模型管理
Lab训练好并发布至服务的模型、直接导入的模型文件,从模型市场添加的模型,以及通过Docker Image和镜像仓库两种导入方式获取的镜像模型,都需要执行审核操作,并在模型管理列表进行统一管理。平台的许多功能都依赖模型管理实现,例如在线服务、跑批服务、模型评估、模型监控等。
模型管理具有如下特性:
- 模型审核和监管:对从Lab训练的模型、导入的模型或从模型市场添加的模型执行审核,确保其符合安全、隐私、合规等标准。
- 模型评估:在上线前支持对模型性能评估,包括模板评估和自定义评估。
- 模型量化:在保持模型性能的前提下,减少模型参数的精度,以满足存储和计算需求。
导入模型
导入模型简介
导入方式支持将如下几种类型的模型导入模型仓库:
- 机器学习模型:
- DCPipeline 模型文件,适用于平台3.2或以上版本生成的基于DCPipeline的zip文件
- 复杂模型文件,适用于平台3.2以前版本通过自定义算子生成的由模型文件与modelserving.py文件组成的zip文件,详见2.4.2.3 导入复杂模型
- DeepTables 模型文件
- PMML 模型文件
- ONNX 模型文件
- 基于Sklearn的 pkl 模型文件,适用于平台3.2以前版本或Sklearn生成的pkl文件
- 深度学习模型:
- DCPipeline 模型文件,适用于平台3.2或以上版本生成的基于DCPipeline的zip文件
- 杂模型文件,适用于平台3.2以前版本通过自定义算子生成的由模型文件与modelserving.py文件组成的zip文件,详见2.4.2.3 导入复杂模型
- ONNX 模型文件
- 基于PyTorch的 pth 模型文件,详见2.4.2.2 导入单文件的pth的PyTorch模型
- 预训练模型:
- 基于TensorFlow2的 ckpt 模型文件
- 基于TensorFlow2的 h5 或 SaveModel模型文件
- 基于PyTorch的 pth 模型文件
场景描述
将从Lab模型组中导出的“DT神经网络_二分类”模型导入到服务“Doc-机器学习-模型文件”中。
前提条件
- 待导入的模型与服务的特征形状需要一致。
操作步骤
-
在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
-
在页面左侧的“侧边栏”区域,选择模型管理,系统跳转到模型管理列表页面。
-
在“模型管理”列表页面,单击添加模型。
-
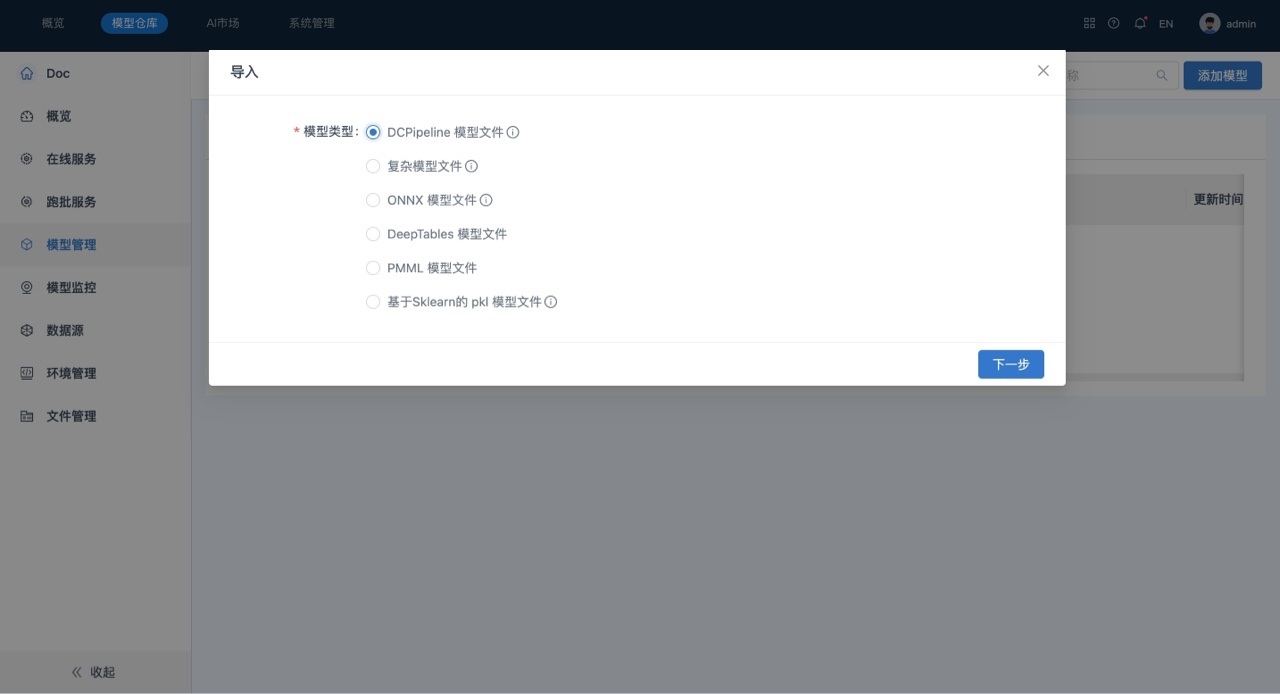
选择“模型类型”为“DCPipeline 模型文件”,并将待导入的模型文件拽到文件上传区域。
-
单击下一步,系统自动解析导入的模型文件,并允许用户根据实际情况进行修改,如下所示:
-
单击下一步,确认并设置变量信息
系统从模型文件中解析的变量包括“特征变量”和“目标变量”两种。- 自动推断:系统会自动从导入的模型文件中解析模型的变量信息,当用户修改变量后,可以通过该方式将变量恢复到系统自动推断的状态。 若服务中模型非空,则导入时解析出的模型的变量需要与服务的变量一致,包括变量名称与类型,才可以导入到该服务中,若服务为空,则会将导入的第一个模型的变量作为服务的变量。
-
单击下一步,系统提示导入结果。
-
单击关闭,完成导入。
导入单文件的pth的PyTorch模型
为了辅助训练的PyTorch模型导入平台中,可通过以下三个步骤(定义模型、定义脚本、文件打包),将训练的模型打包为zip,然后导入平台。
- 定义模型:PyTorch模型分为顺序模型和自定义模型,当自定义模型时需要继承
nn.Module来定义模型,然后实例化模型进行模型训练,并将权重和偏差保存为pth文件;当加载模型文件(pth)时需要先实例化模型,所以需要提供模型是如何定义的,通常提供单独的py文件,在py文件中定义模型结构,详情见以下定义模型模块。 - 定义脚本:平台提供了针对PyTorch模型导入的脚本文件(在模型导入模块可以下载),脚本中需要填写模型加载、输入参数、输出参数, 详情见定义脚本模块。
- 文件打包:在windows平台可通过winrar、7zip等压缩工具,将目录打包为zip,详情见文件打包模块。
定义模型
PyTorch模型可分为2类模型:顺序模型、自定义模型。
-
顺序模型:nn.Sequential模型
nn.Sequential为pytorch内置模型,模型定义如下示例model = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
) -
自定义模型:继承nn.Module自定义模型
在模型中可定义forward方法,forward中可定义多个输入参数,返回值也可定多义个输出值。 模型定义如下示例,文件名称为pytorch_user_model_resnet_cifar10.py# -*- encoding: utf-8 -*-
import torch.nn as nn
# 3x3卷积 convolution
def conv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
# 残差模块 Residual block
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
# 残差网络 ResNet
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 16
self.conv = conv3x3(3, 16)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self.make_layer(block, 16, layers[0])
self.layer2 = self.make_layer(block, 32, layers[1], 2)
self.layer3 = self.make_layer(block, 64, layers[2], 2)
self.avg_pool = nn.AvgPool2d(8)
self.fc = nn.Linear(64, num_classes)
def make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if (stride != 1) or (self.in_channels != out_channels):
downsample = nn.Sequential(
conv3x3(self.in_channels, out_channels, stride=stride),
nn.BatchNorm2d(out_channels))
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels
for i in range(1, blocks):
layers.append(block(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv(x)
out = self.bn(out)
out = self.relu(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
定义脚本
脚本文件中定了3个方法:load、get_inputs、get_outputs
