弹性容器集群使用NIM
大语言模型(LLM)是近年来发展迅猛并且激动人心的热点话题,引入了许多新场景,满足了各行各业的需求。随着开源模型能力的不断增强,越来越多的企业开始尝试在生产环境中部署开源模型,将 AI 模型接入到现有的基础设施,优化系统延迟和吞吐量,完善监控和安全等方面。然而要在生产环境中部署这一套模型推理服务过程复杂且耗时。为了简化流程,帮助企业客户加速部署生成式 AI 模型,本文结合 NVIDIA NIM(一套专为安全、可靠地部署高性能 AI 模型推理而设计的微服务,是一套易于使用的预构建容器化工具)和Alaya NeW VCluster等产品,提供了一套开箱即用,快速构建高性能、灵活弹性的 LLM 推理服务的最佳实践。
需求场景
场景一:大模型云端快速部署
NIM通过提供易于使用的API和预构建的容器工具,简化了AI模型的部署过程,使得企业和开发者能够快速构建和部署优化的AI应用
场景二:实时监控和弹性扩缩容
结合监控服务,NIM可以实时观测推理服务状态,并配置弹性扩缩容策略,以适应不同的负载需求
前置条件
本教程假定您已经具备以下条件:
- 在您的系统上安装了kubectl
- 开通了Alaya NeW弹性容器集群,具体步骤参考开通弹性容器集群
方案概述
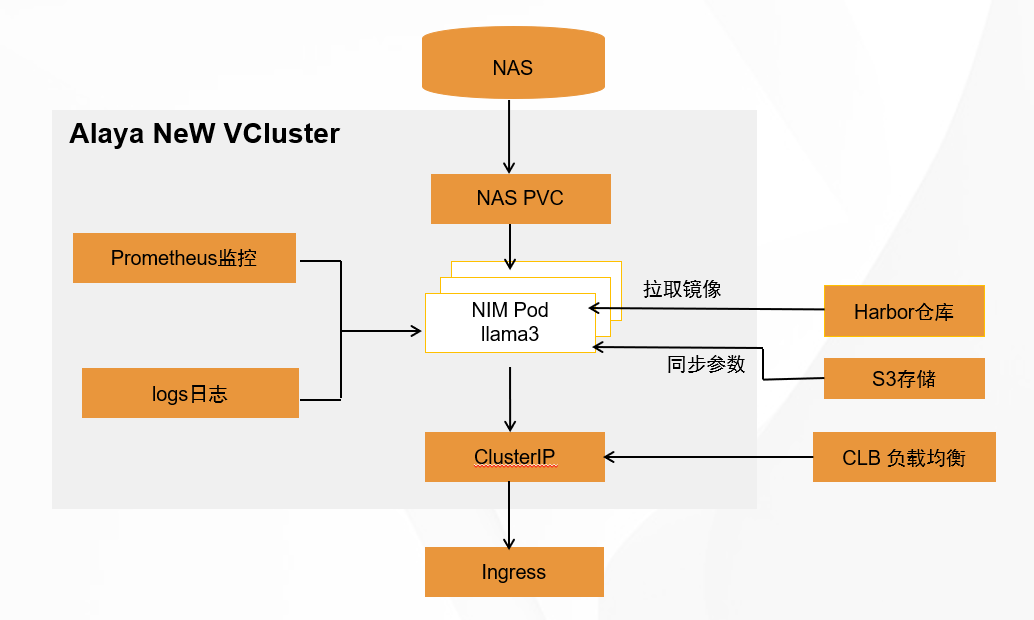
教程源代码
首先下载本教程所需要的源码文件并解压。
清单
本教程包含以下文件,以下是文件的作用说明。
| 文件名 | 说明 |
|---|---|
| config.json | 配置与 Harbor 容器镜像仓库相关的敏感信息 |
| nim_harbor_secret.yaml | 定义secret资源:在部署deployment资源时,用来拉取自定义镜像 |
| nim_deploy.yaml | 定义Deployment资源:定义如何启停pod |
| nim_svc.yaml | 定义Service资源:处理网络和发布服务 |
| nim_serviceexport.yaml | 定义ServiceExporter资源:将服务发布到公网 |
镜像仓库配置信息
在本示例中,镜像仓库的基本信息,由config.json配置。
{
"auths": {
"your_harbor_server": {
"username": "your_username",
"password": "your_password",
"email": "your_email"
}
}
}
注意: 编写config.json文件时,请将账号,密码,镜像仓库地址,邮箱等信息替换成你自己的:
| 变量名 | 说明 | 来源 | 示例 |
|---|---|---|---|
| your_harbor_server | 镜像仓库访问域名 | 资源中心/存储管理/镜像仓库界面 | https://registry.hd-01.alayanew.com:8443 |
| username | 镜像仓库用户名 | 开通短信 | user |
| password | 镜像仓库密码 | 开通短信 | password |
| 你的邮箱 | abc@hello.com |
密码
在本示例中,密码信息由nim_harbor_secret.yaml指定
Secret 是 Kubernetes 中的一种资源对象,用于存储和管理敏感信息(如密码、API 密钥、证书等),以确保这些信息不会暴露在配置文件或环境中。在本示例中创建secret来保护harbor的密码信息。
apiVersion: v1
kind: Secret
metadata:
name: harbor-secret
namespace: nim
type: kubernetes.io/dockerconfigjson
data:
