通过云容器实例进行机器学习
本章节介绍如何通过云容器实例进行机器学习。
前提条件
- 用户已经获取 Alaya NeW 企业账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前企业账号的余额充裕,可满足用户使用云容器实例服务的需要。如需了解最新的活动详情及费用信息,请联系我们。
操作步骤
步骤一:创建云容器实例
-
使用已注册的企业账号登录 Alaya NeW 平台,单击“产品 > 计算 > 云容器实例”,进入云容器实例页面。
-
单击“新建云容器”,进入[云容器实例]开通页面,配置实例名称,实例描述,智算中心等参数。 本示例中按如下要求配置各项参数。其中:
-
资源类型:选择“云容器实例-GPU-H800A-1卡”即可。 -
其他参数配置请参考下表进行设置。
配置参数 参数说明 配置要求 是否必须 实例名称 指定云容器的标识符,用于在系统中唯一识别该云容器。 字母开头,支持字母、数字、连字符(-)、下划线(_),长度应为4-20字符。 是 实例描述 云容器的功能、用途、配置等信息进行简要说明的文字描述。 无。 否 智算中心 用于支持云容器实例服务的数据中心。 选择可用的数据中心,例如:北京三区、北京五区等。 是 付费方式 使用数据中心资源的计费方式。 选择系统目前支持的计费方式,当前为按量计费。 是 资源配置 详细列出算力中心的资源规格,包括资源类型、GPU型号、计算资源规格、磁盘配置等。 选择满足所需的资源。 是 存储配置 可以选择云容器实例中的挂载NAS型存储。 选择需要挂载NAS型存储。 否 镜像 支持公共镜像(包括基础镜像和应用镜像)和私有镜像,可根据需要选择镜像类型。 - 是 其他配置 支持配置环境变量的建和值,同时支持开启云容器实例的自动关机和自动释放。 - 否
-
-
云容器实例参数配置完成后,单击“立即开通”按钮,然后在弹出的对话框中确认已配置的参数,确认无误后单击“确定”,即可完成云容器实例开通操作。
您可以在[计算/云容器实例]页面查看已创建的云容器实例,当云容器实例状态为“运行中”时,表示云容器实例创建成功且可正常使用。
步骤二:进行机器学习
-
进入jupyter。
在“云容器实例”页面的“容器列表”页签找到目标云容器实例,单击右侧的Jupyter图标。
-
执行如下操作,构建机器学习训练。
代码详情
import math
import time
import random
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
from pathlib import Path
# 设置随机种子以确保可重复性
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
set_seed(42)
def make_moons(n_samples=1000, noise=0.2):
"""手工实现 make_moons,不依赖 sklearn"""
n_samples_out = n_samples // 2
n_samples_in = n_samples - n_samples_out
outer_circ_x = np.cos(np.linspace(0, math.pi, n_samples_out))
outer_circ_y = np.sin(np.linspace(0, math.pi, n_samples_out))
inner_circ_x = 1 - np.cos(np.linspace(0, math.pi, n_samples_in))
inner_circ_y = 1 - np.sin(np.linspace(0, math.pi, n_samples_in)) - .5
X = np.vstack([np.append(outer_circ_x, inner_circ_x),
np.append(outer_circ_y, inner_circ_y)]).T.astype(np.float32)
y = np.hstack([np.zeros(n_samples_out, dtype=np.float32),
np.ones(n_samples_in, dtype=np.float32)])
if noise > 0:
X += np.random.normal(0, noise, X.shape)
return X, y
# 创建数据集
X, y = make_moons(1200, noise=0.25)
# 划分训练集和验证集
perm = np.random.permutation(len(X))
train_size = int(0.8 * len(X))
X_train, y_train = X[perm[:train_size]], y[perm[:train_size]]
X_val, y_val = X[perm[train_size:]], y[perm[train_size:]]
# 创建数据加载器
train_ds = TensorDataset(torch.from_numpy(X_train), torch.from_numpy(y_train))
val_ds = TensorDataset(torch.from_numpy(X_val), torch.from_numpy(y_val))
train_loader = DataLoader(train_ds, batch_size=64, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=256, shuffle=False)
class MLP(nn.Module):
def __init__(self, in_dim=2, hidden=128, dropout_rate=0.2):
super().__init__()
self.net = nn.Sequential(
nn.Linear(in_dim, hidden),
nn.ReLU(),
nn.Dropout(dropout_rate),
nn.Linear(hidden, hidden//2),
nn.ReLU(),
nn.Dropout(dropout_rate),
nn.Linear(hidden//2, 1)
)
def forward(self, x):
return self.net(x).squeeze(1)
