预训练大语言模型(LLM)
大模型的训练往往分为多个阶段,而预训练(pre-training)是其中最基础且重要的环节,该阶段需要在庞大的文本语料库上做训练,使模型具备通用的文本生成能力,后续再在预训练模型的基础上根据业务场景进行微调。本文档着重从数据准备、模型选择、模型训练、优化训练过程等方面介绍如何做预训练。
数据准备
在预训练大型语言模型的过程中,数据准备是一个至关重要的步骤,它直接影响到模型的学习效果和最终性能,包含原始数据采集和数据处理步骤。
数据采集
预训练模型的性能很大程度上依赖于训练数据的规模和多样性。数据来源可以是网页文本、书籍、科学论文、技术文档、新闻报道等。重要的是要确保数据来源的合法性和数据的多样性,以覆盖尽可能多的语言使用场景和领域。
下图为一些用于大模型预训练的数据集的组成情况(图片引用自:arXiv:2303.18223 [cs.CL]):
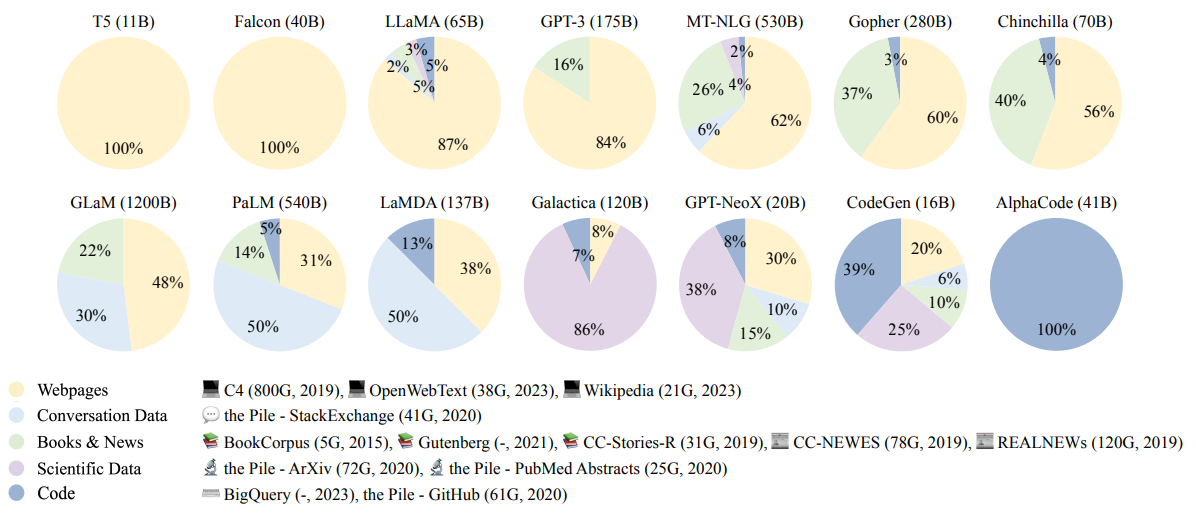
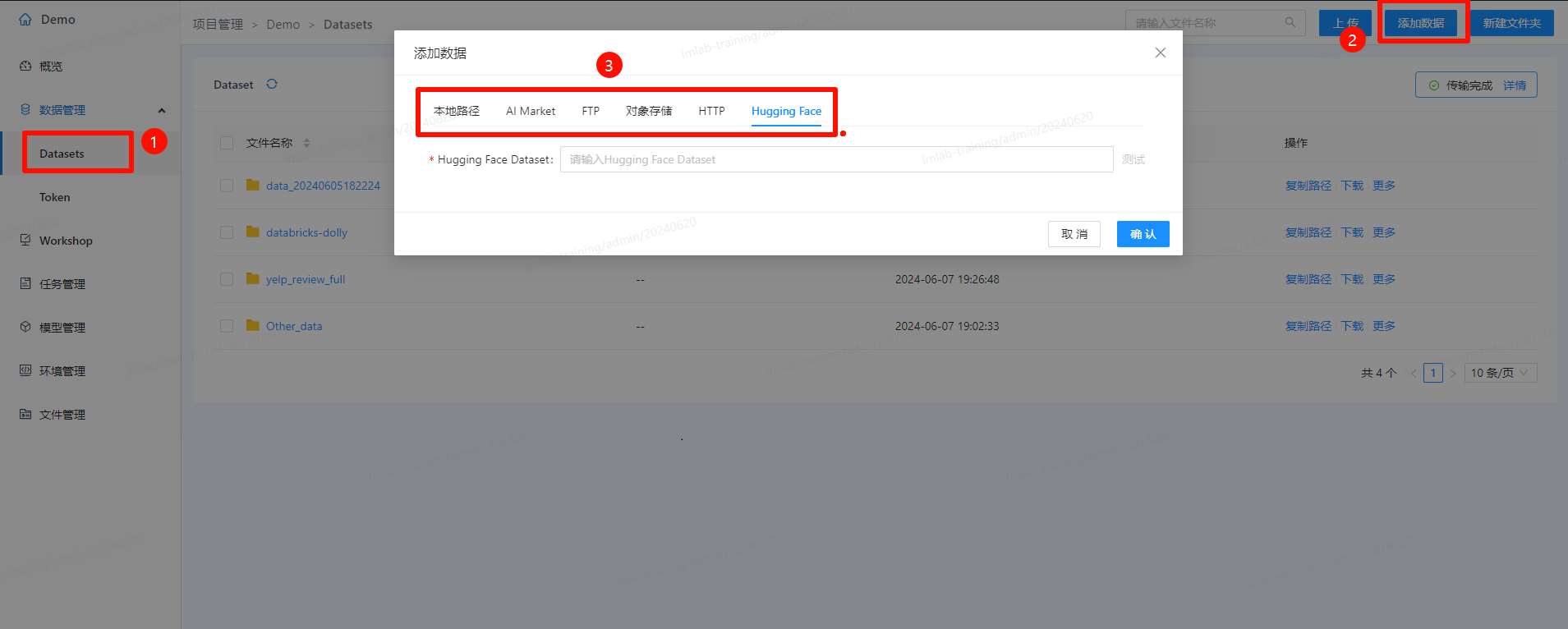
数据采集可通过平台中的数据集功能实现:
- 点击菜单中的“Tools”,并进入LM Lab。进入后,点击“项目管理”,选择要进入的项目,并在项目中点击左侧菜单的"Datasets"。
- 导入数据
- 点击“上传”,可上传本地文件
- 点击“添加数据”,可通过本地路径、AI Market、FTP、对象存储、HTTP、HuggingFace等方式进行数据导入