.dockerconfigjson: dfsdfsdCn0K
注意: 编写nim_harbor_secret.yaml文件时,替换以下信息:
| 变量名 | 说明 | 来源 | 示例 |
|---|---|---|---|
| .dockerconfigjson | 使用base64对config.json进行编码 | 手动编码 | dfsdfsdCn0K.... |
部署
在本示例中,部署信息由nim_deploy.yaml文件指定。
具体指示弹性容器集群的Kubernetes control plane以下信息:
- 确保在任何时候只有一个Pod运行。这个实例是通过清单中的 spec.replicas 键值对定义的。
- 在运行pod的弹性容器集群计算节点上预留GPU、CPU和内存资源。在Kubernetes Pod中运行的每个nim实例分配了1个gpu,由下面的spec.template.spec.containers.resources.limits.nvidia.com/gpu-h800 键值对定义。
- 指定镜像,由 spec.template.spec.containers.image 键值对定义。
- 指定pvc的挂载目录,由 spec.template.spec.containers.volumeMounts 键值对定义。
- 指定pvc,由 spec.template.spec.volumes 定义
apiVersion: apps/v1
kind: Deployment
metadata:
name: nim-cdl
namespace: nim
labels:
app: nim-cdl
spec:
replicas: 1
selector:
matchLabels:
app: nim-cdl
template:
metadata:
labels:
app: nim-cdl
spec:
restartPolicy: Always
securityContext:
runAsUser: 1000
runAsGroup: 1000
fsGroup: 1000
imagePullSecrets:
- name: harbor-secret
containers:
- name: cuda-container
image: registry.hd-01.alayanew.com:8443/alayanew-dab57f9b-35f5-4dc1-afff-5cfd02esdsfe/llama3-8b-instruct:1.0.3
ports:
- containerPort: 8000
protocol: TCP
resources:
requests:
memory: "16G"
limits:
memory: "40G"
nvidia.com/gpu-l40s: 1 # requesting 1 GPU
env:
- name: NGC_API_KEY
valueFrom:
secretKeyRef:
name: ngc-api
key: NGC_API_KEY
volumeMounts:
- mountPath: /opt/nim/.cache
name: nim-cache
subPath: "nim/workspace"
volumes:
- name: nim-cache
persistentVolumeClaim:
claimName: pvc-capacity-userdata
注意: 编写nim_deploy.yaml文件时,请将一下信息替换成实际的信息:
| 变量名 | 说明 | 来源 | 示例 |
|---|---|---|---|
| image | 镜像名称 | 自己的镜像仓库 | registry.hd-01.alayanew.com:8443/alayanew-dab57f9b-35f5-4dc1-afff-5cfd02esdsfe/llama3-8b-instruct:1.0.3 |