load:用于加载模型,在该方法中可实例化模型并加载模型文件(pth文件中保存的权重和偏差),接收一个path参数,可根据指定的path加载模型文件。get_inputs:用于定义模型的输入,依dict形式可指定多个输入,如果是tensor类型,一定要指定数据类型 (如float:torch.randn(1, 3, 32, 32).float())get_outputs:用于定义模型的输出,依dict形式可指定多个输出,如果是tensor类型,一定要指定数据类型 (如float:torch.randn(1, 10).float())
序贯模型与自定义模型脚本定义:
-
序贯模型 脚本文件名称
pytorch_model_import.py(注意:脚本名称、方法名称不可更改)import torch
import torch.nn as nn
class ModuleImporter(object):
def load(self, path=None):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
model.load_state_dict(torch.load(path, map_location=str(device)))
model.eval()
return model
def get_inputs(self):
x1 = torch.randn(10, 1).float()
inputs = {
"x1": x1
}
return inputs
def get_outputs(self):
outputs = {
"y": torch.randn(10, 1).float()
}
return outputs -
自定义 脚本文件名称
pytorch_model_import.py(注意:脚本名称、方法名称不可更改)import torch
import torch.nn as nn
from torch.backends import cudnn
class ModuleImporter(object):
def load(self, path=None):
from pytorch_user_model_resnet_cifar10 import ResidualBlock
from pytorch_user_model_resnet_cifar10 import ResNet
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = ResNet(ResidualBlock, [2, 2, 2])
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model, device_ids=[0, 1])
cudnn.benchmark = True
model.to(device)
model.load_state_dict(torch.load(path, map_location=str(device)))
model.eval()
return model
def get_inputs(self):
x1 = torch.randn(1, 3, 32, 32).float()
inputs = {
"x1": x1
}
return inputs
def get_outputs(self):
outputs = {
"y": torch.randn(1, 10).float()
}
return outputs
文件打包
目录结构如下,按照以下目录打包成zip:

- 模型定义:pytorch_user_model_resnet_cifar10.py
- 模型文件:model_resnet_cifar10.pth
- 脚本文件: pytorch_model_import.py
压缩后的目录如下:
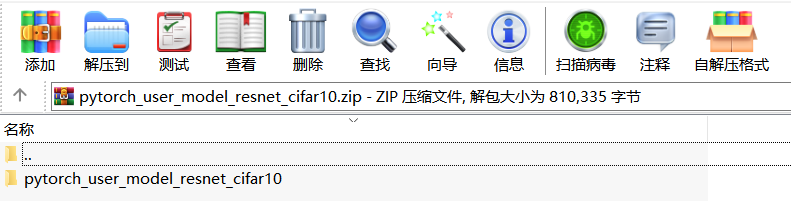
进入目录后:
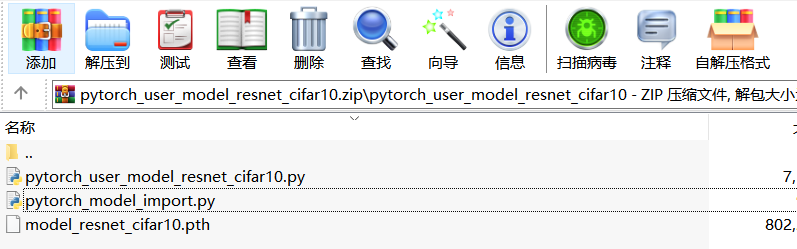
将以上压缩文件在平台上导入即可。
附导入脚本模板
文件名称为pytorch_model_import.py
import torch
import torch.nn as nn
from torch.backends import cudnn
class ModuleImporter(object):
r""" This is a script file to help users import the external training model into the platform.
The script provides three methods:
1.load:Instantiate models and load weights and biases
2、get_inputs:Get the input parameters of the model to get dtype and shape
3.get_outputs:Get the output parameters of the model to get dtype and shape
"""
def load(self, path=None):
"""
Instantiate models and load weights and biases
Args:
path: model file path,The file extension is usually pth
Returns:
The module with the converted `torch.nn.Module` layer
To make it easier to understand, here is a small example::
Example::
from pytorch_user_model_resnet_cifar10 import ResidualBlock
from pytorch_user_model_resnet_cifar10 import ResNet
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# create model
model = ResNet(ResidualBlock, [2, 2, 2])
# set GPU Parallel
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model, device_ids=[0, 1])
cudnn.benchmark = True
# load weights and biases
model.to(device)
model.load_state_dict(torch.load(path, map_location=str(device)))
model.eval()
"""
return None
def get_inputs(self):
"""Define the input of the model.
In the form of dict, multiple input parameters can be defined to get the dtype and shape of the input
To make it easier to understand, here is a small example::
Example::
# Multiple inputs defined in forward,
inputs = {
"x1": torch.randn(1, 3, 32, 32).float(),
"x2": 1
}
return inputs
"""
inputs = {
}
return inputs
def get_outputs(self):
"""Define the output of the model.
