弹性容器集群
1.1、弹性容器集群是否是启动就开始计费,有没有无卡启动模式?
解决方案:集群启动后,只有 存储 会消耗少量的算力,集群本身并不会消耗算力;只有启动服务时,配置了GPU,才会产生GPU的算力消耗。
1.2、安装Kubernestes客户端工具kubectl后,打开Kubernestes客户端工具,会出现下面的界面,并且一会就自动关闭了。

解决方案:Kubernestes客户端工具不是直接双击运行的,您下载kubectl.exe后,需要配置环境变量,然后打开cmd,在cmd中运行
1.3、需要先部署一个docker环境,上传数据时,无卡怎么开实例呢?
解决方案:在弹性容器集群中启动一个pod,挂载pvc,不配置gpu数量即可。
可参考下方链接文章附件中的prepare.yaml:https://mp.weixin.qq.com/s/jfidImiOWVUGUCsZZDJsEg
弹性容器集群的使用可参考:https://docs.alayanew.com/docs/documents/useGuide/Vcluster/start
1.4、如何使用k8s呢?
解决方案:请参考k8s的官网文档
1.5、弹性容器集群是否支持外部访问web服务,如何配置开放端口呢?
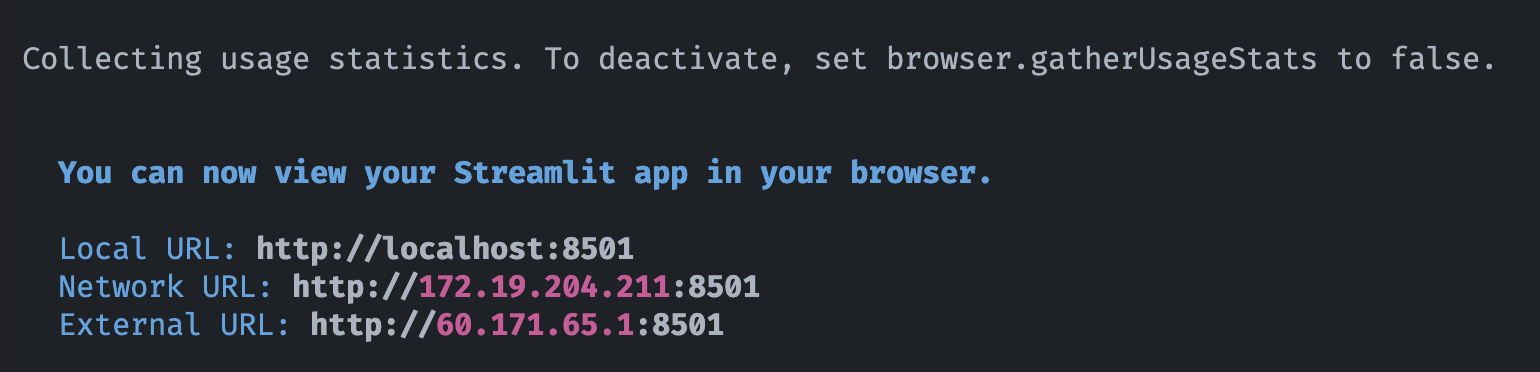
解决方案:支持外部访问web服务,可创建serviceExporter,如下:
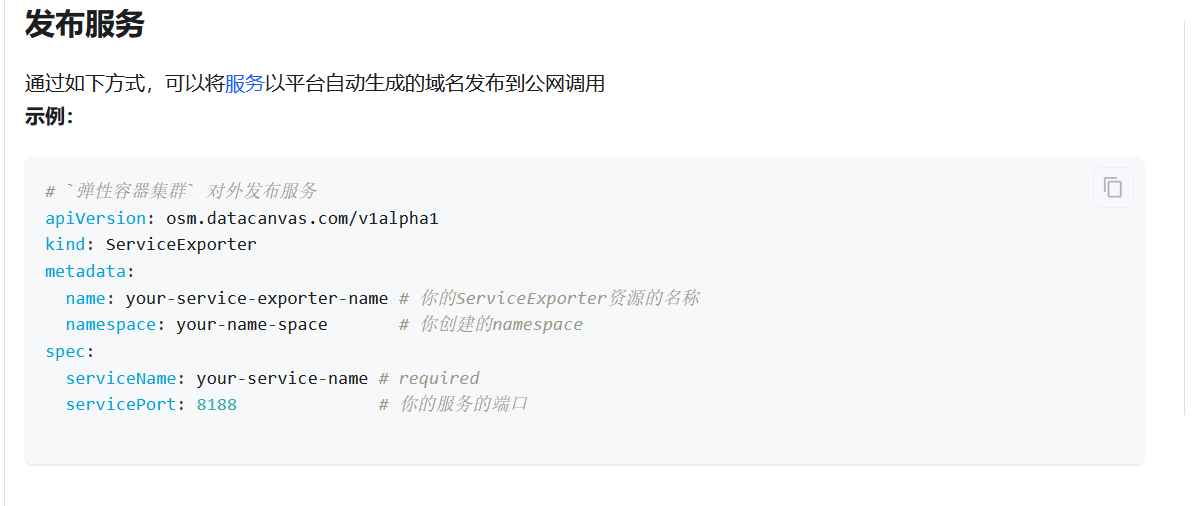
参考:https://docs.alayanew.com/docs/documents/useGuide/Vcluster/publishService