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# 初始化模型、损失函数和优化器
model = MLP(hidden=128, dropout_rate=0.2).to(device)
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='min', factor=0.5, patience=10
)
# 训练参数
EPOCHS = 200
PLOT_FREQ = 5 # 每5个epoch画一次图
best_val_loss = float('inf')
patience_counter = 0
patience = 20 # 早停耐心值
# 创建保存模型的目录
Path("checkpoints").mkdir(exist_ok=True)
# 设置交互式绘图
plt.ion()
fig = plt.figure(figsize=(15, 6))
ax_loss = fig.add_subplot(1, 2, 1)
ax_boundary = fig.add_subplot(1, 2, 2)
train_losses, val_losses = [], []
train_accs, val_accs = [], []
def calculate_accuracy(model, data_loader):
"""计算模型在给定数据加载器上的准确率"""
model.eval()
correct = 0
total = 0
with torch.no_grad():
for xb, yb in data_loader:
xb, yb = xb.to(device), yb.to(device)
outputs = torch.sigmoid(model(xb))
predicted = (outputs > 0.5).float()
total += yb.size(0)
correct += (predicted == yb).sum().item()
return correct / total
def plot_boundary(ax, epoch):
"""绘制决策边界"""
ax.clear()
# 创建网格
h = 0.02
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# 预测网格点的类别
grid = torch.from_numpy(np.c_[xx.ravel(), yy.ravel()]).float().to(device)
with torch.no_grad():
Z = torch.sigmoid(model(grid)).cpu().numpy().reshape(xx.shape)
# 绘制决策边界
contour = ax.contourf(xx, yy, Z, levels=50, cmap='RdBu', alpha=0.7)
# 绘制数据点
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='bwr',
edgecolors='k', marker='o', label='Train', alpha=0.7)
ax.scatter(X_val[:, 0], X_val[:, 1], c=y_val, cmap='bwr',
edgecolors='k', marker='x', label='Val', alpha=0.7)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_title(f'Decision Boundary (Epoch {epoch})')
ax.legend()
plt.colorbar(contour, ax=ax)
def plot_metrics(ax):
"""绘制损失和准确率曲线"""
ax.clear()
# 绘制损失
ax.plot(train_losses, label='Train Loss', color='blue', linestyle='-')
ax.plot(val_losses, label='Val Loss', color='red', linestyle='-')
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss', color='black')
ax.tick_params(axis='y', labelcolor='black')
ax.legend(loc='upper left')
# 创建第二个y轴用于准确率
ax2 = ax.twinx()
ax2.plot(train_accs, label='Train Acc', color='blue', linestyle='--')
ax2.plot(val_accs, label='Val Acc', color='red', linestyle='--')
ax2.set_ylabel('Accuracy', color='black')
ax2.tick_params(axis='y', labelcolor='black')
ax2.legend(loc='upper right')
ax.set_title('Training Metrics')
ax.grid(True)
# 训练循环
start_time = time.time()
for epoch in range(1, EPOCHS + 1):
# 训练阶段
model.train()
epoch_loss = 0.
for xb, yb in train_loader:
xb, yb = xb.to(device), yb.to(device)
optimizer.zero_grad()
logits = model(xb)
loss = criterion(logits, yb)
loss.backward()
optimizer.step()
epoch_loss += loss.item() * xb.size(0)
train_loss = epoch_loss / len(train_loader.dataset)
train_losses.append(train_loss)
# 验证阶段
model.eval()
epoch_loss = 0.