In the form of dict, multiple output can be defined to get the dtype and shape of the input
To make it easier to understand, here is a small example::
Example::
# Multiple outputs defined in forward
outputs = {
"y": torch.randn(1, 10).float()
}
return outputs
"""
outputs = {
}
return outputs
导入复杂模型
复杂模型文件,适用于通过model_serving.py自定义的复杂模型,文件格式为zip。 其中该复杂模型文件包括model_serving.py文件和model_serving.py代码中使用到的文件。
model_serving.py代码示例如下:
import os
import pandas as pd
# 必须含有一个class是叫 ModelServing,用户需要在 __init__ 方法中初始化加载模型
class ModelServing(object):
def __init__(self):
# base_dir是模型训练时的模型目录路径
self.base_dir = os.path.dirname(os.path.abspath(__file__)) + "/"
# 建议尽量在__init__方法中初始化模型,不要在predict方法中加载模型
print("初始化模型")
self.model = model
def predict(self, X: pd.DataFrame):
res_df = self.model.predict(X)
return res_df.values.tolist()
复杂模型示例:

其中model_serving.py代码如下:
import os
class ModelServing(object):
def __init__(self):
print("自定义模型:Init 模型")
base_dir = os.path.dirname(os.path.abspath(__file__))
import pickle as pkl
with open(os.path.join(base_dir, 'iris.pkl'), 'rb') as f:
self.model = pkl.loads(f.read(), encoding='iso-8859-1')
print("自定义模型:模型加载成功。")
def predict(self, X):
return self.model.predict(X)
导入镜像模型
模型仓库支持导入镜像模型,并可以部署上线。
导入方式支持如下两种:
- Docker Image:使用API将镜像导入到本地计算机或服务器中。
- 镜像仓库:镜像存储在一个镜像仓库中,从该仓库中拉取镜像到本地环境。
场景描述
将“mnist.tar”文件导入到服务“Doc-机器学习-镜像模型”中。
操作步骤
- 在“模型仓库”主界面,选择服务“Doc-机器学习-镜像模型”,进入该服务主页面。
- 在页面左侧的“侧边栏”区域,选择模型管理,系统跳转到模型管理列表页面。
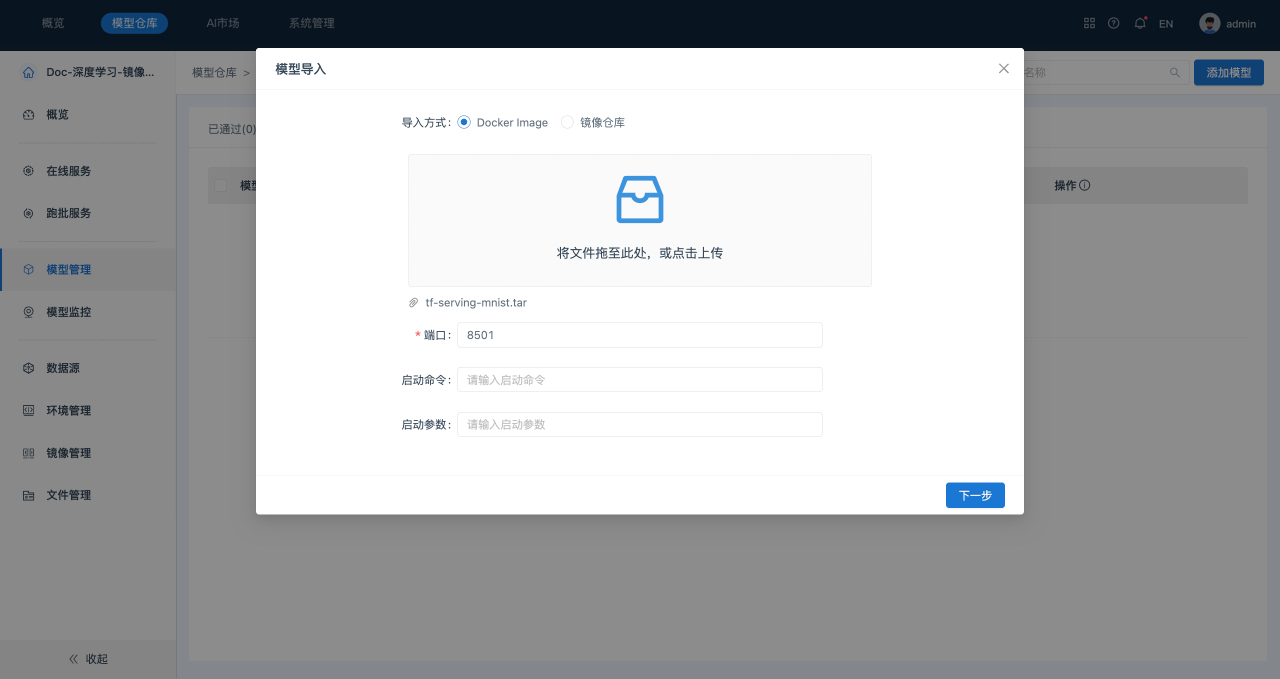
- 在“模型管理”列表页面,单击页面右上角的添加模型。
- 在“添加模型”弹出框中,选择“导入方式”为“Docker Image”,并将待导入的文件拖拽到文件上传区域,填写相关参数,如下所示:
- 单击下一步,确认并设置模型信息。如下所示:
- 单击下一步,系统提示导入结果。如下所示:
- 单击关闭,完成导入。
评估模型
创建模板评估
场景描述
在服务“Doc-机器学习-模型文件”中对模型进行模板评估。
前提条件
- 已经成功创建所需数据源“mysql-全表”。
- 已经成功导入所需模型“DT神经网络_二分类”。
- 待跑批模型“DT神经网络_二分类”已审核通过。
操作步骤
- 在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
- 在页面左侧的“侧边栏”区域,选择模型管理,系统跳转到“模型管理”列表页面。
- 在模型管理列表页面,单击 “模型名称”,进入到“模型”的详情页面,默认显示“模板评估”页签。
- 单击 “新建”,在“新建模板评估”窗口中填写相关参数,如下所示:
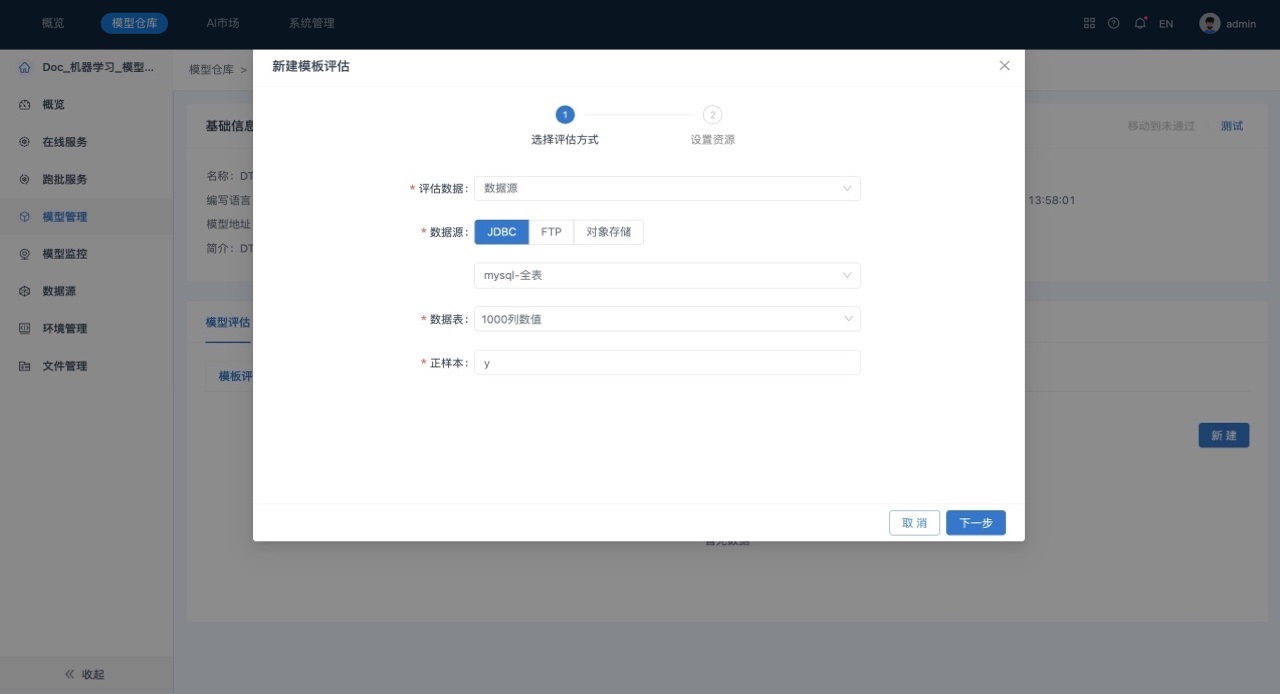
参数说明如下所示:
- 评估数据:选择模型评估的输入数据,支持选择数据源和文件管理。
- 单击下一步,进行模型评估资源配置。用户自定义是否使用GPU。
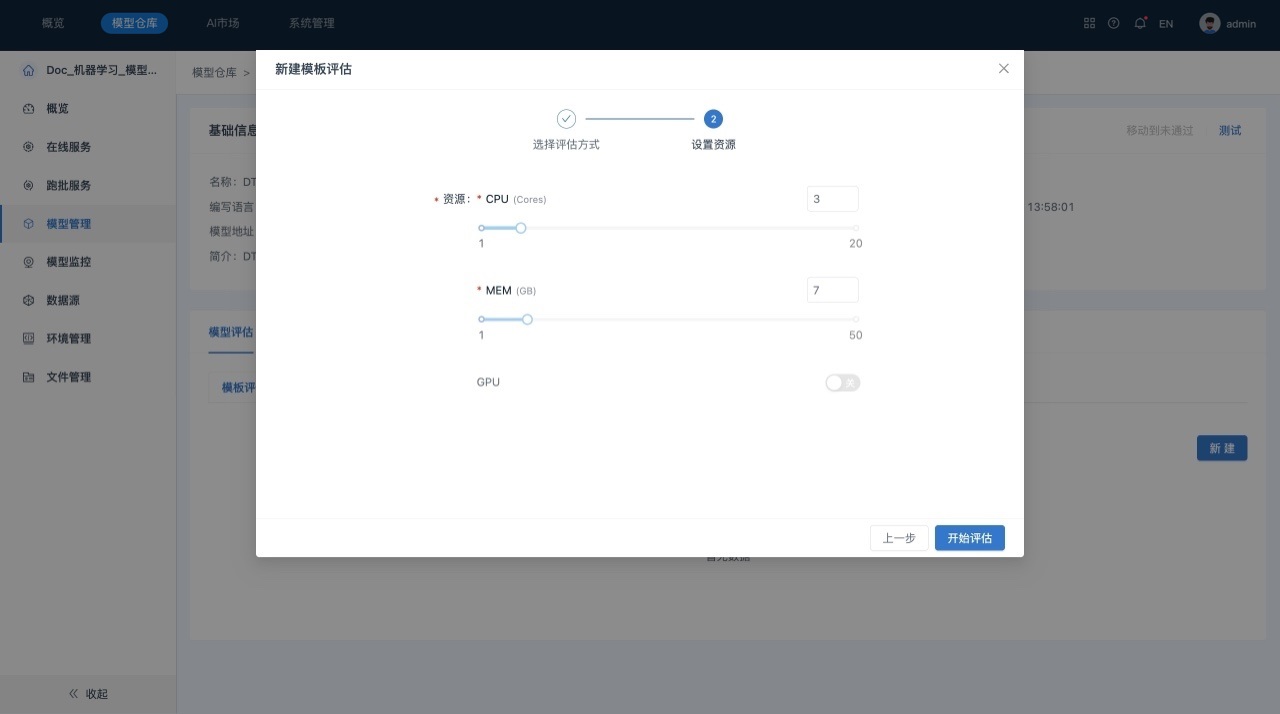
- 单击开始评估,系统自动开始模板评估任务。
后续操作
可以多次创建模板评估任务。
在完成模板评估后,在模型详情页面,“模板评估”页签里主要包括如下几部分内容:
1) 评估任务切换,点击评估下拉框切换不同模板评估任务。
2) 评估结果,模型的详细评估结果图表。
3) 基本信息,查看评估名称、类型、更新时间等信息。
4) 数据信息,查看评估时配置的输入数据。
创建自定义评估
模型文件的自定义评估
场景描述
在服务“Doc-机器学习-模型文件”中对模型进行自定义评估。
前提条件
- 已经成功创建所需数据源。
- 已经成功导入所需模型。
- 待评估模型已审核通过。
操作步骤
- 在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
- 在页面左侧的“侧边栏”区域,选择模型管理,系统跳转到“模型管理”列表页面。
- 在模型管理列表页面,单击 “模型名称”,进入到“模型”的详情页面,默认显示“模板评估”页签。
- 切换到“自定义评估”页签。单击 “编辑Jupyter Lab”,系统跳转到“自定义评估”页面,对资源和环境设置进行确认。
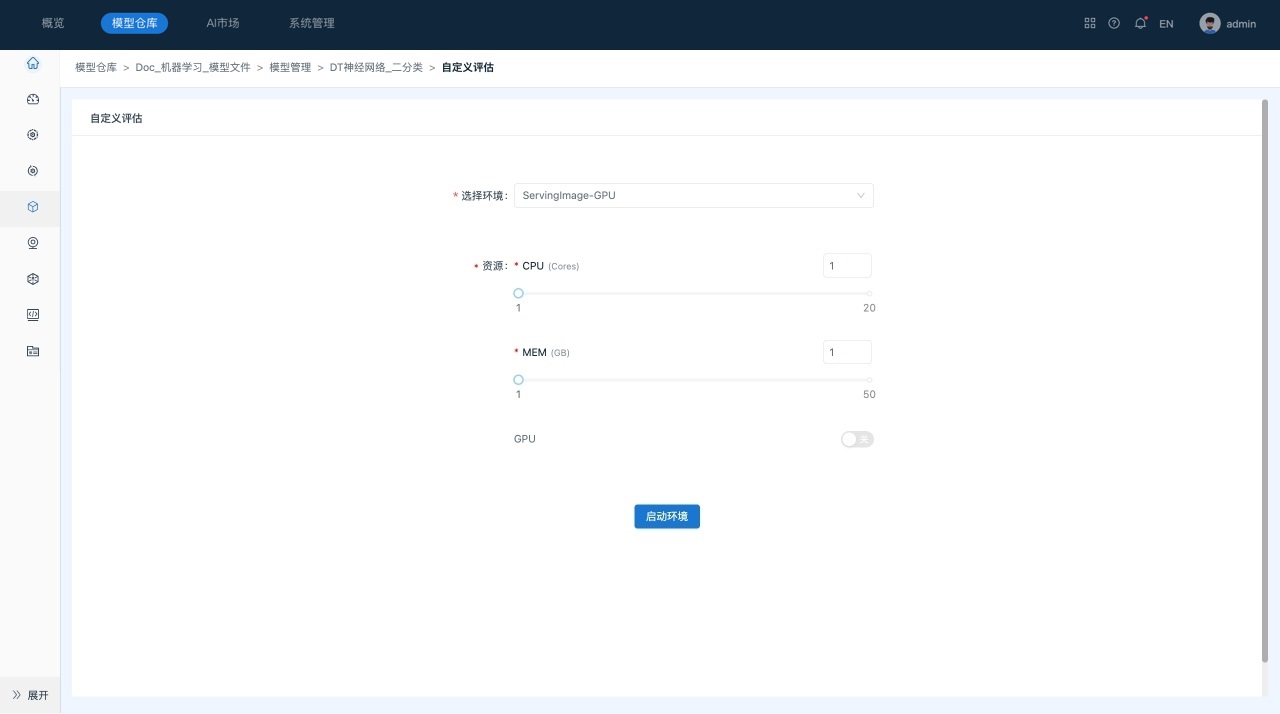
- 单击“启动环境”。
该操作会启动用户选择的环境,并在环境中启动Jupyter Lab服务。
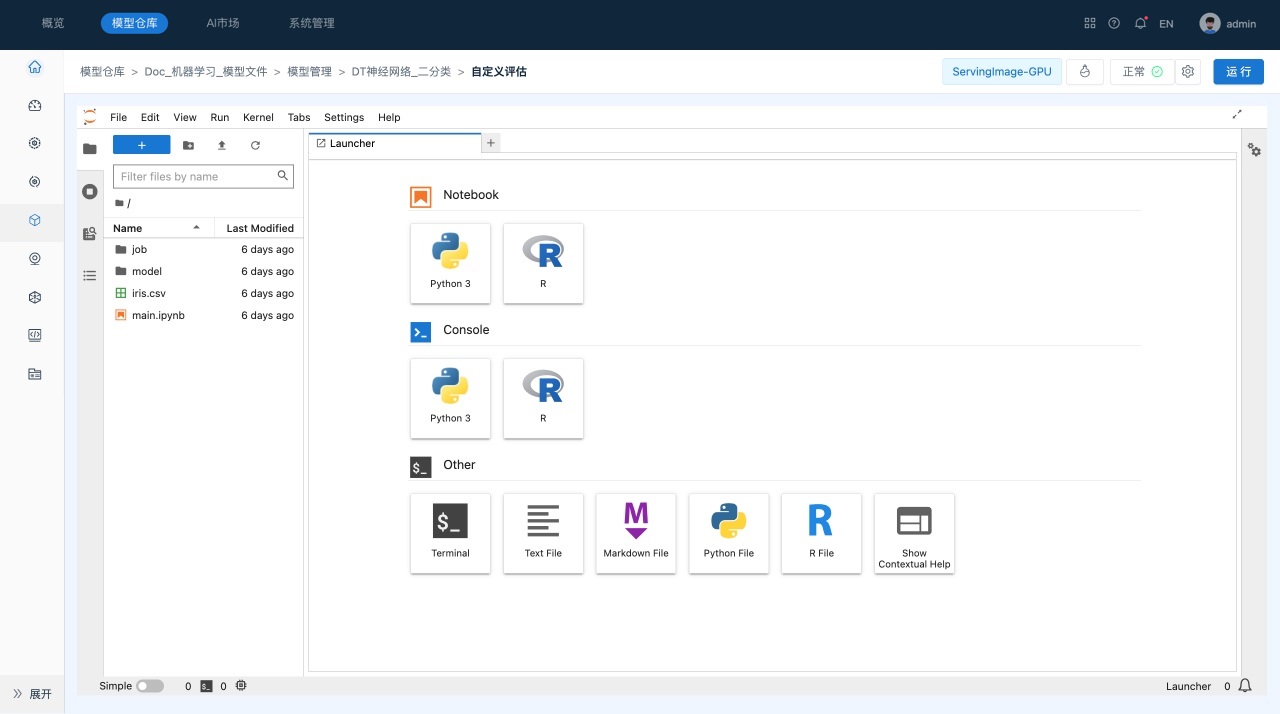
用户可以在启动界面查看启动日志,在启动后,系统会自动进入到Jupyter Lab界面,如下所示:
-
工具栏,提供了常用的管理功能。
-
资源管理器,包括文件管理、运行会话、命令帮助、服务等模块。
-
主工作区域,用于查看文件、编辑和运行Notebook等。
-
状态栏,显示当前后台运行的任务等信息。
-
