大语言模型(LLM)推理
您可以通过阅读本文,快速了解如何在Inference平台上对LLM大语言模型进行推理。
快速体验大模型上线
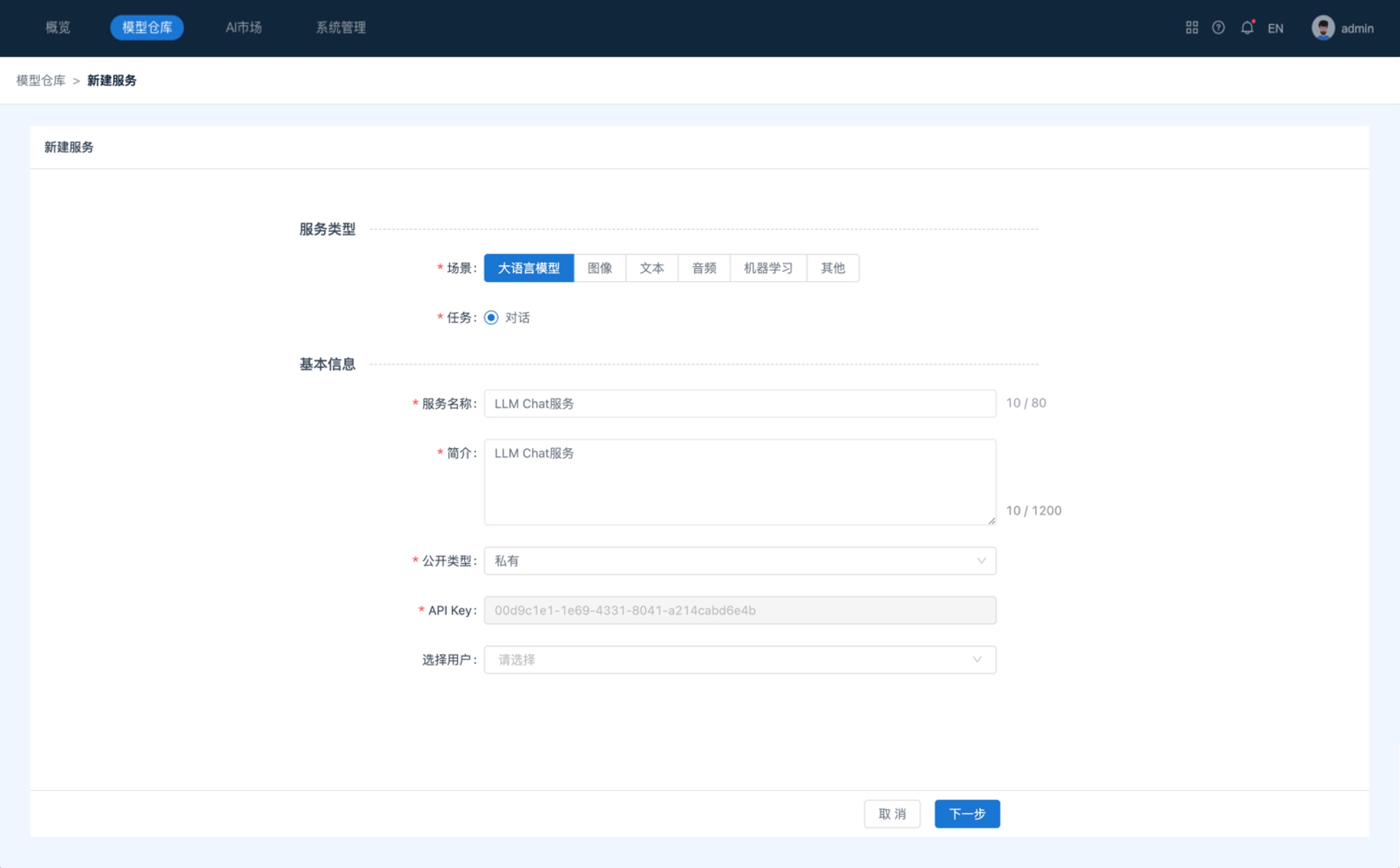
- 点击菜单“Tools”,选择Inference并进入。进入后,点击“模型仓库”,进入服务管理主界面。点击页面右上角的“新建服务”按钮,可进入新建服务页面。在新建服务页面中,选择场景为大语言模型,并填写相关信息以完成LLM大语言服务的创建。