数据处理
在将数据整合到训练集之前,需要过滤掉低质量的文本,包括广告、垃圾信息、重复内容或语法结构不完整的句子等。可以使用启发式规则(例如,过滤掉包含过多特殊字符或链接的文本)和基于模型的方法(例如,使用文本分类器来判别文本质量)。
查用的数据处理方式包含:
- 数据格式清洗:需要对文本进行标准化处理,如统一字符编码、去除无用的格式化元素(如HTML标签)、转换为小写、删除多余的空白字符等。这有助于减少模型训练过程中的噪声,并提高模型对数据的处理效率。
- 过滤低质量内容:
- 可以设计正则表达式来匹配关键词,过滤掉广告、无意义语句等内容;
- 对于多语言模型,需要根据目标语种进行数据过滤,排除不相关语言的文本;
- 对于论坛文章之类的数据,可以通过热门程度、赞同数等来过滤低质量的数据。
- 敏感内容过滤:
- “黄赌毒”、暴力、危险言论等:可以使用规则与训练分类模型相结合的方式来过滤此类内容;
- 用户无意中泄露在互联网中的隐私内容也需要过滤掉。
- 数据去重:去重是保证数据质量的重要步骤,可以防止模型过度拟合某些重复的样本,影响模型的泛化能力。数据去重通常在句子和文档级别进行,使用哈希匹配和相似度检测等技术。
通过上述步骤,可以为预训练模型准备高质量、高效率和高覆盖度的训练数据,为后续的模型训练打下坚实的基础。
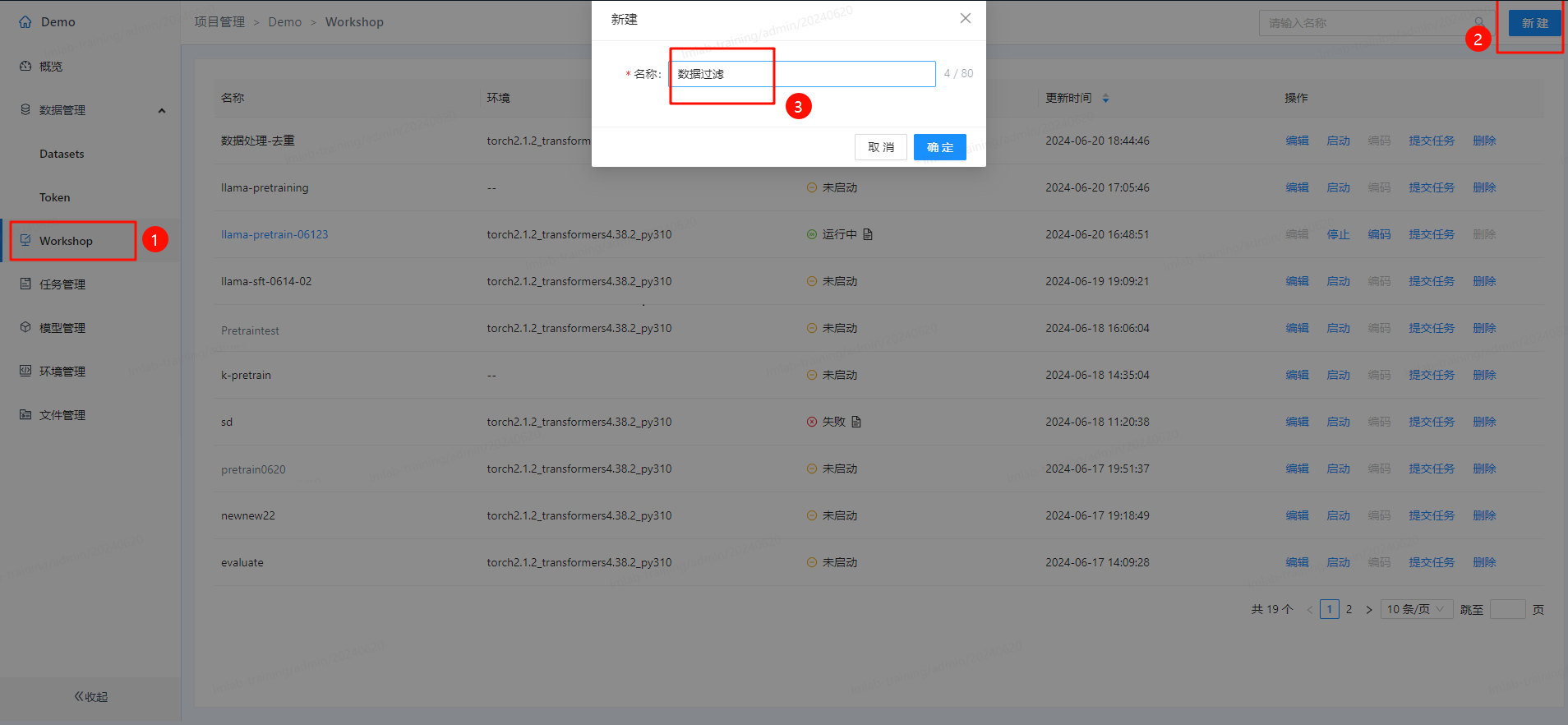
考虑到完整的数据处理需要大量的工作,现在我们仅以数据过滤为例来说明如何在平台中进行数据处理:
- 在Workshop中创建一个“数据过滤”项目:
- 启动这个workshop,并进入编码环境,开发数据去重代码:
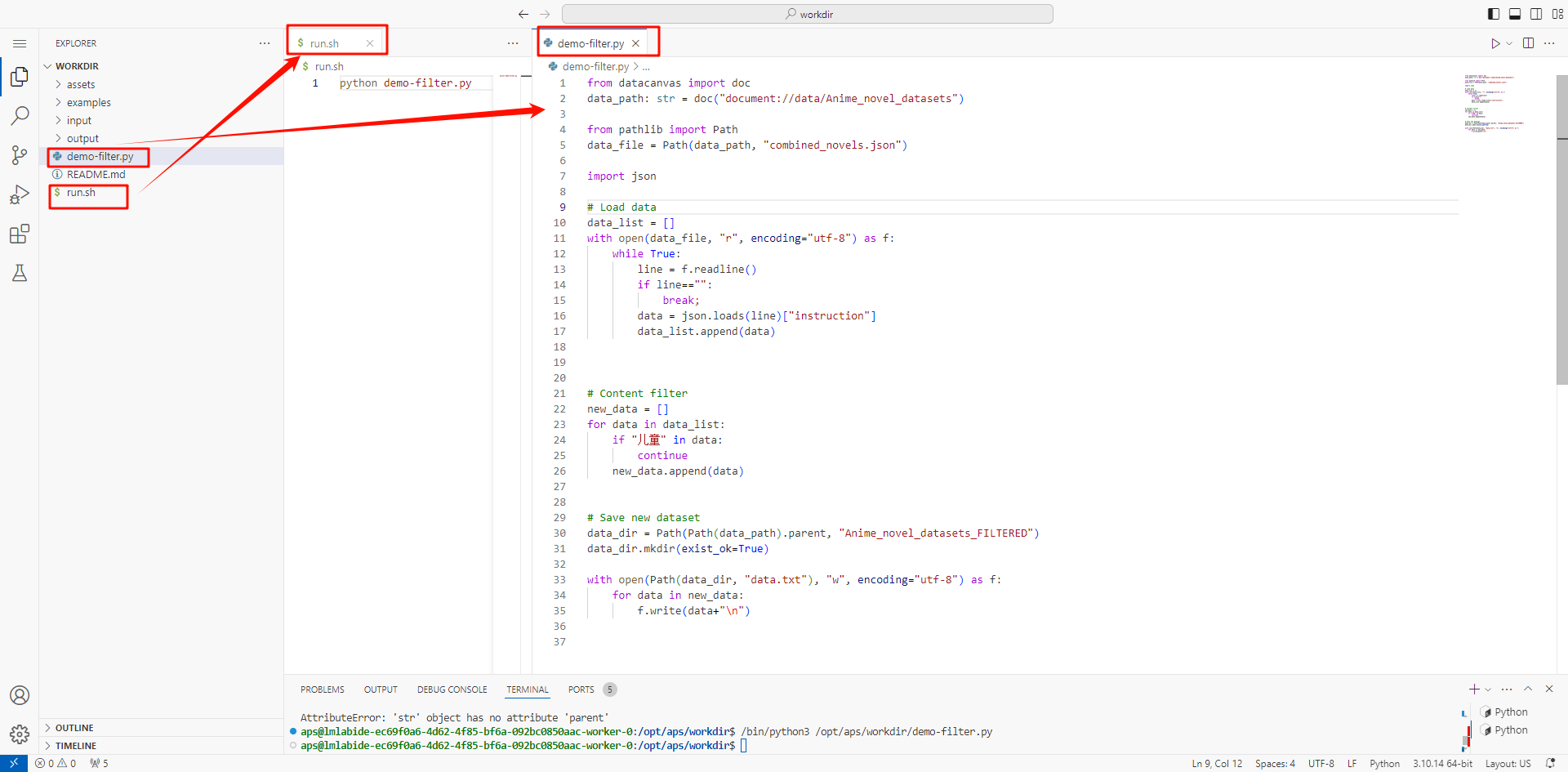
from datacanvas import doc
data_path: str = doc("document://data/Anime_novel_datasets")
from pathlib import Path
data_file = Path(data_path, "combined_novels.json")
import json
# Load data
data_list = []
with open(data_file, "r", encoding="utf-8") as f:
while True:
line = f.readline()
if line=="":
break;
data = json.loads(line)["instruction"]
data_list.append(data)
# Content filter
new_data = []
for data in data_list:
if "儿童" in data:
continue
new_data.append(data)
# Save new dataset
data_dir = Path(Path(data_path).parent, "Anime_novel_datasets_FILTERED")
