有:loss,learning_rate等,示例页面如下图所示。
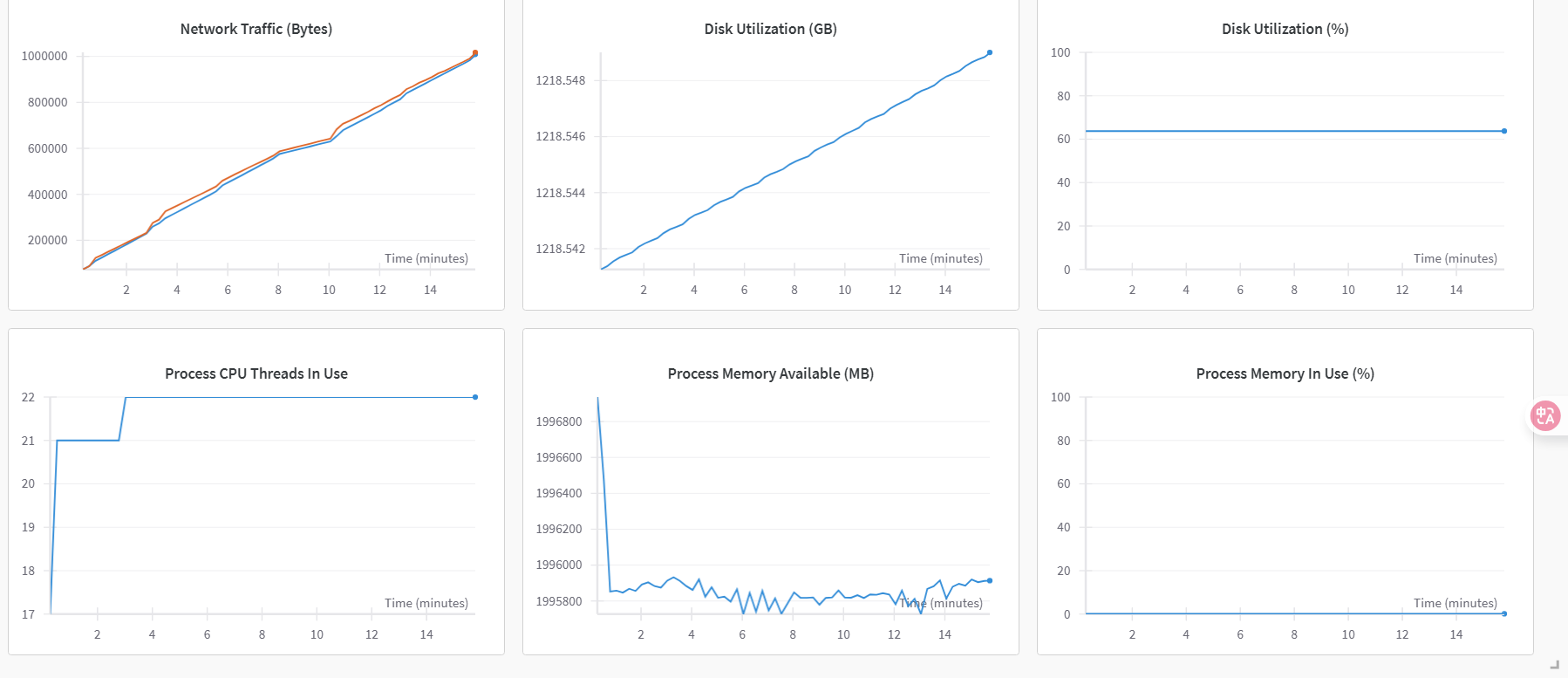
- 切换至“系统”监控图表,可查看各类资源利用率图表,例如:GPU Memory Allocated(%)、GPU Memory Allocated(MB)、GPU Utilization(%)、CPU Utilization(%)等,部分示例如下图所示。
-
如果用户在LLaMA Factory源码文件该路径(