完成编辑并保存后,单击右上角的运行,系统显示“运行”对话框,对需要发布的文件、运行模式设置、脚本资源和环境设置进行确认。
后续操作
可以多次编辑自定义评估,编辑后会生成新的自定义评估任务。
在完成自定义评估后,在模型详情页面,“自定义评估”页签里主要包括如下几部分内容:
1) 评估任务切换,点击评估下拉框切换不同自定义评估任务。
2) 评估结果,模型的详细评估结果图表。
3) 基本信息,查看评估名称、评估时用户选择的环境、类型、脚本文件、运行状态等信息。
4) 查看代码,查看单次运行的脚本内容。
5) 查看Jupyter Lab,可查看自定义的历史脚本内容。
6) 编辑Jupyter Lab,可进入Jupyter Lab再次编辑、运行脚本内容,单击“运行”后会生成新的自定义评估任务。
镜像模型的自定义评估
场景描述
在服务“Doc-机器学习-镜像模型”中对模型进行自定义评估。
前提条件
- 已经成功创建所需数据源。
- 已经成功导入所需模型。
- 待评估模型已审核通过。
操作步骤
- 在“模型仓库”主界面,选择服务“Doc-机器学习-镜像模型”,进入该服务主页面。
- 在页面左侧的“侧边栏”区域,选择模型管理,系统跳转到“模型管理”列表页面。
- 在模型管理列表页面,单击 “模型名称”,进入到“模型”的详情页面,默认显示“自定义评估”页签。
- 单击 “编辑Jupyter Lab”,系统跳转到“自定义评估”页面,对镜像模型资源、脚本资源和环境设置进行确认。
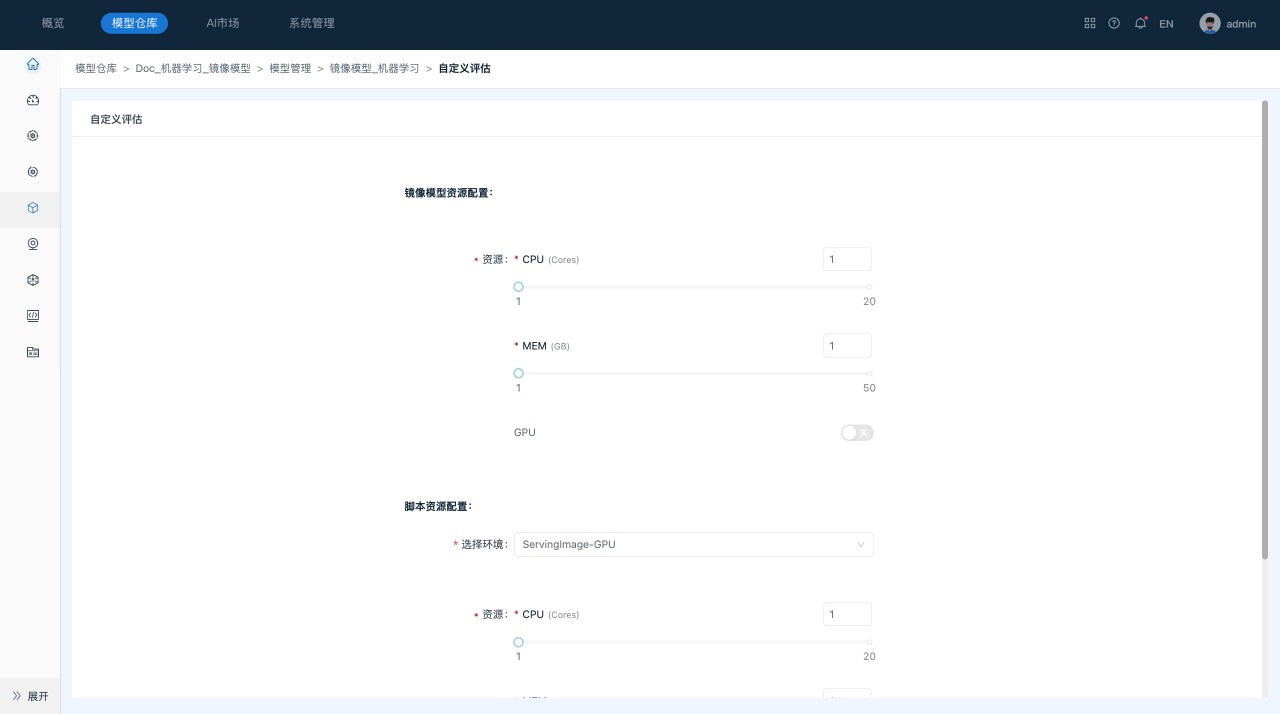
- 单击“启动环境”。
该操作会启动用户选择的环境,并在环境中启动Jupyter Lab服务。
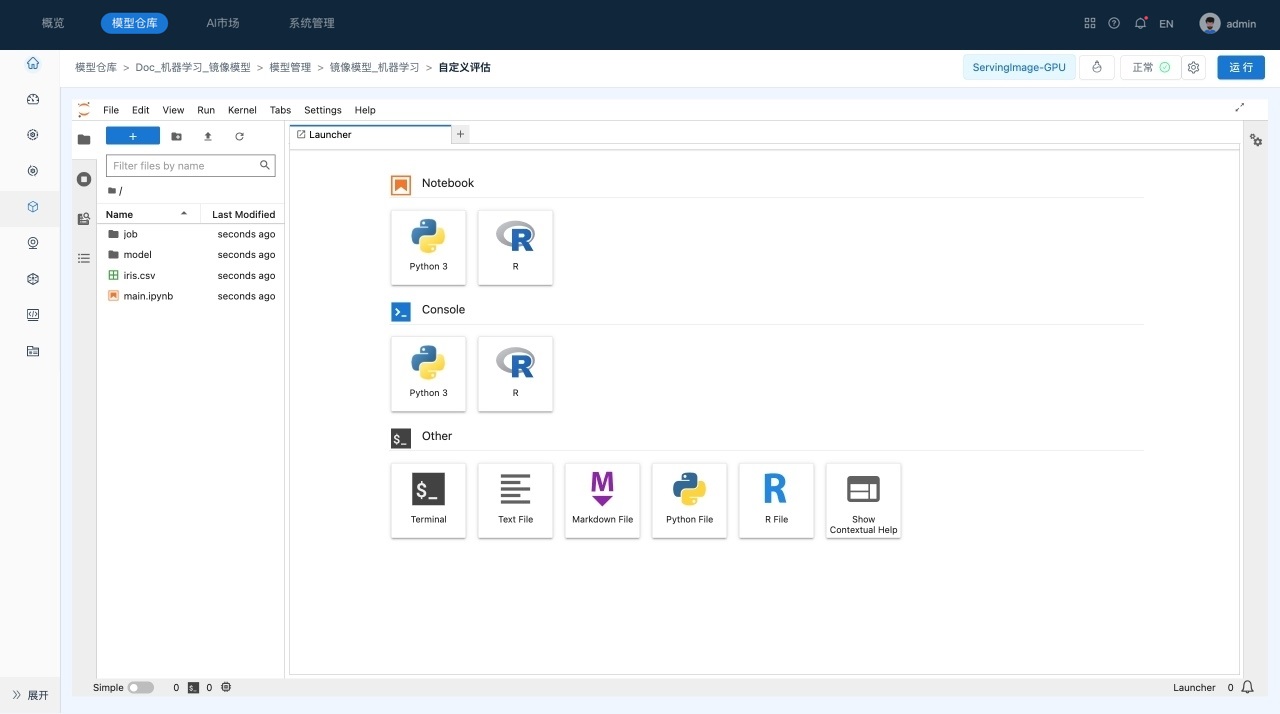
用户可以在启动界面查看启动日志,在启动后,系统会自动进入到Jupyter Lab界面,如下所示:
-
工具栏,提供了常用的管理功能。
-
资源管理器,包括文件管理、运行会话、命令帮助、服务等模块。
-
主工作区域,用于查看文件、编辑和运行Notebook等。
-
状态栏,显示当前后台运行的任务等信息。
-
完成编辑并保存后,单击右上角的运行,系统显示“运行”对话框,对需要发布的文件、运行模式设置、镜像模型资源、脚本资源和环境设置进行确认。