data_dir.mkdir(exist_ok=True)
with open(Path(data_dir, "data.txt"), "w", encoding="utf-8") as f:
for data in new_data:
f.write(data+"\n")
- 发布示例代码并运行:
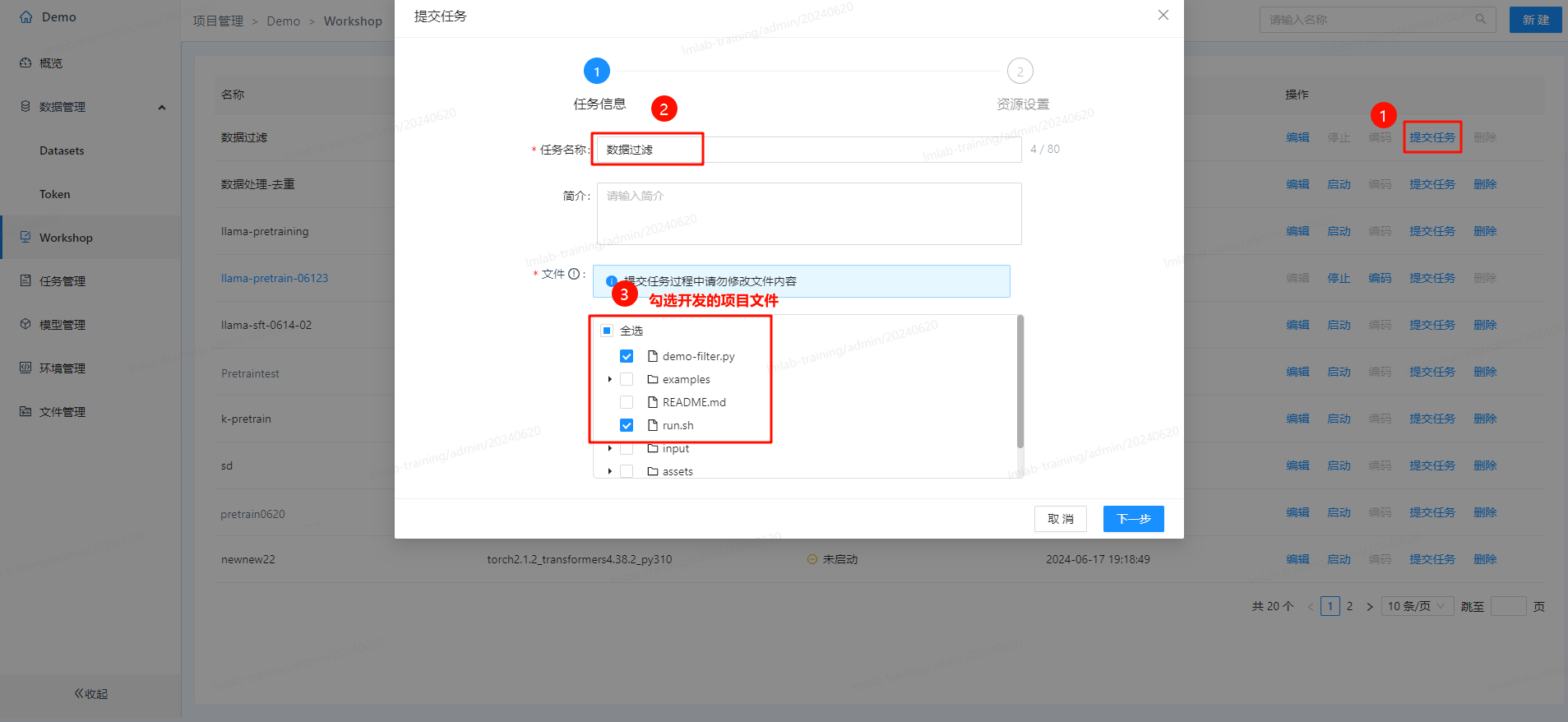
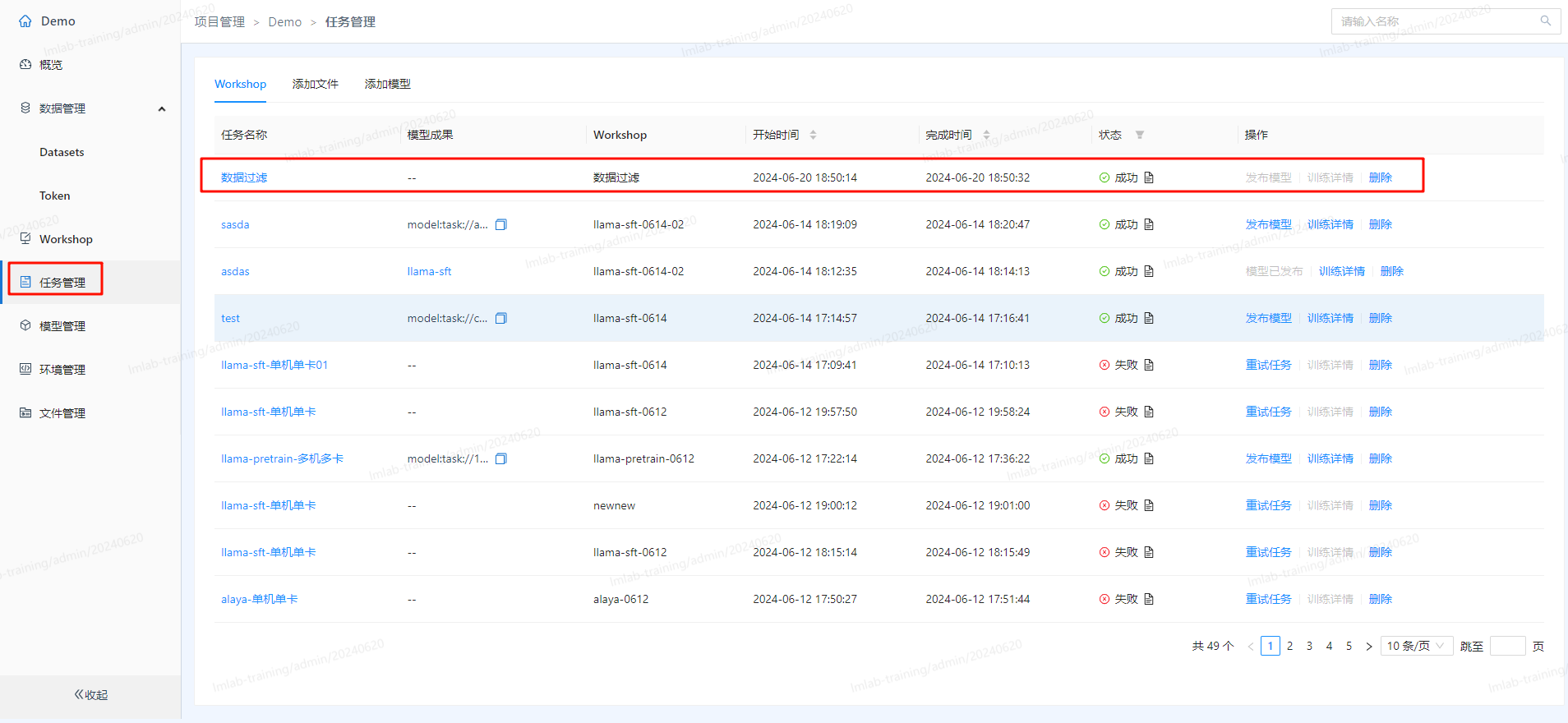
- 运行后在任务管理里可看执行状态,完成后即可在Datasets中看到过滤后生成的数据集:
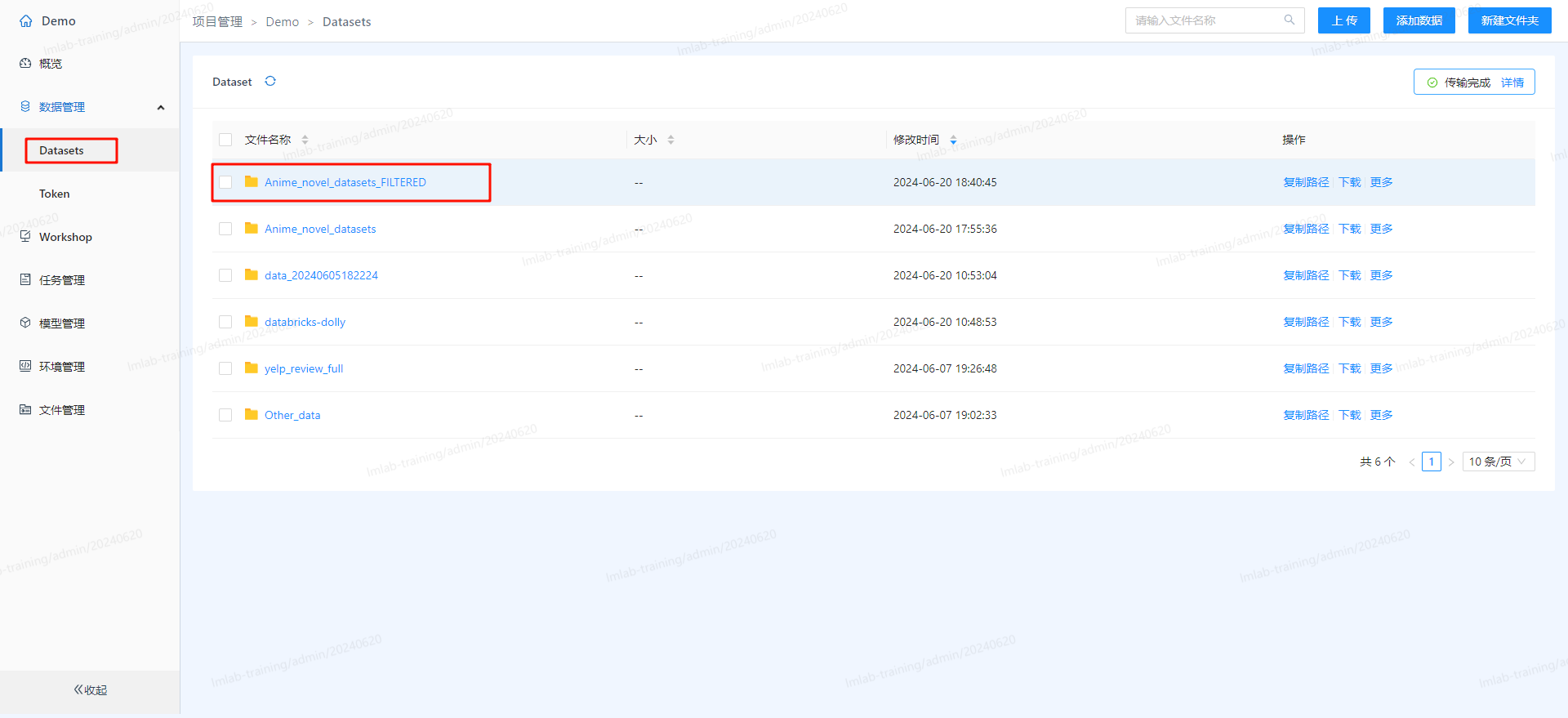
训练分词器
分词是将原始文本分割成模型可识别和建模的词元序列(token sequence)的过程,作为大语言模型的输入数据。以下是一些核心的分词算法:
-
WordLevel:这是一种经典的分词算法,它直接将完整的单词映射到唯一的ID。这种方法的优点是非常简单易懂,但需要非常大的词汇表来达到较好的覆盖率。
-
BPE(Byte Pair Encoding):BPE是一种非常流行的子词分词算法。它的工作原理是从字符开始,合并计数最多的连续词元,创建出新的词表,再在新的词表上合并计数最多的连续词元,如此迭代下去直到词表达到预期大小。BPE能够通过使用多个子词token来构建它从未见过的单词,因此需要的词汇表较小,减少了“unk”(unknown)token的出现。