with torch.no_grad():
for xb, yb in val_loader:
xb, yb = xb.to(device), yb.to(device)
logits = model(xb)
loss = criterion(logits, yb)
epoch_loss += loss.item() * xb.size(0)
val_loss = epoch_loss / len(val_loader.dataset)
val_losses.append(val_loss)
# 计算准确率
train_acc = calculate_accuracy(model, train_loader)
val_acc = calculate_accuracy(model, val_loader)
train_accs.append(train_acc)
val_accs.append(val_acc)
# 学习率调度
scheduler.step(val_loss)
# 打印进度
if epoch % 10 == 0 or epoch == 1:
print(f'Epoch {epoch:03d}/{EPOCHS} | '
f'Train Loss: {train_loss:.4f} | Val Loss: {val_loss:.4f} | '
f'Train Acc: {train_acc:.3f} | Val Acc: {val_acc:.3f} | '
f'LR: {optimizer.param_groups[0]["lr"]:.2e}')
# 保存最佳模型
if val_loss < best_val_loss:
best_val_loss = val_loss
patience_counter = 0
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': val_loss,
}, 'checkpoints/best_model.pth')
else:
patience_counter += 1
# 早停检查
if patience_counter >= patience:
print(f"Early stopping at epoch {epoch}")
break
# 可视化
if epoch % PLOT_FREQ == 0 or epoch == 1 or epoch == EPOCHS:
plot_metrics(ax_loss)
plot_boundary(ax_boundary, epoch)
fig.tight_layout()
plt.pause(0.01)
# 训练结束
end_time = time.time()
print(f"Training completed in {end_time - start_time:.2f} seconds")
# 关闭交互模式
plt.ioff()
# 加载最佳模型
checkpoint = torch.load('checkpoints/best_model.pth')
model.load_state_dict(checkpoint['model_state_dict'])
print(f"Loaded best model from epoch {checkpoint['epoch']} with val loss {checkpoint['loss']:.4f}")
# 最终评估
model.eval()
with torch.no_grad():
# 在整个数据集上评估
X_tensor = torch.from_numpy(X).to(device)