- 服务创建成功,系统会跳转到LLM大语言服务概览页面。通过点击侧边栏的“模型管理”进入模型管理列表页面。点击“添加模型 ”-> “模型导入”,进入模型导入页面中,选择导入方式为“数据源-FTP”,填写相关信息以完成模型导入。
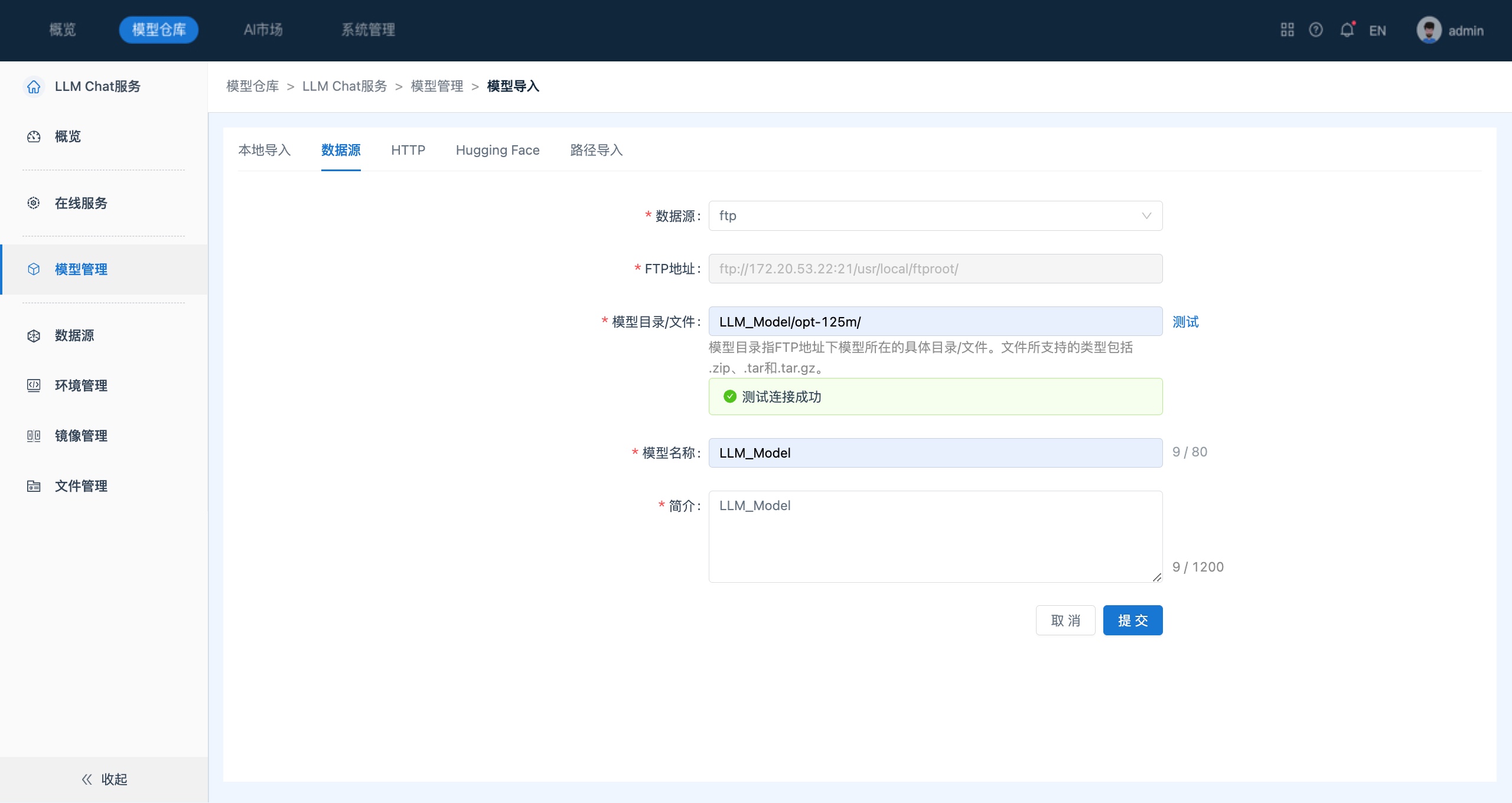
【说明】
- 用户需先在数据源中与FTP地址连接
- Inference支持多种大模型导入方式,包括从FTP、对象存储等外部存储系统、HTTP方式、开源社区Hugging Face等方式下载,本地上传大模型,以及从AI Market添加的大模型。