-
WordPiece:WordPiece是与BPE相似的另一种子词分词算法,在BERT模型中有使用,与BPE算法的区别在于,合并连续词元时候的依据由新词的计数变成了新词计数比上第一个词元计数与第二个词元计数之积。
-
Unigram:Unigram也是一种子词分词算法,它从语料库的一组足够大的词元初始集合开始,迭代地删除其中的词元,直到达到预期的词表大小。
这些分词模型都有其适用场景,如BPE和WordPiece更适合需要灵活处理未知词汇的任务,而WordLevel则适合词汇较为固定的应用场景。接下来以BPE分词为例给出一些示例代码,平台中使用时将这些代码迁移到workshop即可。
如果已经有候选的开源预训练模型,该模型会有配套的分词器,此时直接使用即可:
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained("bert-base-uncased")
如果需要在已有语料上重新训练分词器,需要:
from tokenizers import Tokenizer
from tokenizers.models import BPE
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
from tokenizers.trainers import BpeTrainer
trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
files = [f"data/wikitext-103-raw/wiki.{split}.raw" for split in ["test", "train", "valid"]]
tokenizer.train(files, trainer)
tokenizer.save("data/tokenizer-wiki.json")
# 加载:
# tokenizer = Tokenizer.from_file("data/tokenizer-wiki.json")
模型选择
现在主流的大语言模型都是基于 Transformer 设计的。标准的 Transformer 由编码器(encoder)+解码器(decoder)构成,后续又衍生了 encoder only 和 decoder only 结构的模型。一些模型结构如下图(图片引用自:arXiv:2303.18223 [cs.CL]):
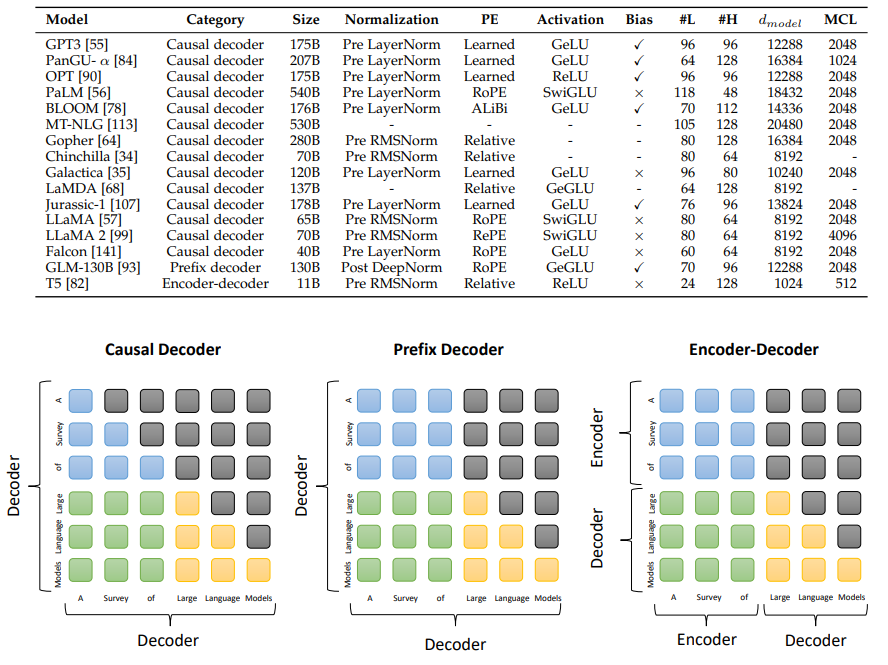
编码器(Encoder-only)、解码器(Decoder-only)和编码器-解码器(Encoder-decoder)这三种架构都有其独特的优点和适用场景,选择合适的架构取决于具体的应用需求和目标任务。以下是这三种架构的选型建议:
- Encoder-only
- 优点:采用双向自注意力机制,编码器使用双向自注意力机制全面理解输入信息,有助于捕捉上下文中的复杂关系。