y_pred_proba = torch.sigmoid(model(X_tensor)).cpu().numpy()
y_pred = (y_pred_proba > 0.5).astype(int)
# 计算准确率
accuracy = (y_pred == y).mean()
print(f'Final accuracy on full data: {accuracy:.3f}')
# 显示最终图表
plt.figure(figsize=(15, 6))
# 损失和准确率曲线
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss', color='blue', linestyle='-')
plt.plot(val_losses, label='Val Loss', color='red', linestyle='-')
plt.xlabel('Epoch')
plt.ylabel('Loss', color='black')
plt.tick_params(axis='y', labelcolor='black')
plt.legend(loc='upper left')
plt.twinx()
plt.plot(train_accs, label='Train Acc', color='blue', linestyle='--')
plt.plot(val_accs, label='Val Acc', color='red', linestyle='--')
plt.ylabel('Accuracy', color='black')
plt.tick_params(axis='y', labelcolor='black')
plt.legend(loc='upper right')
plt.title('Training Metrics')
plt.grid(True)
# 决策边界
plt.subplot(1, 2, 2)
h = 0.02
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
grid = torch.from_numpy(np.c_[xx.ravel(), yy.ravel()]).float().to(device)
with torch.no_grad():
Z = torch.sigmoid(model(grid)).cpu().numpy().reshape(xx.shape)
plt.contourf(xx, yy, Z, levels=50, cmap='RdBu', alpha=0.7)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='bwr',
edgecolors='k', marker='o', label='Train', alpha=0.7)
plt.scatter(X_val[:, 0], X_val[:, 1], c=y_val, cmap='bwr',
edgecolors='k', marker='x', label='Val', alpha=0.7)
plt.colorbar()
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title('Final Decision Boundary')
plt.legend()
plt.tight_layout()
plt.show() -
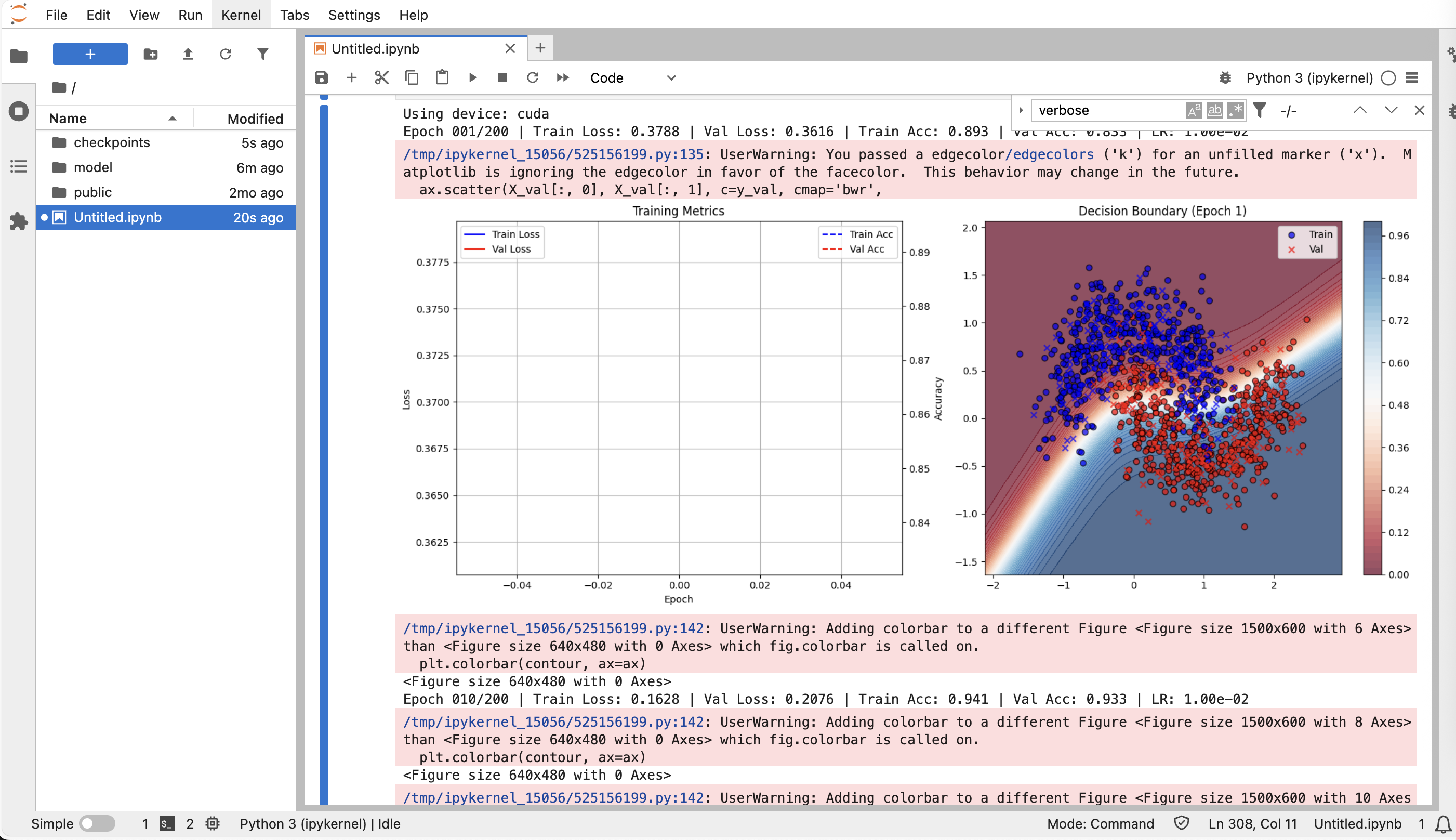
如下图所示为机器学习的输出结果。