| resources.requests.[GPU] | GPU资源信息 | 弹性容器集群 | nvidia.com/gpu-h800 |
服务
在本示例中,服务信息由nim_svc.yaml文件指定。
在Kubernetes中,网络流量是通过服务处理的,这些服务通常由它们自己的资源定义。在这个例子中定义了一个服务,它允许将部署发布到公共Internet服务规定TCP端口8888将作为ClusterIP类型向公共互联网开放:
apiVersion: v1
kind: Service
metadata:
name: nim-svc
namespace: nim
spec:
selector:
# 这里需要指定选择器,以便 Service 能够找到正确的 Pod
# 确保 Pod 的 metadata.labels 与这里的 selector 匹配
app: sd
ports:
- protocol: TCP
port: 7860 # Service 暴露在节点上的端口
targetPort: 7860 # Pod 容器内的端口
type: ClusterIP # Service 类型,NodePort 允许从集群外部访问
发布服务
在本示例中,向公网发布服务由nim_serviceexport.yaml指定。
# 对外发布服务
apiVersion: osm.datacanvas.com/v1alpha1
kind: ServiceExporter
metadata:
name: nim-se-svc # immutable
namespace: nim
spec:
serviceName: nim-svc # required
servicePort: 7860
操作步骤
镜像准备
从NGC仓库拉取镜像到本地
参考 NVIDIA NIM文档 ,生成 NVIDIA NGC API key,访问需要部署的模型镜像,比如本文中使用的 Llama3-8b-instruct。
请阅读并承诺遵守 Llama 模型的自定义可商用开源协议
注意: 声明NGC_API_KEY时,请替换为你自己的key值。
export NGC_API_KEY="nvapi-Vr4LgS4YIIsdn5LElkr4xgDMUHctyofDbBhkyc_JUiYKS1ILVO1MZMHf"
echo "$NGC_API_KEY"| docker login nvcr.io --username '$oauthtoken' --password-stdin
docker pull nvcr.io/nim/meta/llama3-8b-instruct:1.0.3
推送镜像到镜像仓库
注意: 以下命令中,请将账号,密码,镜像名称替换成你自己的。
# login
docker login https://registry.hd-01.alayanew.com:8443/ -u [user] -p [password]
# tag
docker tag nvcr.io/nim/meta/llama3-8b-instruct:1.0.3 [registry.hd-01.alayanew.com:8443/alayanew-dab57f9b-35f5-4dc1-afff-5cfd02esdsfe]/llama3-8b-instruct:1.0.3
# push
docker push [registry.hd-01.alayanew.com:8443/alayanew-dab57f9b-35f5-4dc1-afff-5cfd02esdsfe]/llama3-8b-instruct:1.0.3
k8s资源部署
1. 声明配置文件