- 缺点:生成能力有限,不擅长自主生成文本或内容。
- 适用于需要精确控制输入和输出关系的任务,如文本分类。
- Decoder-only
- 优点:仅使用解码器组件,模型结构相对简单。
- 缺点:在模型参数较少时理解能力有限,不擅长理解复杂的输入数据。
- 适用于生成任务。
- Encoder-decoder
- 优点:encoder部分采用双向自注意力,能够理解复杂输入,并在decoder部分生成相关输出。
- 缺点:相比单一的Encoder或Decoder,它的结构更加复杂。
- 适用于需要理解输入并生成相应输出的任务,如机器翻译。
由于现在的模型参数越来越大,如Decoder-only的生成式模型,在大参数、大数据量的、大规模训练的情况下其各方面表现都相当优异,涌现出的大部分优秀生成式模型都是decoder-only架构。
在选择具体的模型架构时,应综合考虑任务的具体需求、模型的架构特性、训练成本、以及可用的计算资源等,才能做出比较好的选择。
模型训练
训练的主体流程为:
- 加载训练数据集及验证数据集
- 初始化优化器
- 初始化模型
- 训练
这里以Llama模型的预训练为例说明。
- 点击左侧菜单“Workshop”,新建workshop,创建完成后启动环境:
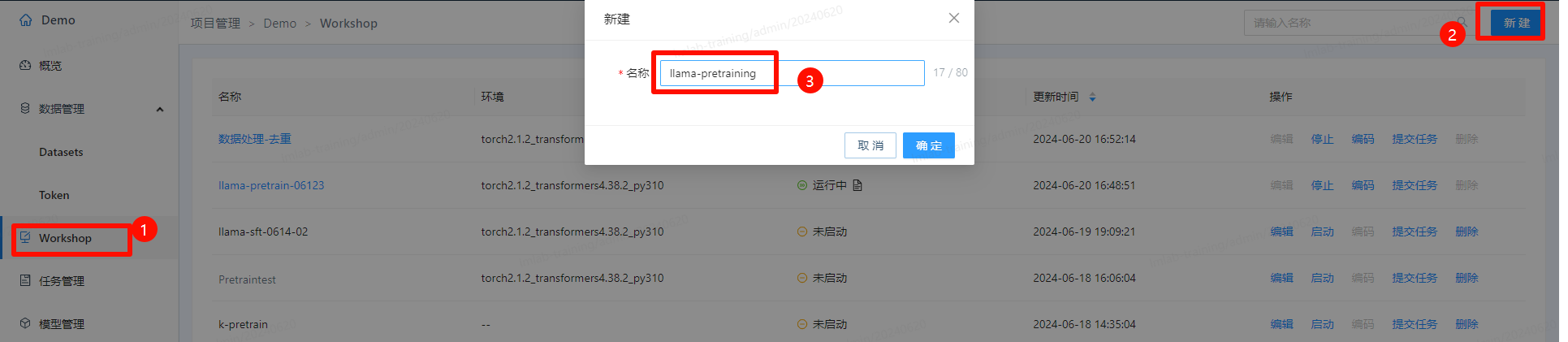
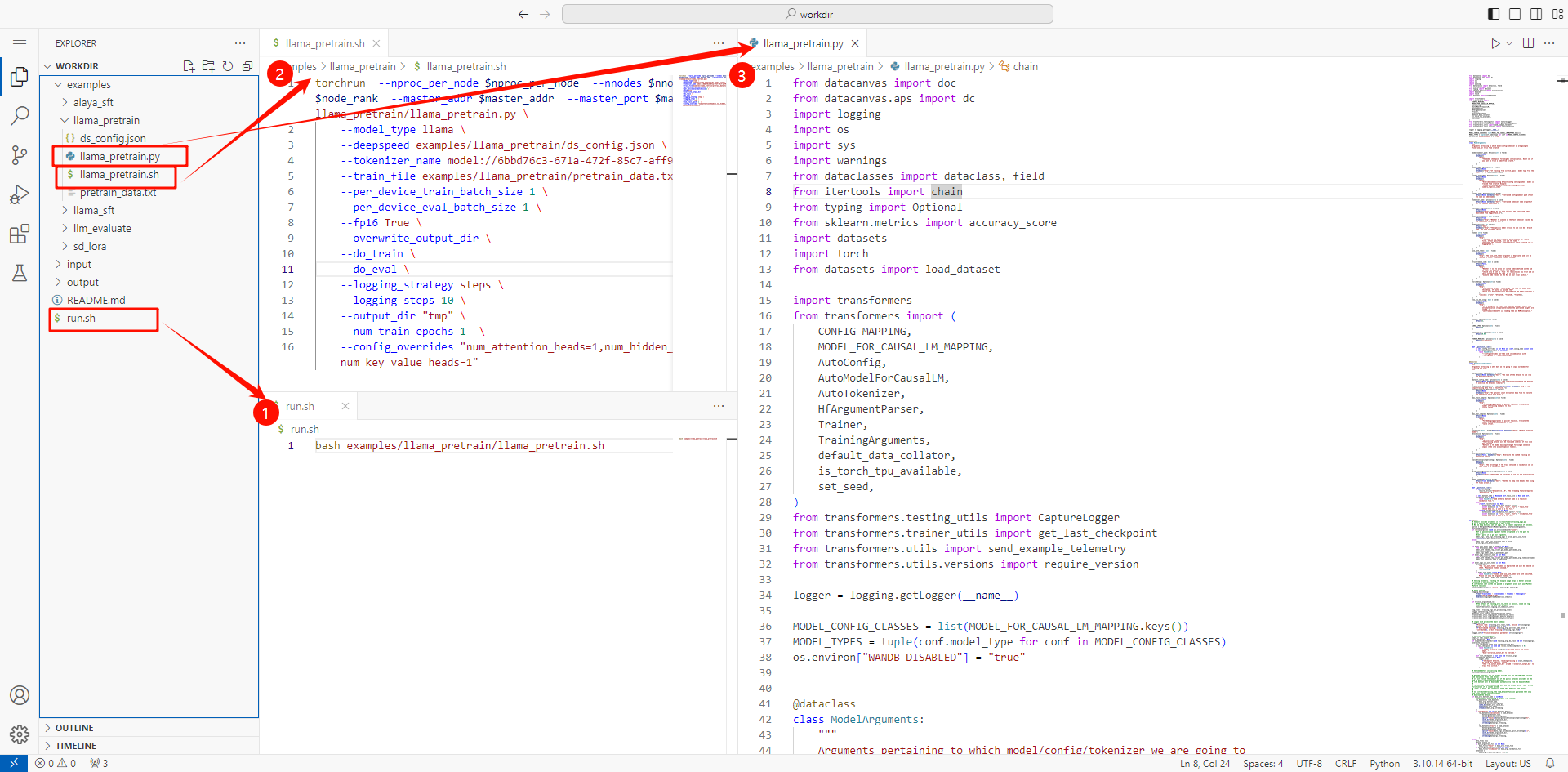