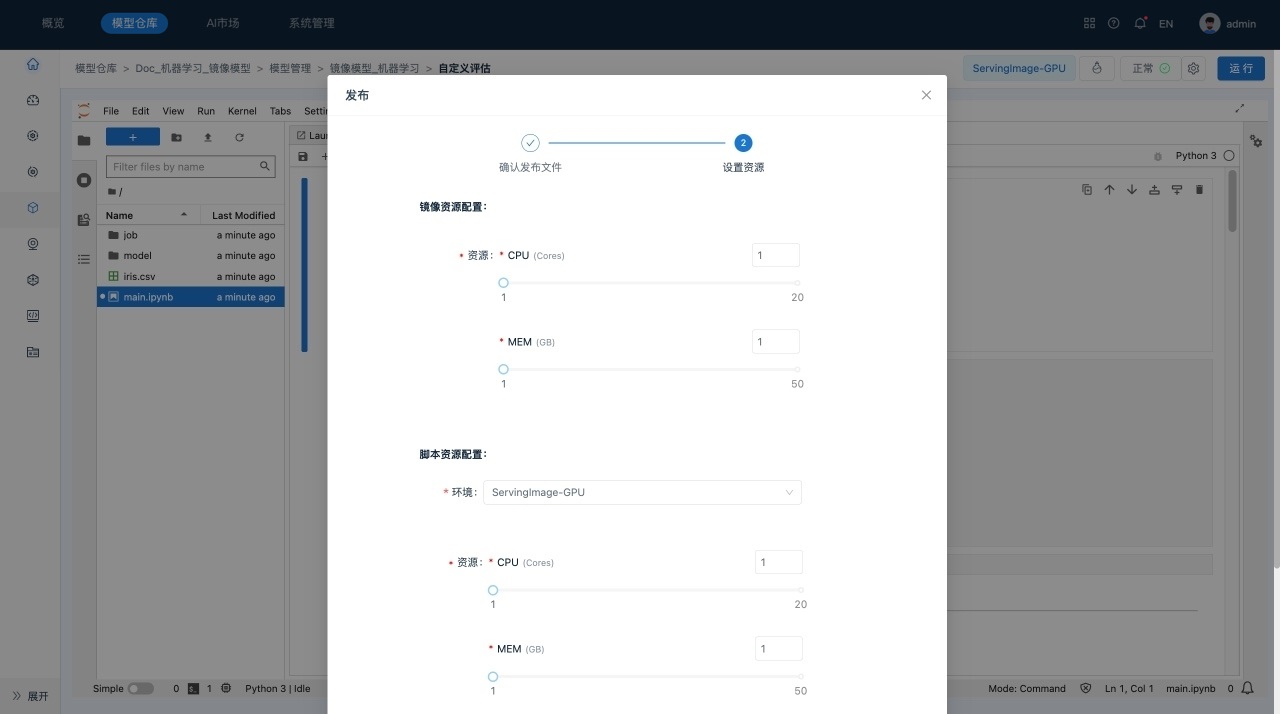
量化模型
系统目前支持对(模型文件)深度学习模型进行量化操作;当模型为审核通过状态方能对模型进行量化。量化功能目前仅支持目标检测、语义分割、实例分割等部分模型,且需要系统配置GPU才能启用此功能。
场景描述
量化“目标检测模型”模型。
前提条件
- 已经成功创建所需数据源“FTP”。
- 已经成功导入所需模型“目标检测模型”。
- 待量化模型“目标检测模型”已审核通过。
操作步骤
- 在“模型仓库”主界面,选择服务“Doc-深度学习-模型文件”,进入该服务主页面。
- 在页面左侧的“侧边栏”区域,选择模型管理,系统跳转到“模型管理”列表页面,默认显示“已通过”页签。
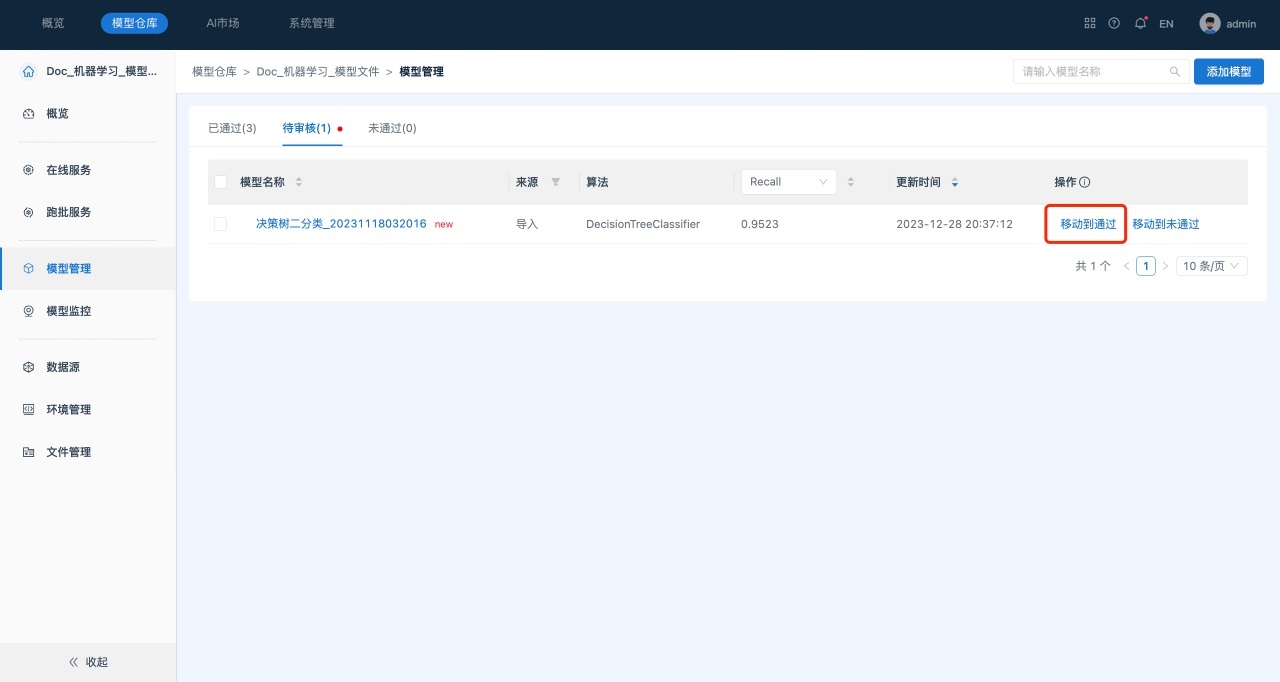
- 切换到“待审核”页签。
- 在各模型所在行单击“移动到通过”。将所选模型移动到“已通过”状态。
- 切换到“已通过”页签。在所选模型所在行单击“更多” > “量化”,系统显示“量化”对话框,如下所示:
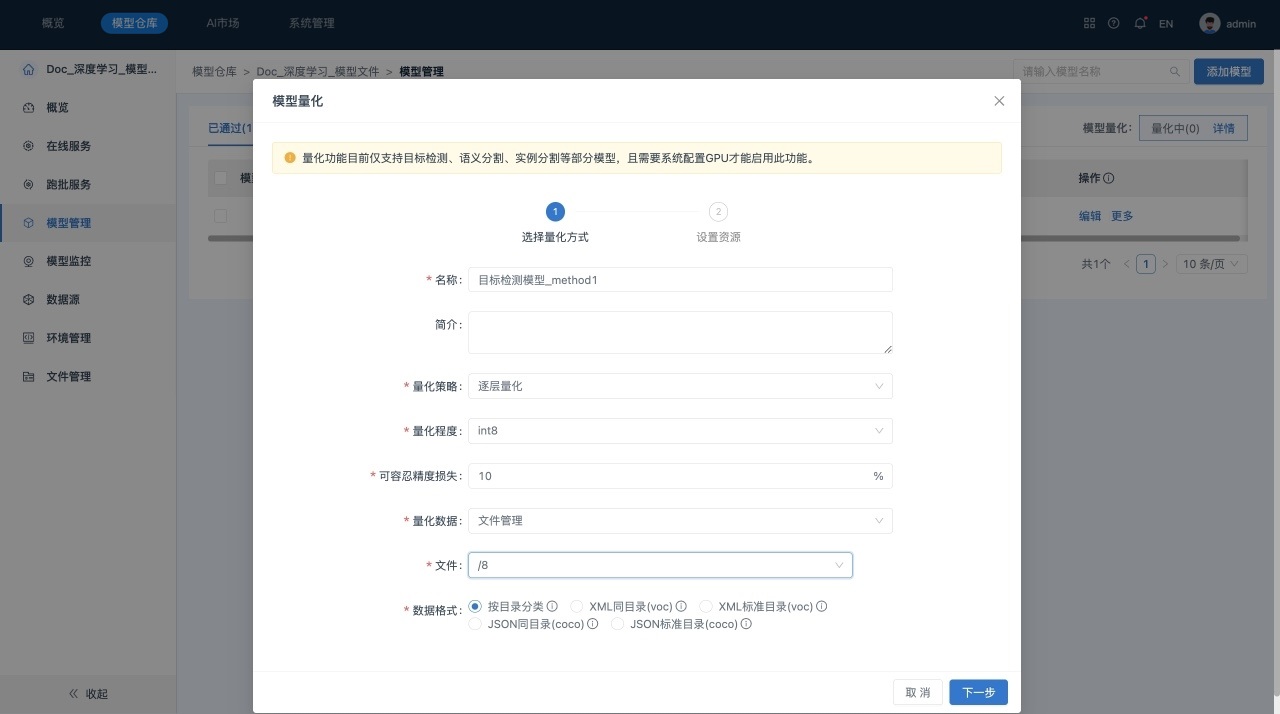
参数说明如下所示:
- 名称:用于标识一个量化模型。
- 简介:量化模型的描述信息。
- 量化策略:包括全部量化和逐层量化。
- 量化程度:支持int8。
- 可容忍的精度损失:默认5%,支持输入大于0小于100的数值。
- 量化数据:选择模型量化的输入数据,支持选择数据源和文件管理。
- 单击下一步,进行模型量化资源配置。量化需要配置GPU才能启用此功能。
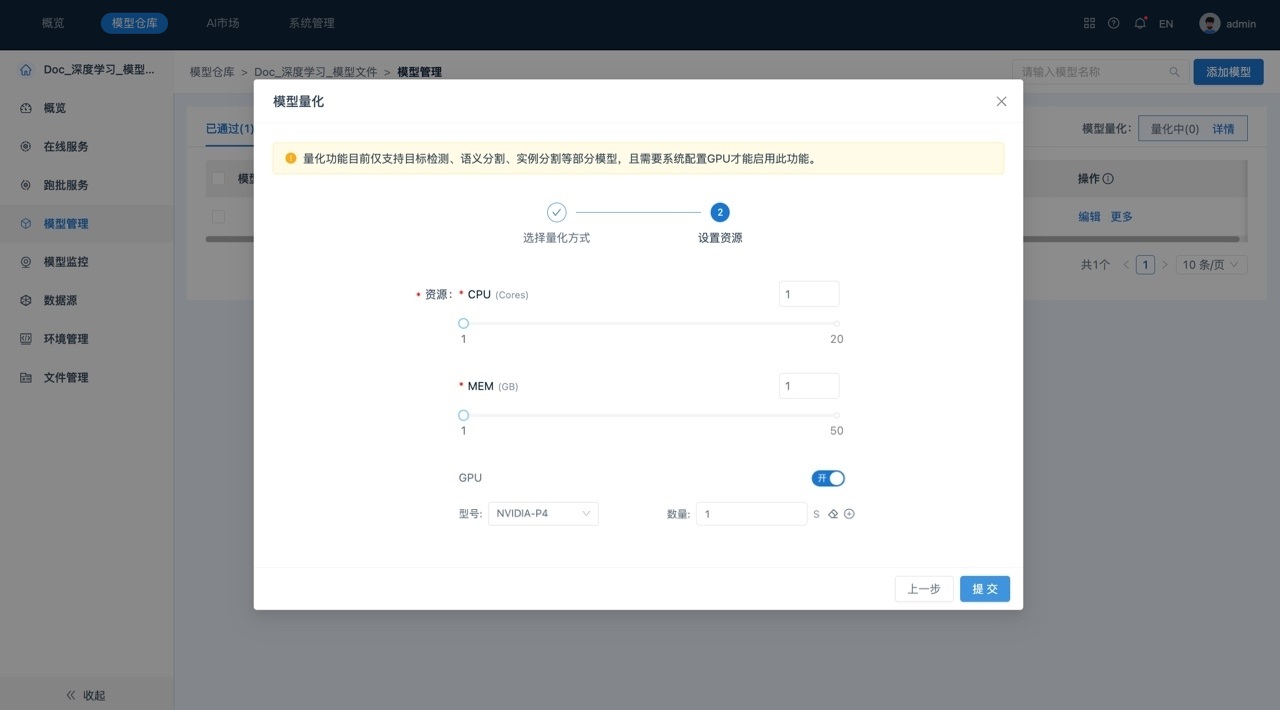
- 单击提交,系统自动开始模型量化任务。
- MaskRCNN和MaskRCNN_Seg模型不支持量化。
- 量化使用的GPU和部署时使用的GPU需保持型号一致。
后续操作
对同一个模型可以多次进行量化。
量化成功的模型将进入待审核列表,通过审核后会用于在线和跑批服务。
在完成模型量化配置后,在模型管理页面,页面右侧的“模型量化”处会有红点提示,提示量化中有新增模型。任务记录列表里主要包括如下三部分内容:
1) 模型名称,量化后的模型名称,在名称前置显示量化icon标识。