- 模型导入成功并通过审核后即可用于在线服务。通过点击侧边栏的“在线服务”进入在线服务列表页面。点击“新建部署”按钮,进入新建部署页面,选择需部署的模型,配置模型精度和资源以完成模型部署。
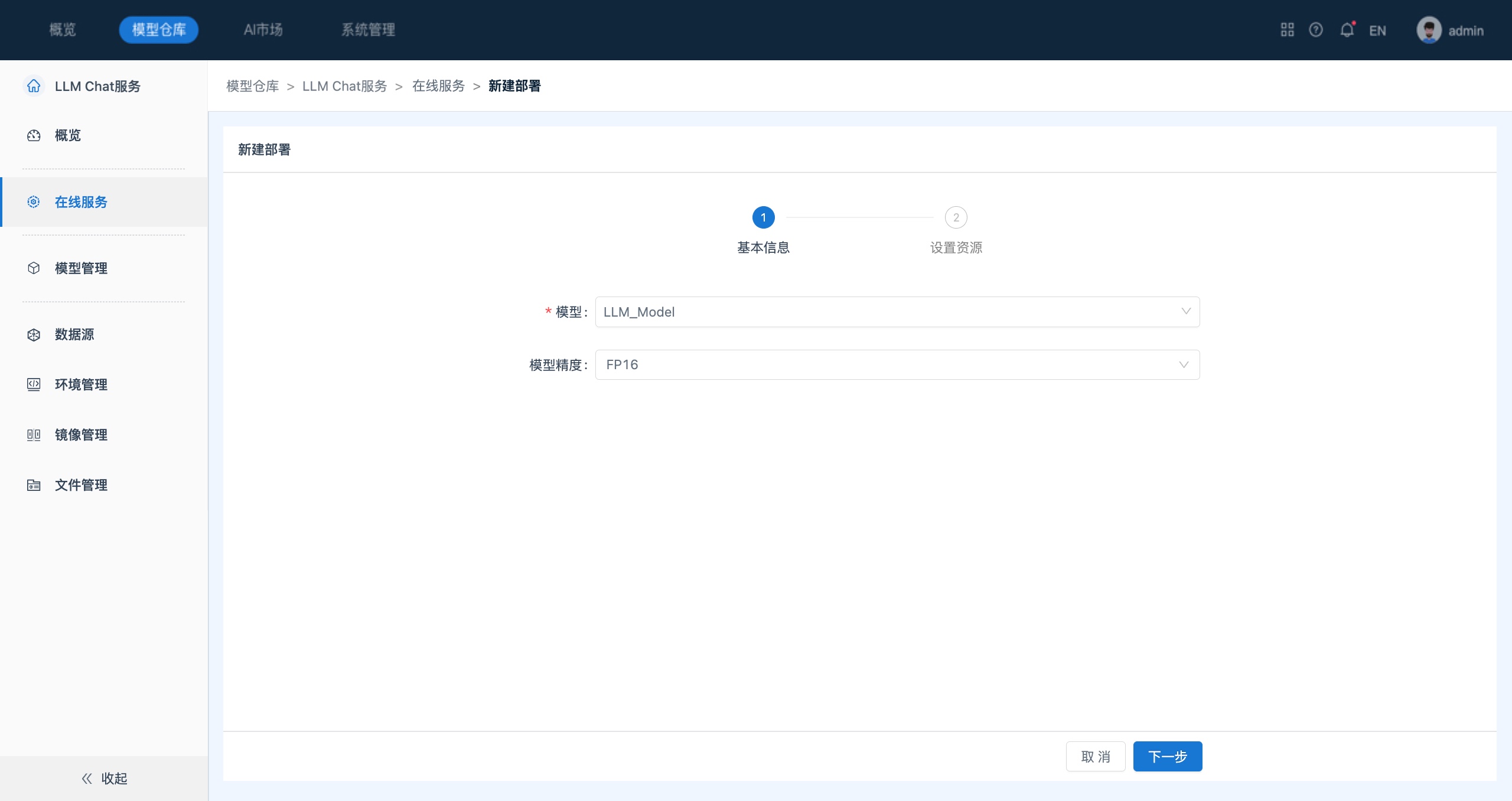
【说明】
大模型部署时支持设置模型精度,包括FP16、FP8、INT8、INT4。在推理阶段通过合理选择精度类型,可以提升模型的推理速度,节省存储空间。