- 启动环境后,点击“编码”进入编码环境,在其中开发训练代码。下图为一个开发好的训练示例,其中 “run.sh” 为workshop的入口脚本,调用了 “llama_pretrain.sh”,而 “llama_pretrain.sh” 启动了训练脚本 “llama_pretrain.py”:
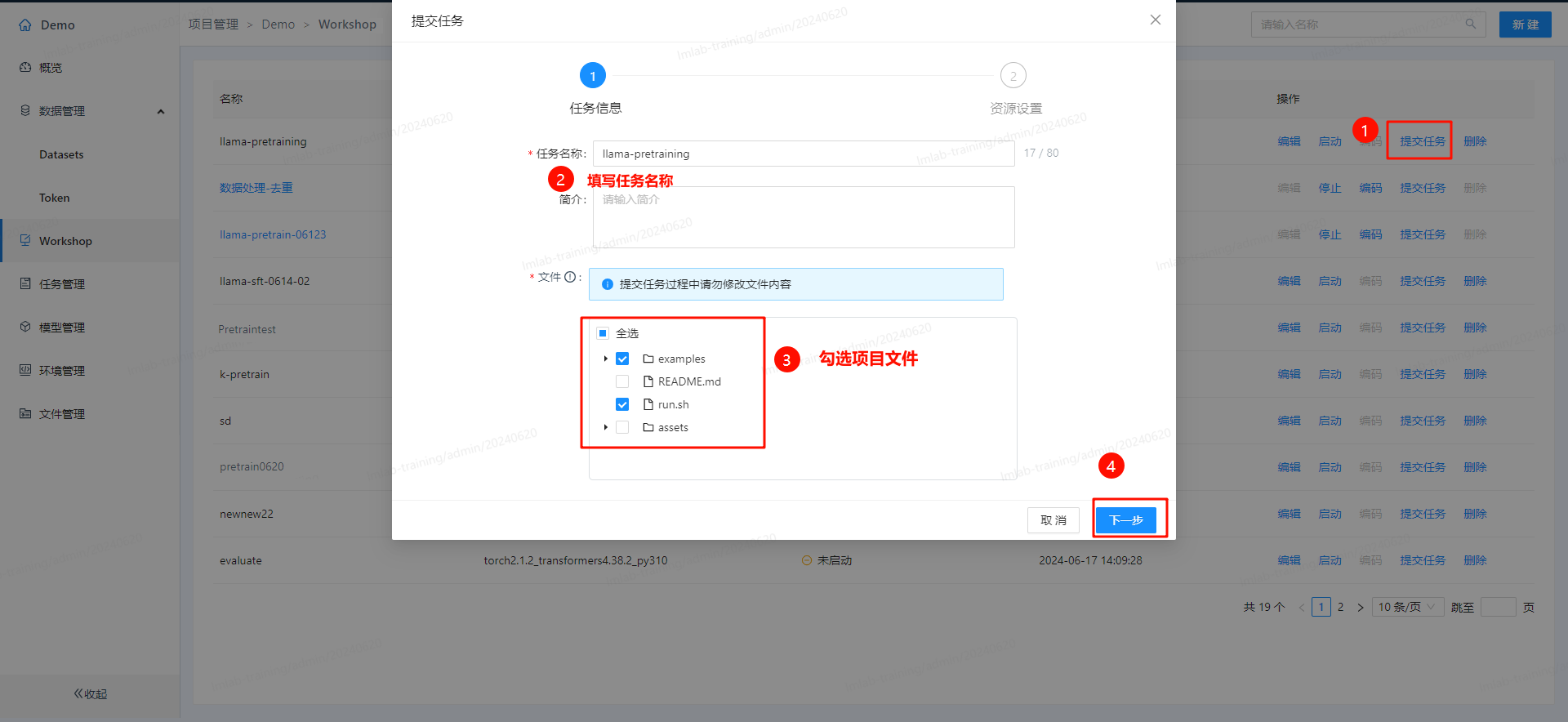
- 提交任务:
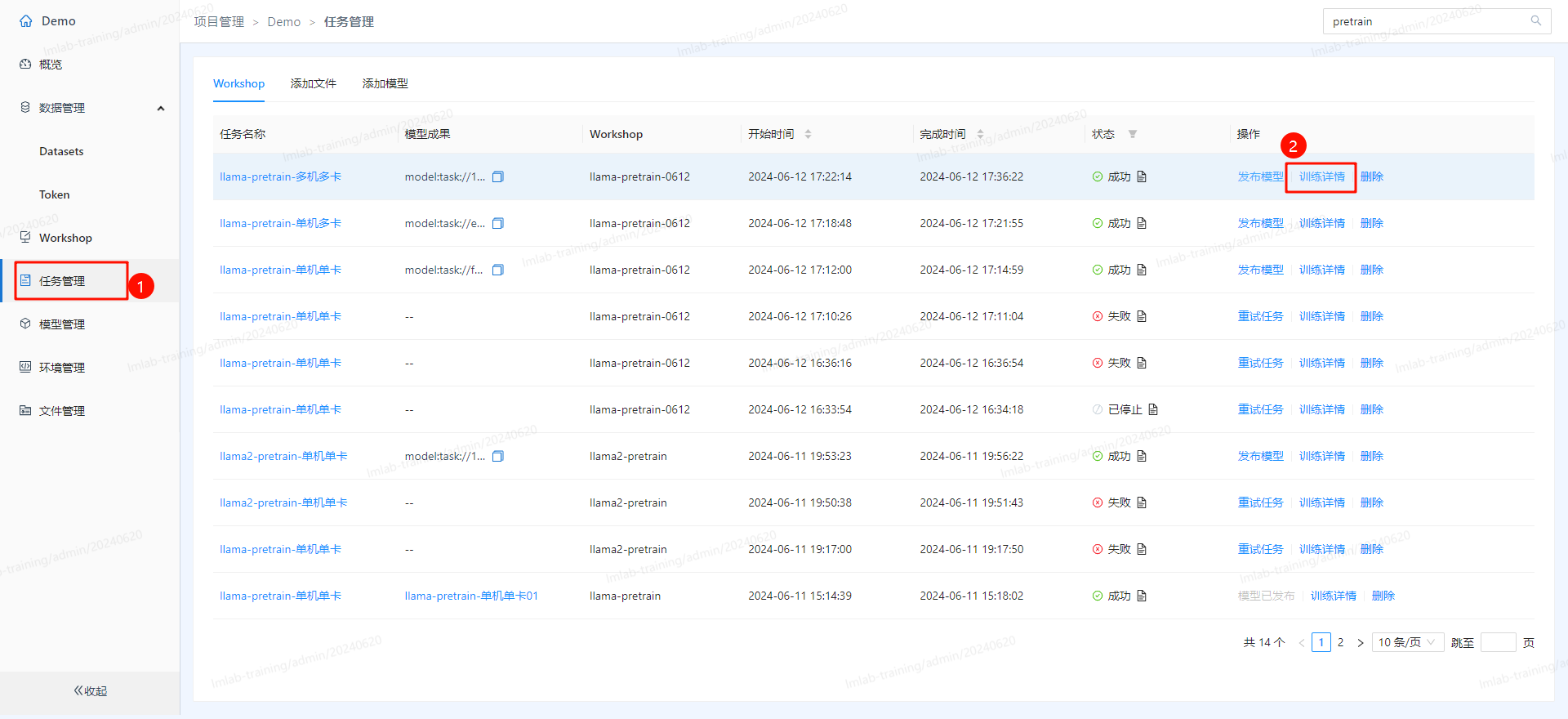
- 之后进入训练阶段,在任务管理中可以查看训练详情:
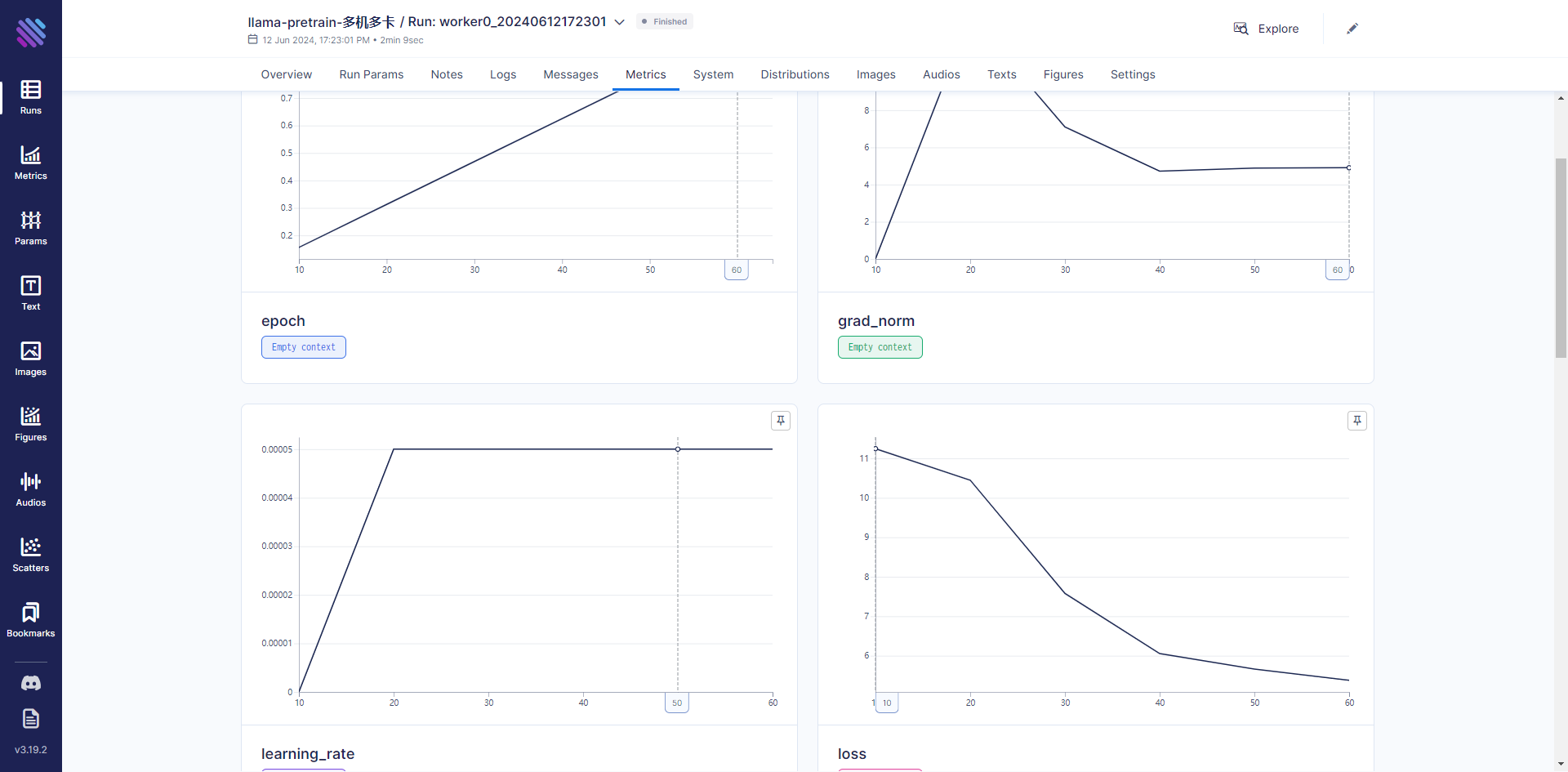
优化训练过程
模型的训练过程往往需要一次次的迭代优化。下面列出一些可能的优化点。
-
断点恢复
大模型的训练相当耗费资源,在训练时需要每过一段时间就对训练成果进行断点保存,方便之后从已有断点数据中恢复训练过程。一般情况下,断点需要保存的内容有:
- 模型的权重
- 优化器的状态
- 学习率调度器的状态
- 训练进度:epoch、bach数
- 数据集的状态
-
预先分词
在加载数据时,可以提前将文本内容进行分词,在训练时直接加载分过词的内容,以加快数据处理环节。
-
训练监控
训练过程中,除了监控基本的loss变化,还可以监控一些其他指标,如:
- 运行状态的指标,如CPU、内存和GPU负载,方便了解机器状态,是否发挥出了机器的全部性能,某些时间是否存在空载,可以通过这些观察来优化训练流程。
- 定时使用当前模型生成一些文本,可以直观的查看模型的效果。