/src/llamafactory/webui/runner.py)下,在下图高亮的代码之间添加dataloader num workers=52并保存。然后重新执行单机多卡微调示例/操作步骤(WanDB)。 -
WanDB切换至“系统”监控图表,可查看各类资源利用率图表,示例如下图所示。同时在操作过程中统计模型加载耗时、数据集加载耗时及整体微调耗时。
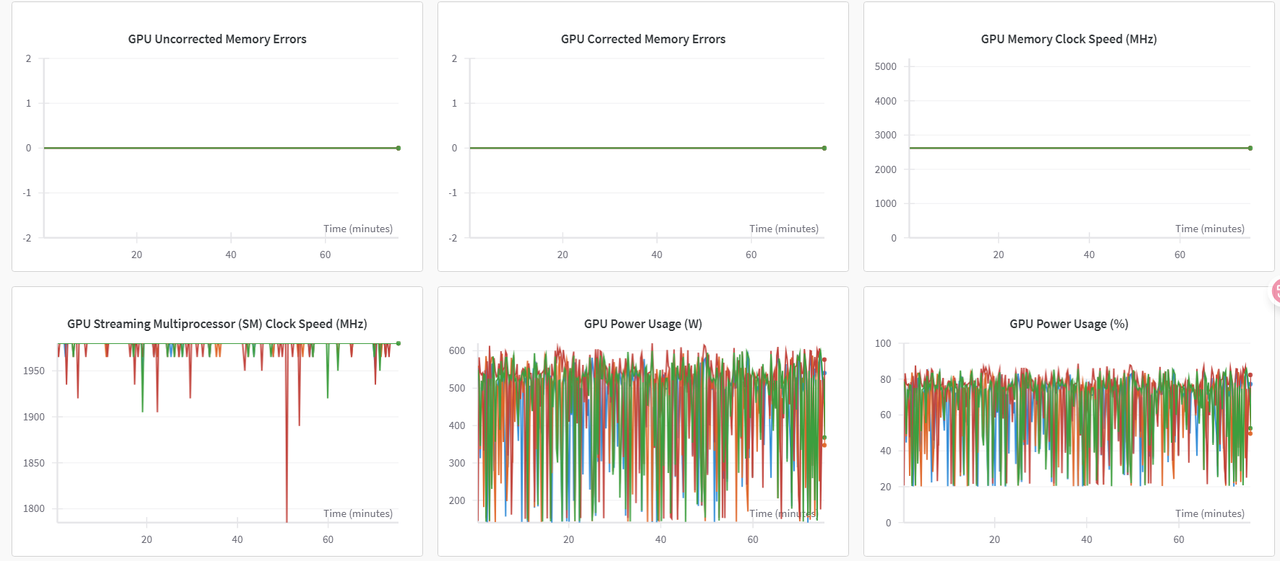
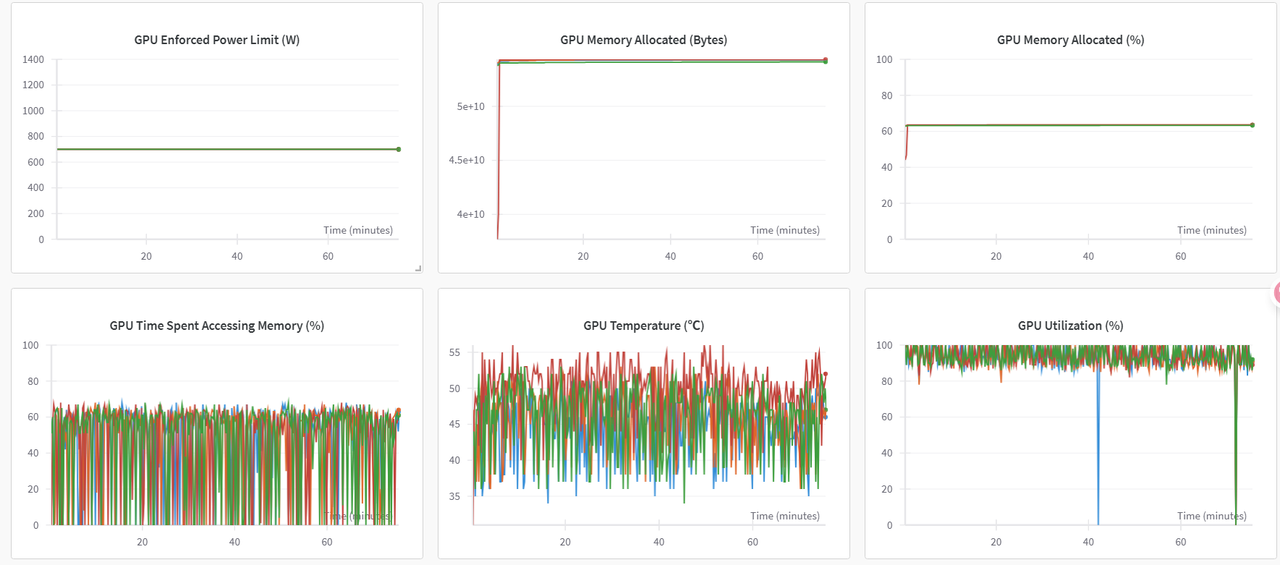
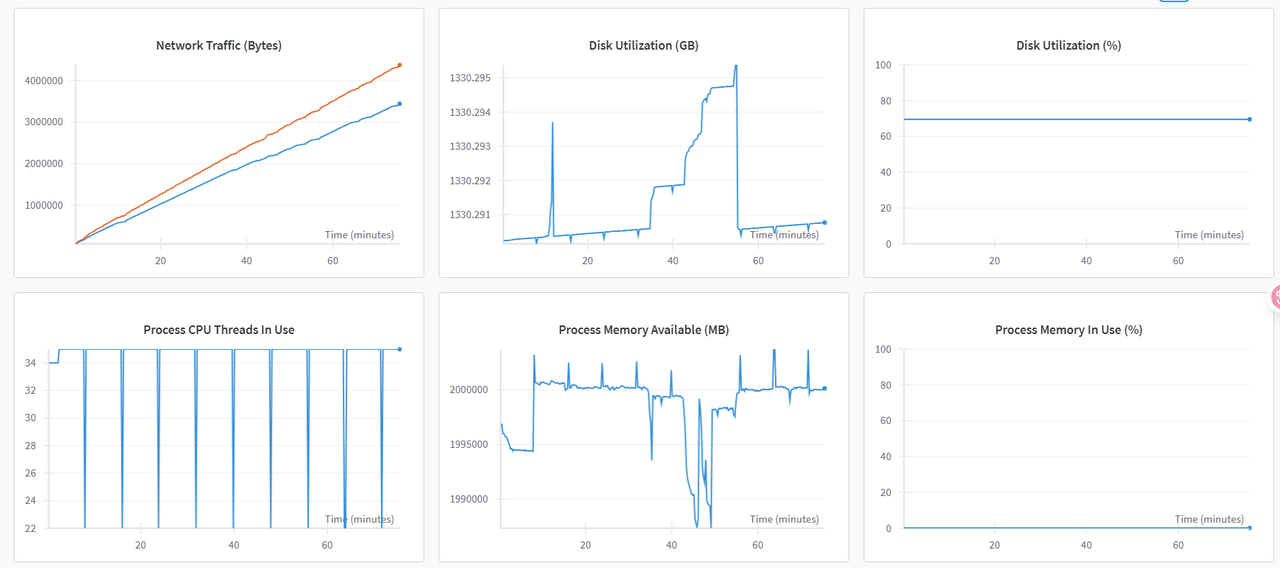