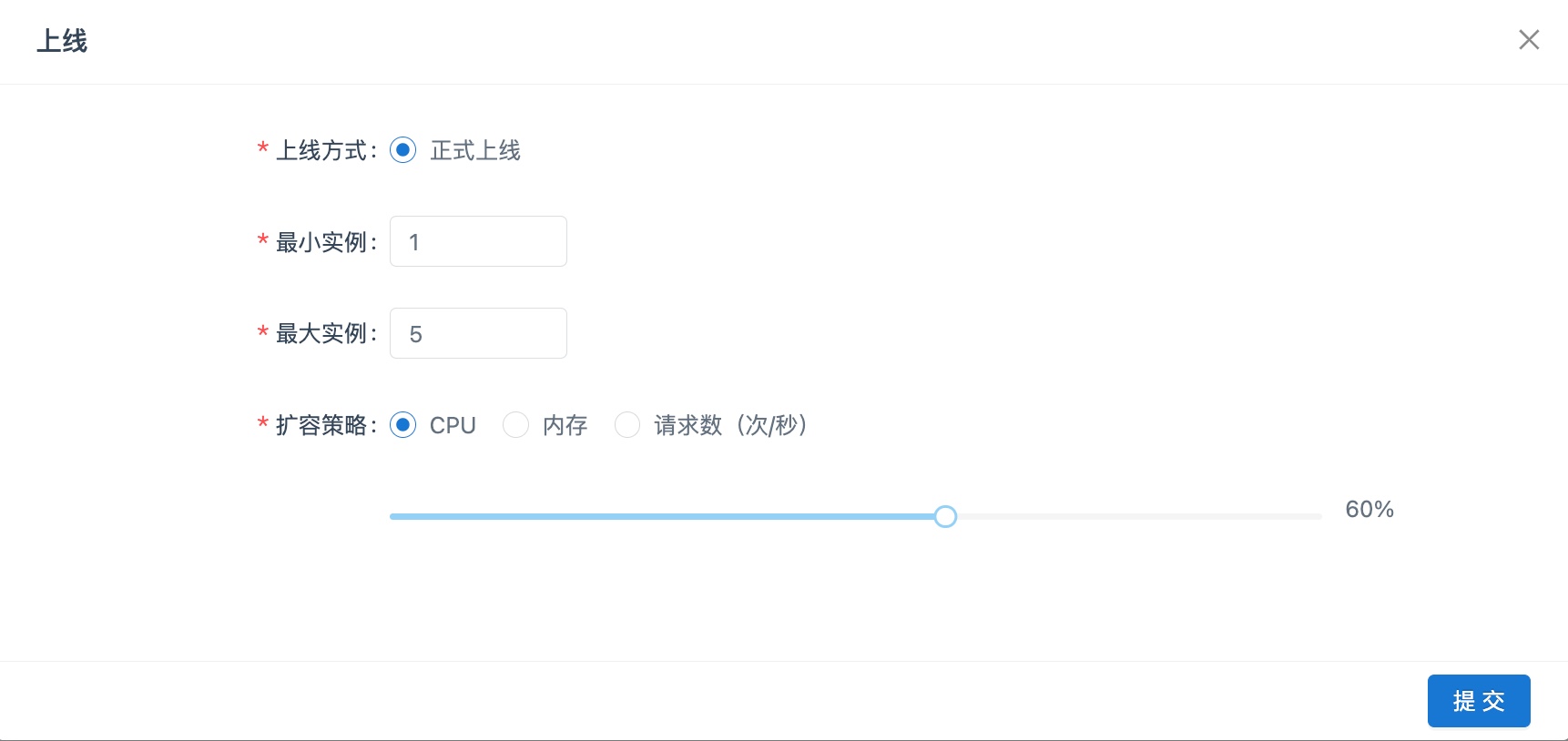
- 在成功部署模型后,可以将其上线,从而以服务的形式对内外部应用提供预测和调用。在在线服务“模型列表”中,单击模型所在行的“上线”按钮,系统显示“上线”对话框,设置服务弹性扩缩容参数。
服务调试说明
模型上线后,通过点击在线服务列表右上角的“调试”按钮,进入调试页面。
提供3种LLM服务调试方式:Chat Test、Chat API和Generate API,您可以根据不同的应用场景,选择合适的调试方法。