# 声明弹性容器集群配置
export KUBECONFIG="[/path/to/kubeconfig]"
2. 创建namespace
# 创建namespace
kubectl create namespace nim
3. 创建secret资源
3.1 harbor仓库secret
# 创建secret资源
kubectl create -f sd_harbor_secret.yaml
# 检查secret资源是否创建成功
kubectl get secret -n nim
3.2 nim秘钥
创建拉取模型参数密钥, 用于NIM镜像启动后访问NGC仓库下载模型参数文件
kubectl -n nim create secret docker-registry registry-secret
--docker-server=nvcr.io
--docker-username='$oauthtoken'
--docker-password=$NGC_API_KEY
kubectl -n nim create secret generic ngc-api --from-literal=NGC_API_KEY=$NGC_API_KEY
4. 创建deployment
# 创建deploy资源
kubectl apply -f nim-demployment.yaml
# 检查资源是否创建成功
kubectl get all -n nim
5. 同步模型参数文件
从对象存储中下载模型参数到pod内指定目录(非必选, 在无法访问外部网络或者外网下载速度较慢时可选择使用)。
对象存储的使用请参考文档使用rclone管理对象存储。
# 下载llama3-8b模型文件到/opt/nim/.cache/目录
rclone -v copy luhq:/models01/llama3-8b.tar.gz /opt/nim/.cache/
# 解压llama3-8b模型文件
cd /opt/nim/.cache/
tar -xzvf llama3-8b.tar.gz
6. 验证是否部署成功
退出pod,在宿主机上执行以下命令(请使用实际的pod名称),日志出现了http://0.0.0.0:8000,则部署成功。
kubectl logs [pod-names] -n nim
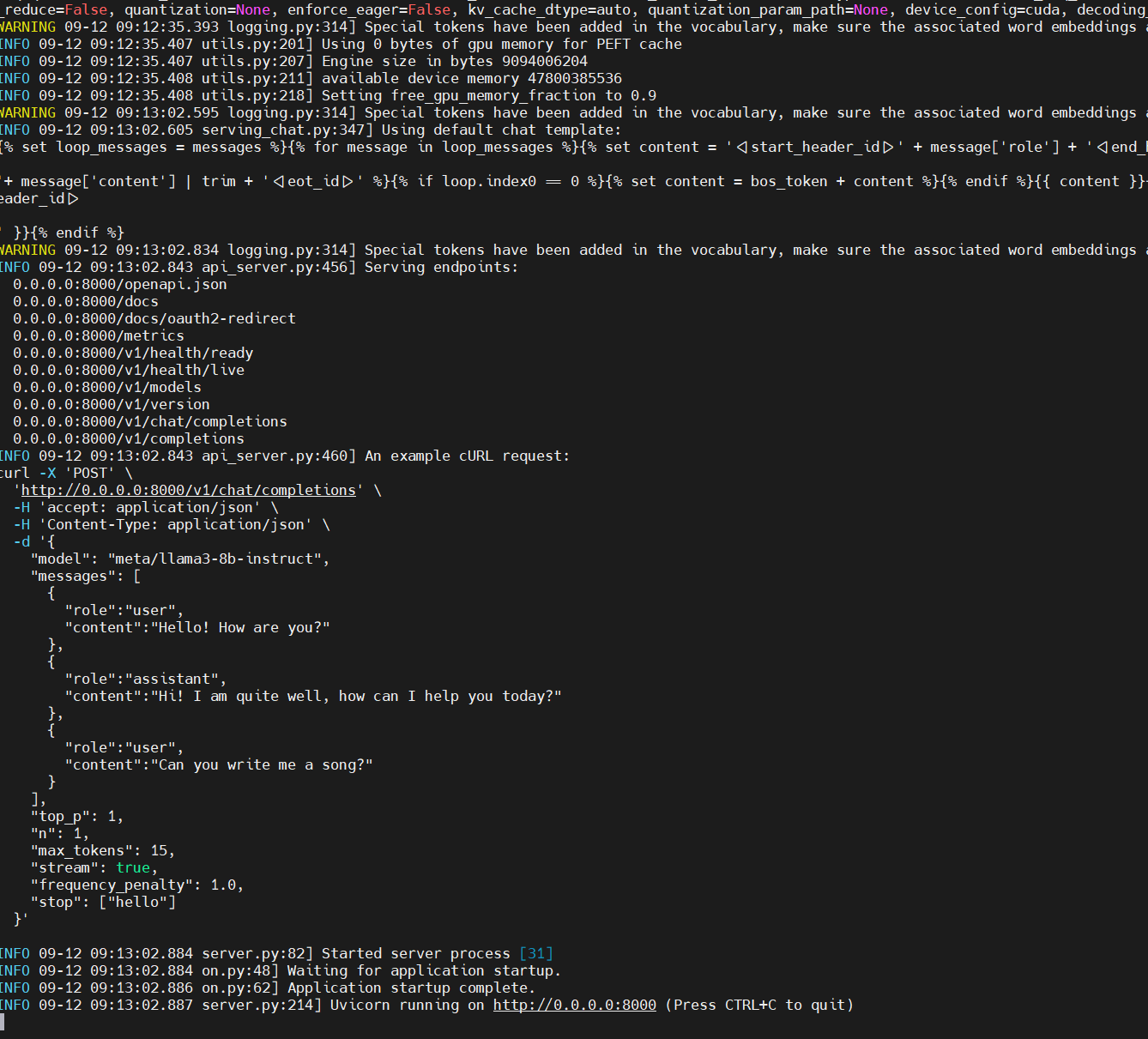
7. 创建Service
# 创建svc
kubectl create -f nim_svc.yaml
# 检查是否创建成功
kubectl get svc -n min
8. 创建ServiceExporter
# 创建svc
kubectl create -f nim_se_svc.yaml
# 检查是否创建成功
kubectl get ServiceExporter -n min
推理服务
获取公网url
# kubectl get serviceexporter -n nim
NAME AGE
nim-se-svc 9m3s
# kubectl describe serviceexporter nim-se-svc -nim
Name: nim-se-svc
Namespace: nim
Labels: <none>
Annotations: <none>
API Version: osm.datacanvas.com/v1alpha1
Kind: ServiceExporter
Metadata:
Creation Timestamp: 2024-12-11T06:02:39Z
Generation: 1
Resource Version: 20756
UID: c60c7e52-0703-40c0-80f4-205a2886a522
Spec:
Service Name: nim-svc
Service Port: 8888
Status:
Conditions:
Last Transition Time: 2024-12-11T06:02:39Z
Message: IngressRoute successfully updated, url: https://nim-svc-x-nim-x-vc2qofwoe524.sproxy.hd-01.alayanew.com
Reason: IngressRouteUpdated
Status: True
Type: Ready
Events: <none>
在这个示例中,公网的url为:https://nim-svc-x-nim-x-vc2qofwoe524.sproxy.hd-01.alayanew.com
通过ServiceExporter发布的服务,默认的端口为22443。
所以最终的url为:https://nim-svc-x-nim-x-vc2qofwoe524.sproxy.hd-01.alayanew.com:22443
访问方式一:curl
curl -X 'POST' \
'https://nim-svc-x-nim-x-vc2qofwoe524.sproxy.hd-01.alayanew.com:22443/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama3-8b-instruct",
"messages": [
{
"role":"user",
"content":"Hello! How are you?"
},
{
"role":"assistant",
"content":"Hi! I am quite well, how can I help you today?"
},
{
"role":"user",
"content":"Can you write me a song?"
}
],
"top_p": 1,
"n": 1,
"max_tokens": 15,
"stream": true,
"frequency_penalty": 1.0,
"stop": ["hello"]
}'
访问方式二:api
from openai import OpenAI
#api_key="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"
client = OpenAI(base_url="https://nim-svc-x-nim-x-vc2qofwoe524.sproxy.hd-01.alayanew.com:22443/v1/chat/completions",
api_key="not-used")
messages = [
{"role": "user", "content": "Hello! How are you?"},
{"role": "assistant", "content": "Hi! I am quite well, how can I help you today?"},
{"role": "user", "content": "Write a short limerick about the wonders of GPU computing."}
]
chat_response = client.chat.completions.create(
model="meta/llama3-8b-instruct",
messages=messages,
max_tokens=32,
stream=False
)
assistant_message = chat_response.choices[0].message
print(assistant_message)