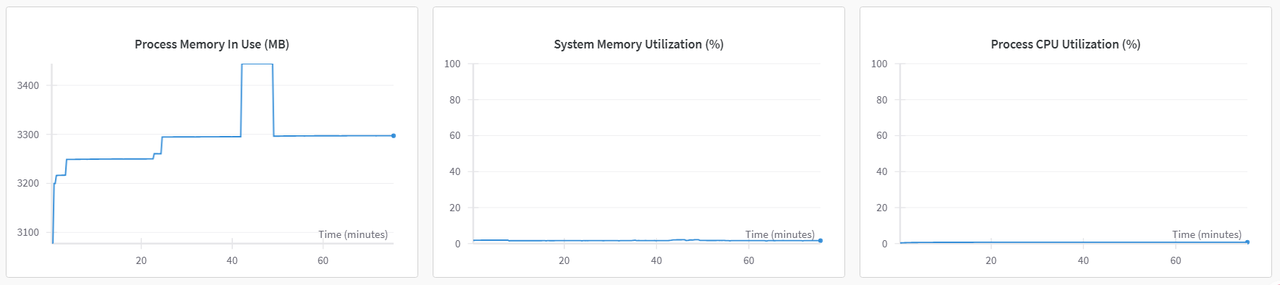
WanDB提供了不同项目的相同指标对比的功能,通过对比图可以直观看出使用不同存储时对微调的影响。(*绿色曲线代表使用dev/shm,红色曲线代表使用大容量存储)
Train标签页图表对比图,示例如下所示。
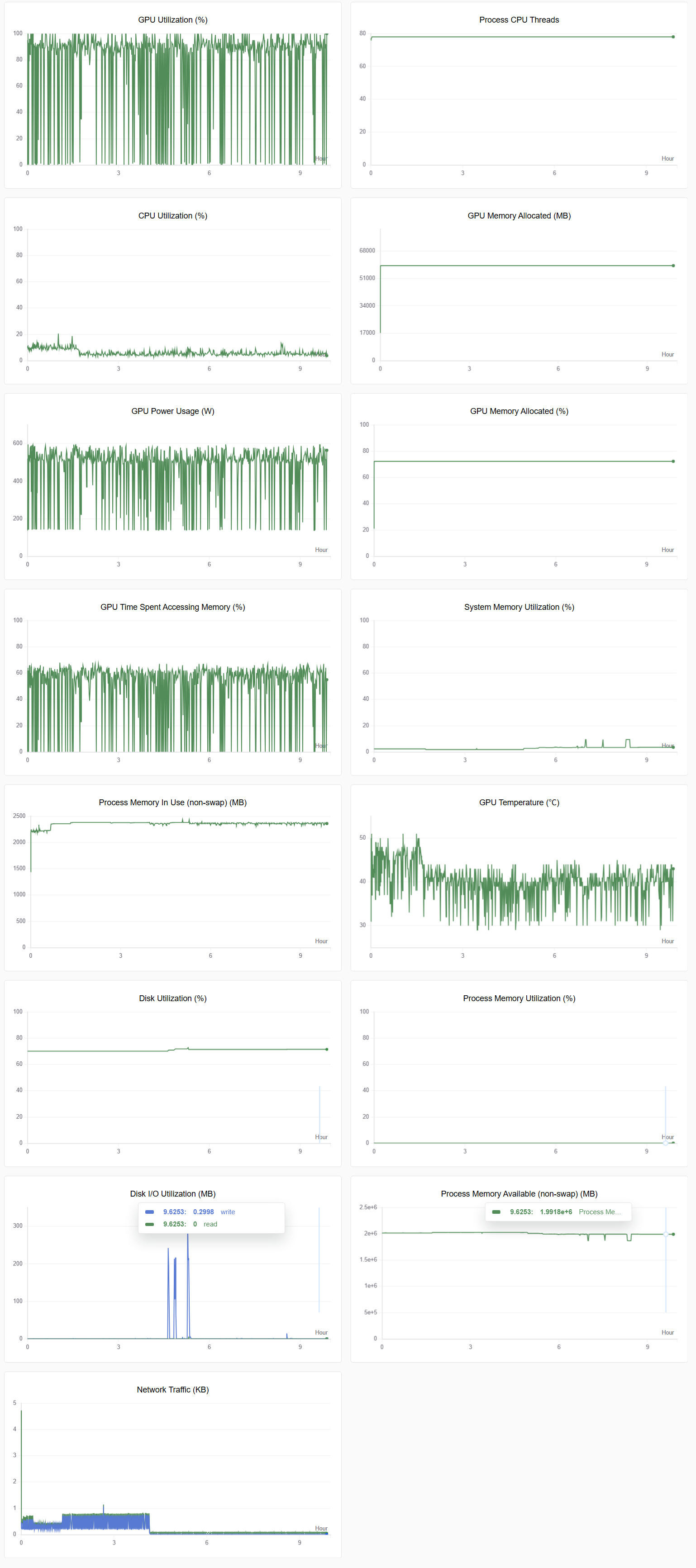
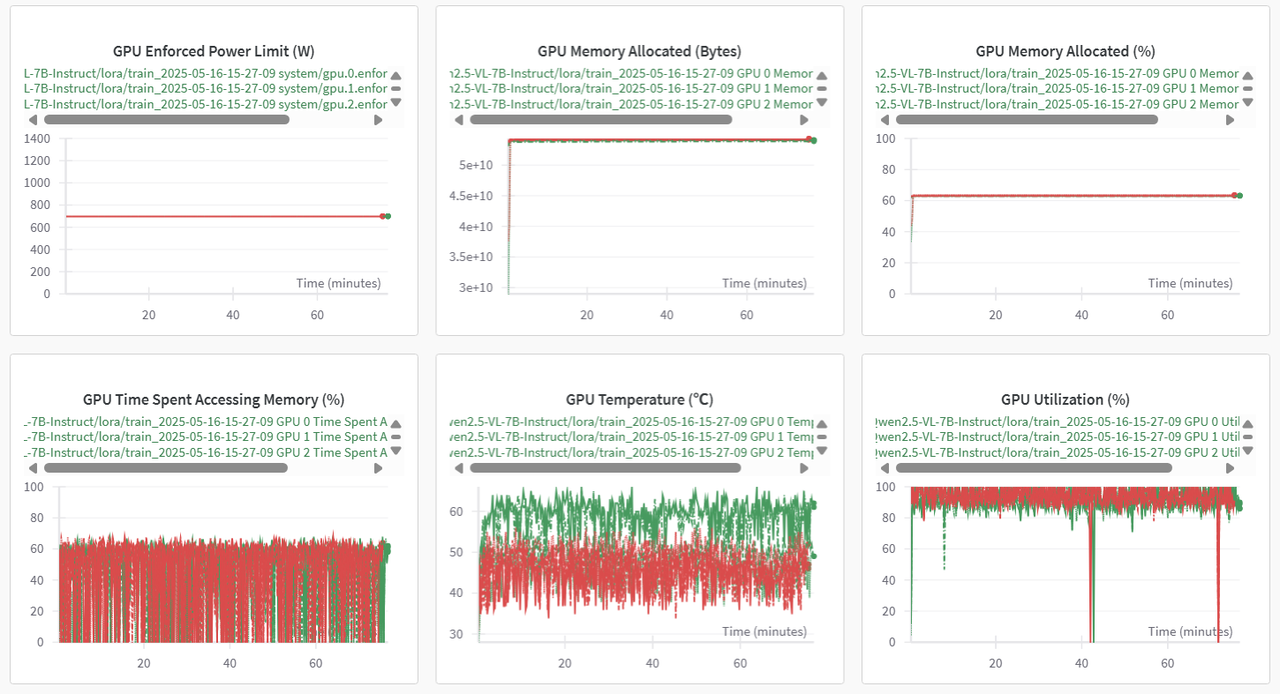
系统GPU和CPU相关指标对比图示例如下图所示。