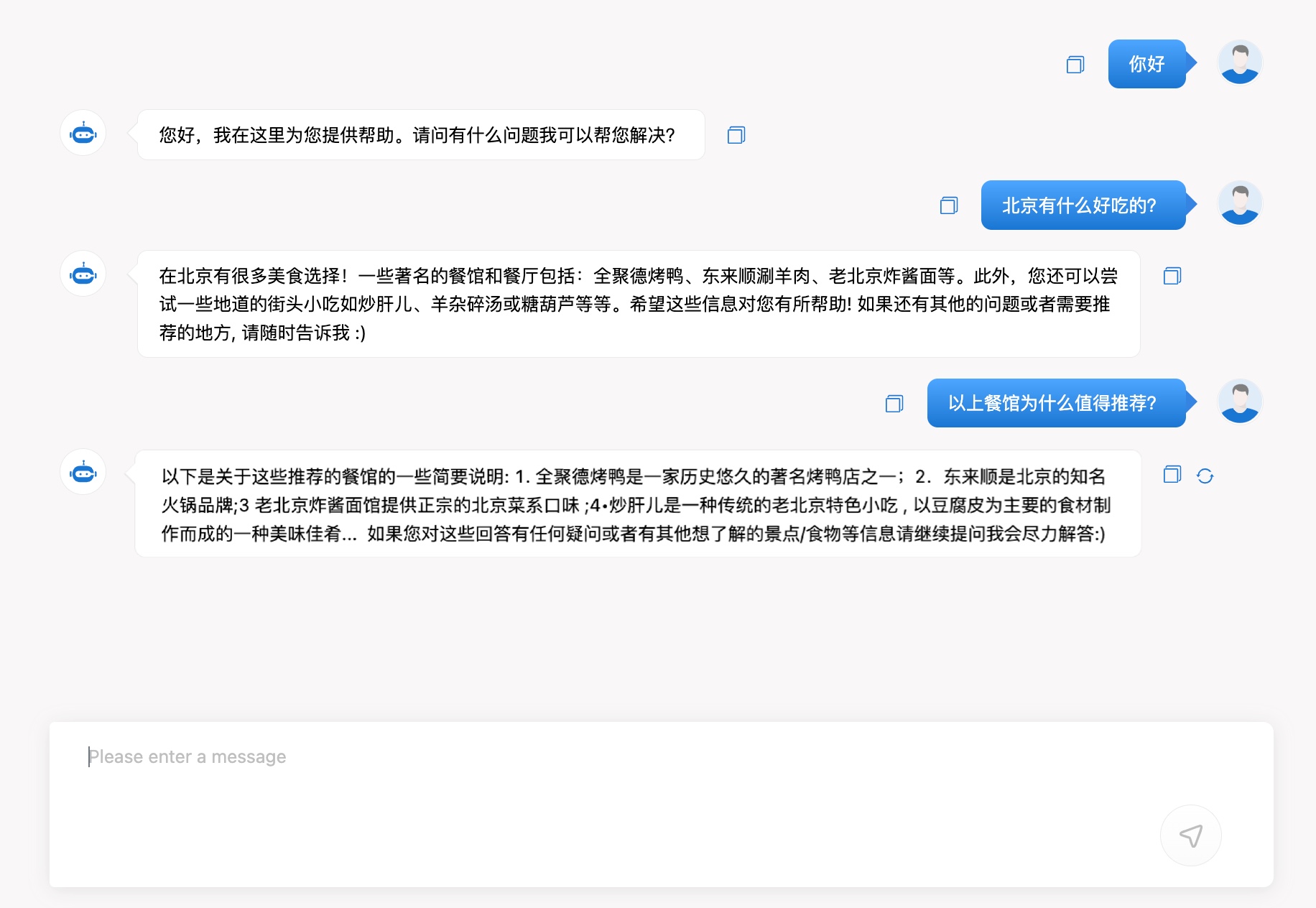
Chat Test调用
Chat Test是指通过用户界面(UI)直接与LLM进行交互,适用于手动测试和体验模型的对话效果。您可以通过messages方式向大模型提问。支持多轮对话,可以关联上下文信息,对话形式更符合日常交流的场景。
调用成功后将输出以下结果:
GenerationConfig说明
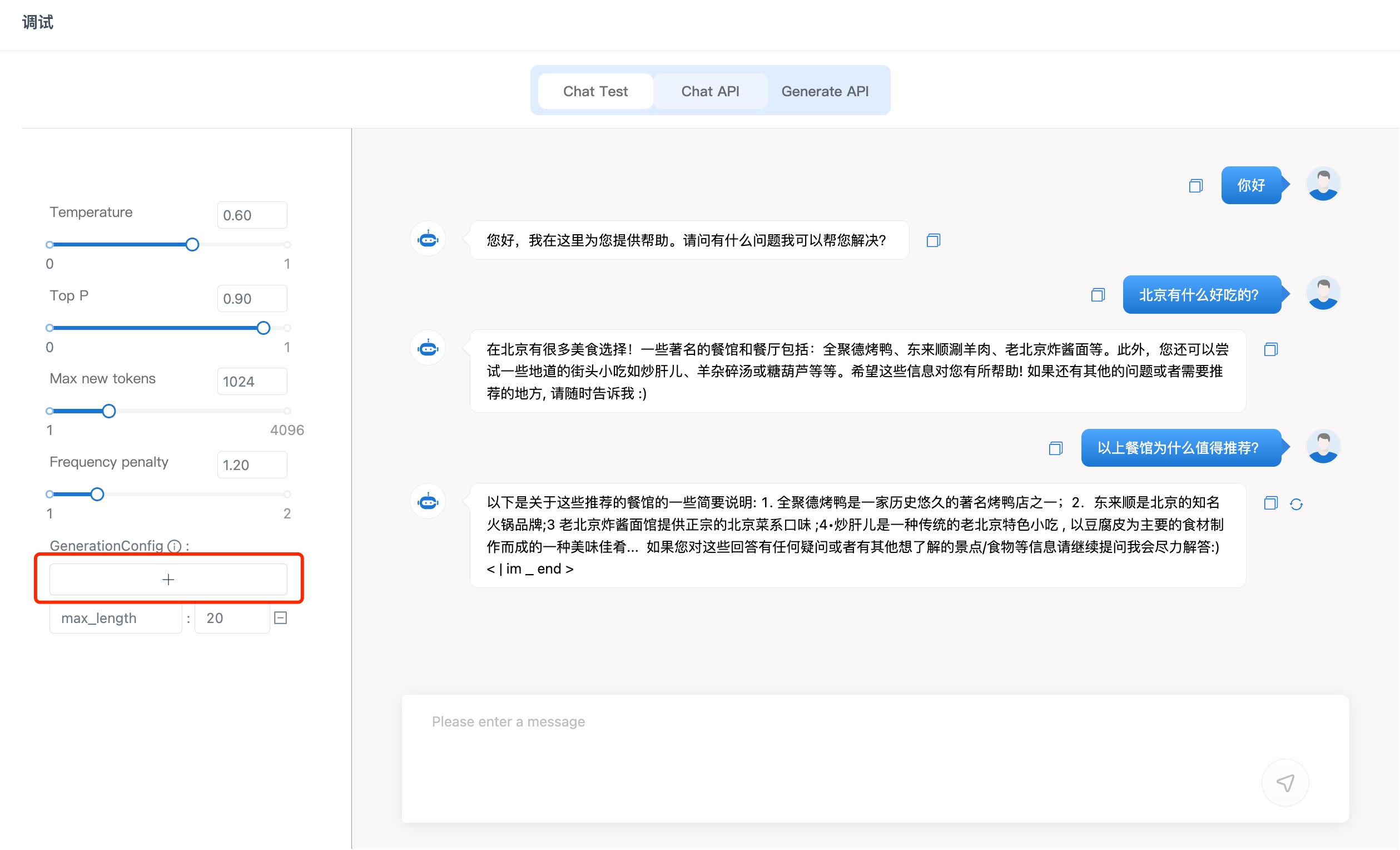