2) 原模型,点击进入原模型详情。如模型已被删除则不可点击。
3) 量化状态,支持对任务进行终止、重试、查看操作。
审核服务和模型
系统目前采用自审核机制;当模型为审核通过状态方能对模型进行在线服务或跑批服务。
场景描述
审核“DT神经网络_二分类”模型。
前提条件
- 拥有“模型审核”权限。
操作步骤
- 在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
- 在页面左侧的“侧边栏”区域,选择模型管理,系统跳转到“模型管理”列表页面,默认显示“已通过”页签。
- 切换到“待审核”页签。
- 在各模型所在行单击“移动到通过”,将所选模型移动到“已通过”状态。
查看模型详情
Lab训练好并发布至服务的模型、直接导入的模型,以及从模型市场添加的模型导入成功后,即可在模型详情页查看该模型的基本信息、模型文件、模型评估和模型pipeline。
场景描述
查看“DT神经网络_二分类”的模型详情。
操作步骤
- 在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
- 在页面左侧的“侧边栏”区域,选择模型管理,系统跳转到“模型管理”列表页面。
- 在模型管理列表页面,单击 “模型名称”,进入到“模型”的详情页面。如下所示:
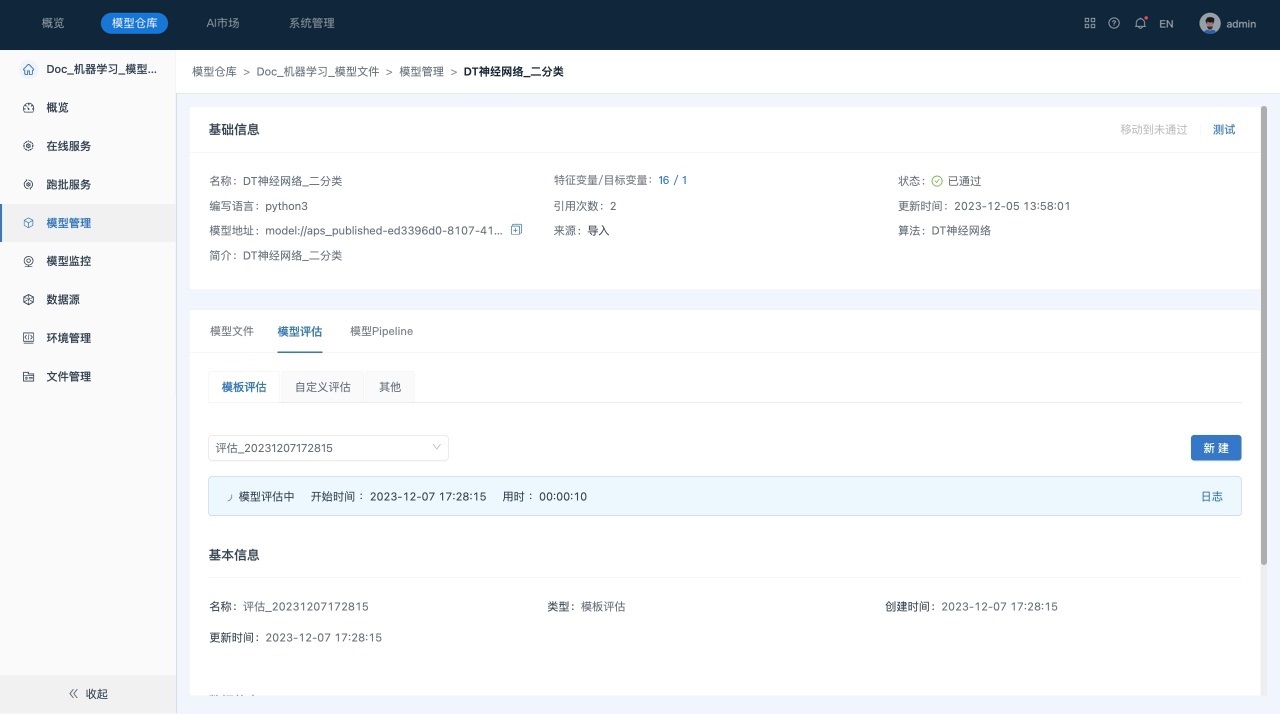
后续操作
单击页面右侧模型基本信息中的“测试”,在弹出框中进行模型测试,可以在模型未部署前通过测试识别模型API中的问题,确保其能够稳定可靠地提供服务。
模型详情页面主要包括如下几部分内容:
1) 模型的基本信息,包括模型名称、特征变量/目标变量、审核状态、来源、模型地址等信息。
2) 模型文件,展示模型的组成文件。点击文件夹查看文件内容。
3) 模板评估,展示用户使用模板评估产生的评估记录。点击评估下拉框切换不同模板评估任务。
4) 自定义评估,展示用户通过自定义脚本(使用Jupyter Lab)产生的评估记录。点击评估下拉框切换不同自定义评估任务。
5) 其他评估,展示从Lab发布到Inference的模型,在Lab模型训练阶段所产生的历史评估记录。
6) 模型Pipeline。