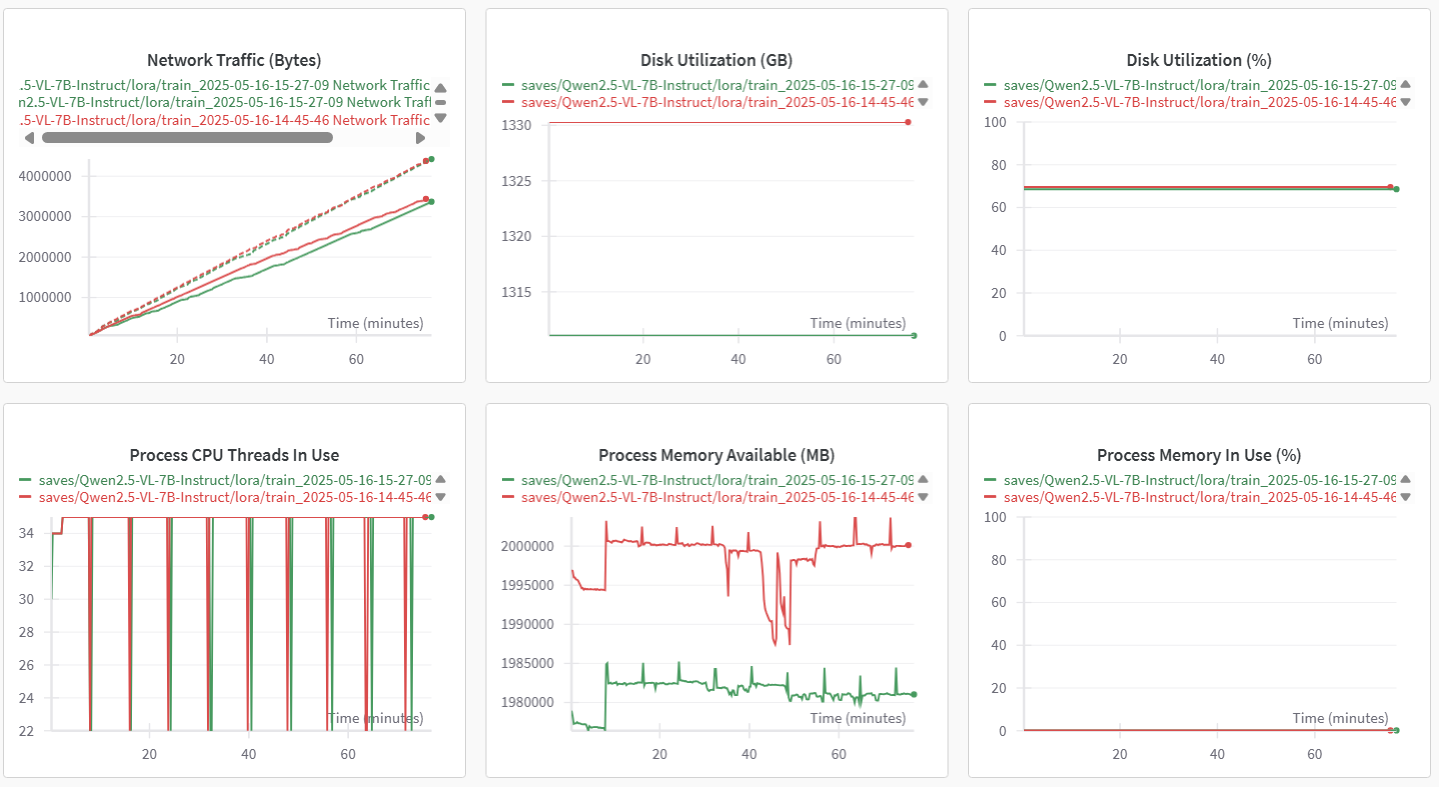
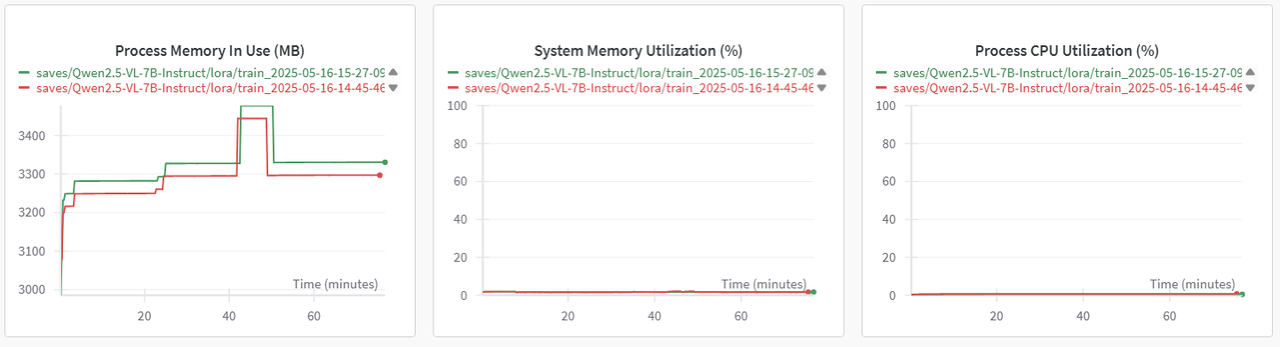
基于上述操作获取的模型加载耗时、数据集加载耗时及整体微调耗时,详细的数据如下表所示。
| 配置项 | dev/shm(100G) | 大容量存储 |
|---|---|---|
| epoch | 10 | 10 |
| 数据集 | 2000+多模态图片数据(1928×1208) | 2000+多模态图片数据(1928×1208) |
| 微调方式 | LoRA | LoRA |
| batchsize | 2 | 2 |
| 数据集加载平均耗时/batch(大小约6M) | 9.53s | 1min41s |
| 模型加载平均耗时(模型约16G) | 5.75s/batch | 6.5s/batch |
| 微调耗时 | 1:07:38 | 1:16:44 |
结论二
实验对比显示,在数据量小于100GB的场景下,在dev/shm下进行模型加载的速度大约是大容量存储的15倍,数据集的加载速度也有所提升。微调耗时也缩减了约10分钟(本次实验)。总体来看,dev/shm在性能上显著优于大容量存储。
由此可见,在数据量小于100GB的大模型微调任务中,将数据集和模型存储于/dev/shm中能够显著提升训练效率。因此,推荐采用该方式以实现更优的性能表现。
总结
通过对比单机单卡与单机多卡的实验数据可以看出,在模型和数据集大小不超过100GB的情况下,将数据集和模型存储在/dev/shm中可以显著提高训练效率,能够有效减少微调所需的时间。因此,在实际应用中推荐用户在处理小于100GB的数据量,将数据存入/dev/shm的方式,以提升整体训练效率。