GenerationConfig用来指定生成文本时的各种配置选项和参数。它通常包含了生成过程中需要的各种设置,例如生成长度、温度(temperature)、重复惩罚(repetition penalty)、top k采样(top-k sampling)等。通过使用GenerationConfig,用户可以灵活地调整LLM的生成内容。
您可以通过左侧“+“按钮添加更多GenerationConfig,如下所示:
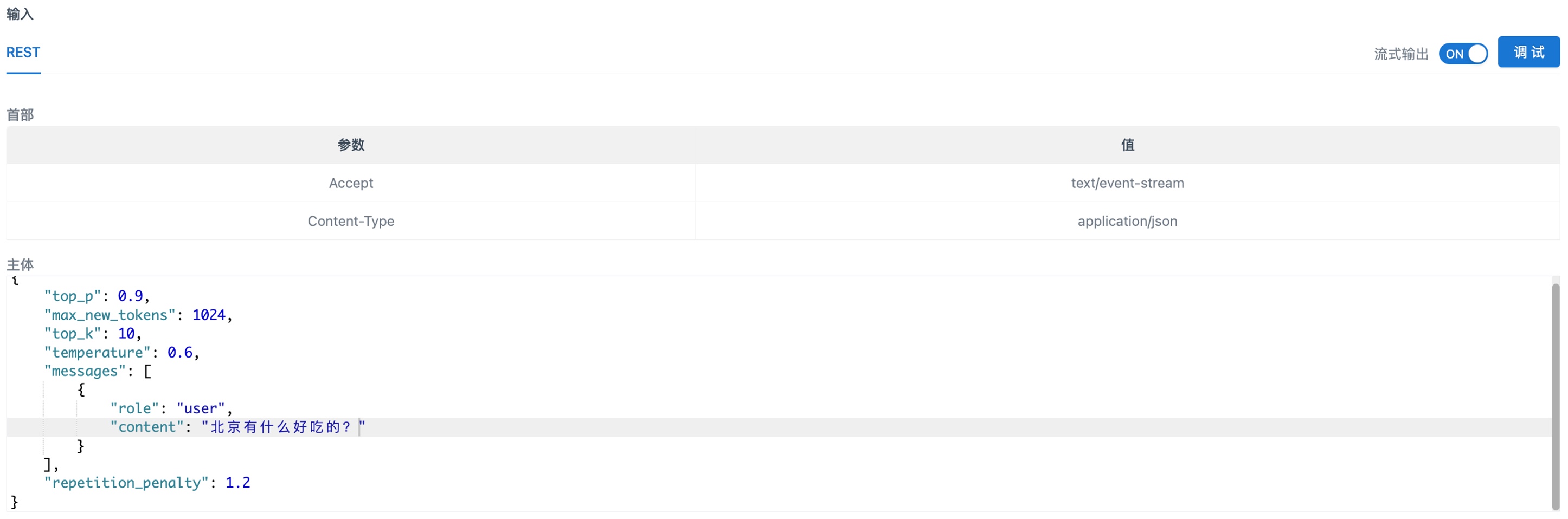
Chat API调用
Chat API是指通过编程接口与LLM进行交互,适用于自动化测试和大规模应用场景。您可以运行以下代码,通过messages方式向大模型提问。
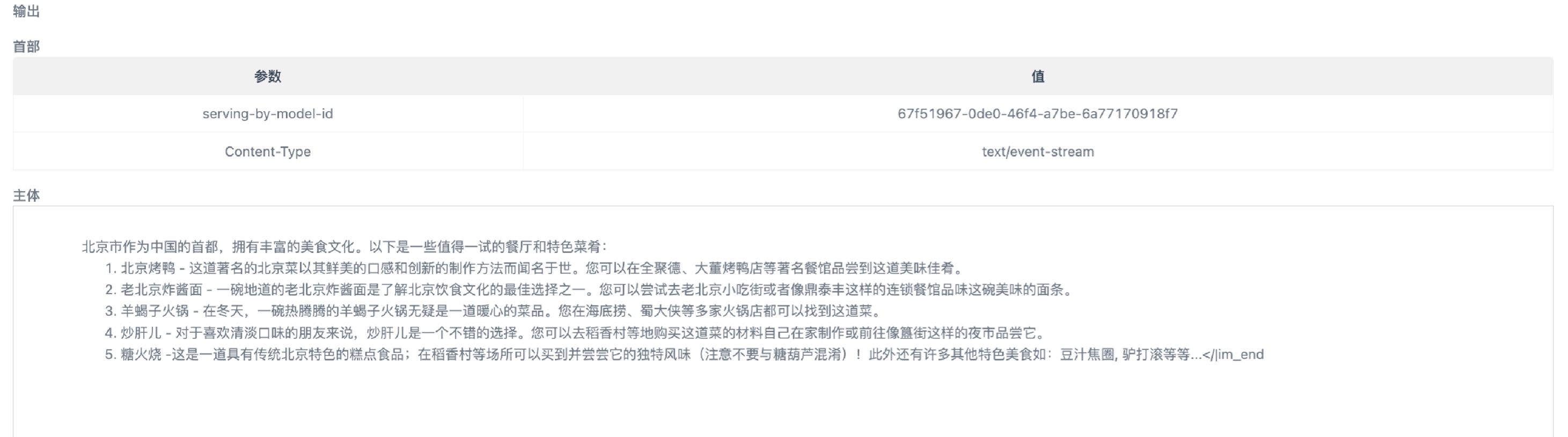
调用成功后将输出以下结果。
Generate API调用
Generate API通常用于文本内容续写,适用于内容创作、文本摘要、变成代码等多种场景。您可以运行以下代码,通过prompt方式向大模型提问。
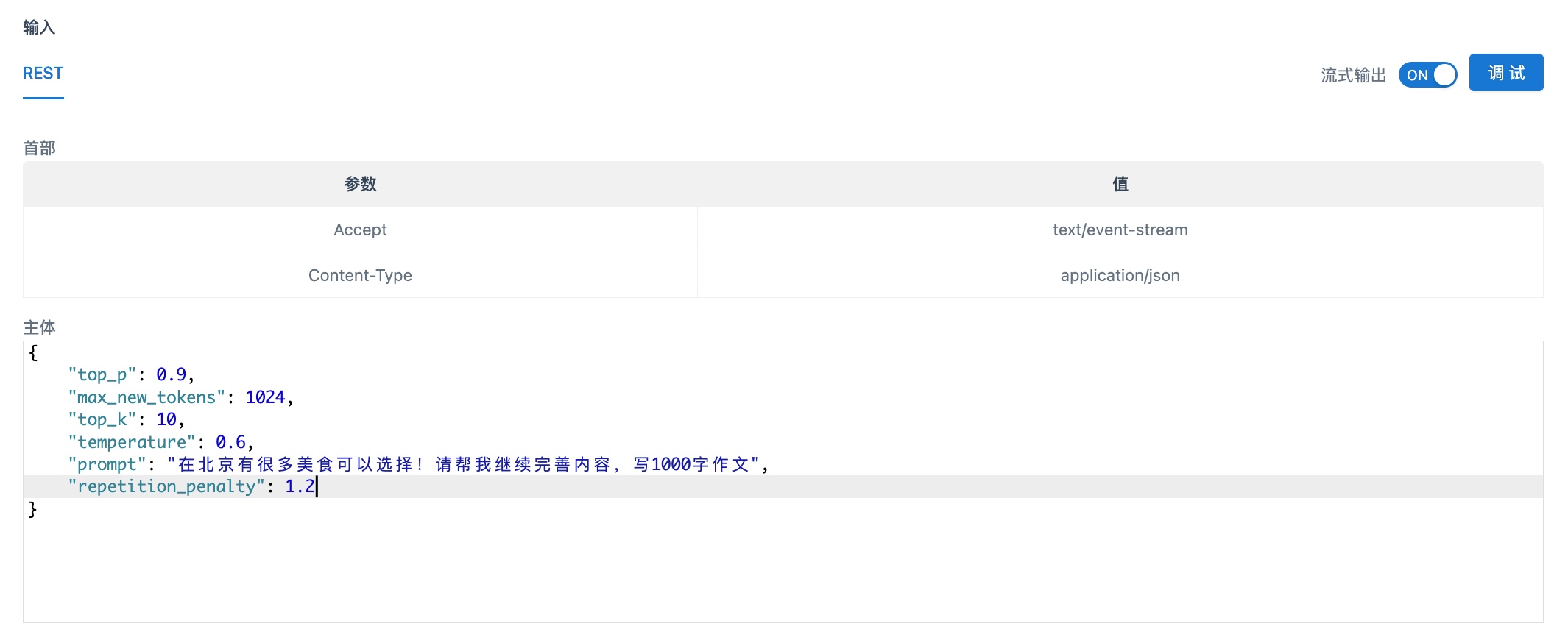
调用成功后将输出以下结果。
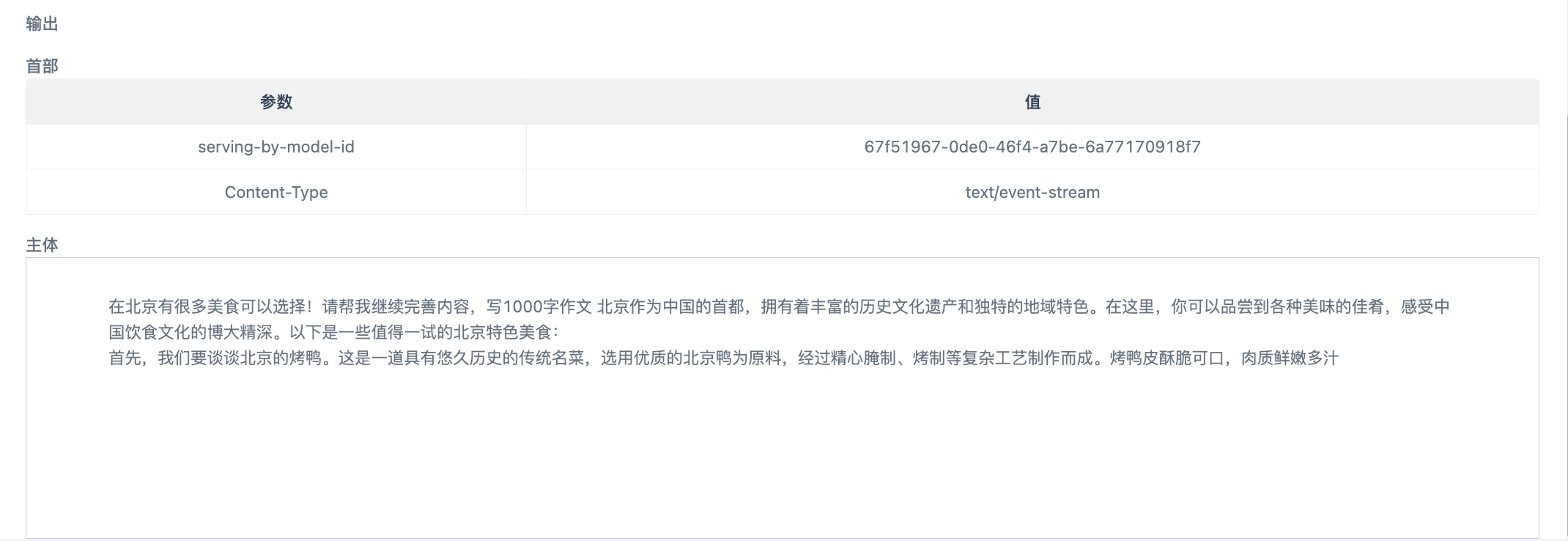
流式输出说明:
大模型并不是一次性生成最终结果,而是逐步地生成中间结果,最终结果由中间结果拼接而成。非流式输出方式等待模型生成结束后再将生成的中间结果拼接后返回,而流式输出可以实时地将中间结果返回,您可以在模型进行输出的同时进行阅读,减少等待模型回复的时间。使用流式输出需要您打开流式输出开关即可。
