在线服务
在线服务可以将从Lab训练并发布到Inference的模型,直接导入的模型,以及镜像模型部署为服务,并以多种方式对外提供预测能力。
- 完整的模型生产化流程 从Lab训练完成的算法模型可在Inference里进行线上生产化部署,平台提供了完整的模型发布、部署、评估、上线、监控、升级等模型服务闭环管理功能,可最大化算法模型的生产价值。
- 多种模型服务方式,适合各种应用场景
- 同步调用(REST):通过HTTP方式提供模型预测服务。
- 同步调用(gRPC):基于HTTP2.0通信协议,具有更高的传输效率与性能,适合低延时、高频次的应用场景。
- 异步调用(MQ):以消息中间件为中介,为消息队列中的数据提供预测服务。
- 批处理(Batch):对存储在文件系统中的数据进行预测。
- 具备自动水平扩展能力
模型服务管理员可对每个模型对外提供服务的计算资源和实例个数进行设置;平台将根据所设置的策略和实际负载情况,对模型服务的实例数进行动态调整。
镜像模型目前只支持同步调用(REST):通过HTTP方式提供模型预测服务。
Transformers框架模型上线
- 支持将APS Lab上训练的Transformers模型上线为服务,Transtormers模型的上线过程和其他类型的模型上线过程没有任何区别,只需要选择正确的环境(推荐选择可以运行transformers框架的预置环境,或者基于此预置环境新建环境) 和足够的资源即可。
部署服务模型
模型部署是将算法应用到实际业务的重要环节。为了帮助用户更好的实现一站式端到端的算法应用,平台提供了模型部署功能,部署的模型可以作为在线服务的后端提供预测能力。 通过“部署”操作最多可以部署4个模型,但可以通过将已上线的模型下线,从而使得处于部署状态的模型最大达到6个。
场景描述
部署“DT神经网络_二分类”模型。
前提条件
- 待部署模型已审核通过。
操作步骤
-
在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
-
在页面左侧的“侧边栏”区域,选择在线服务,系统跳转到“在线服务”列表页面。
-
在在线服务页面中,单击页面右上角的“部署”,系统跳转到“新建部署”页面,如下所示:
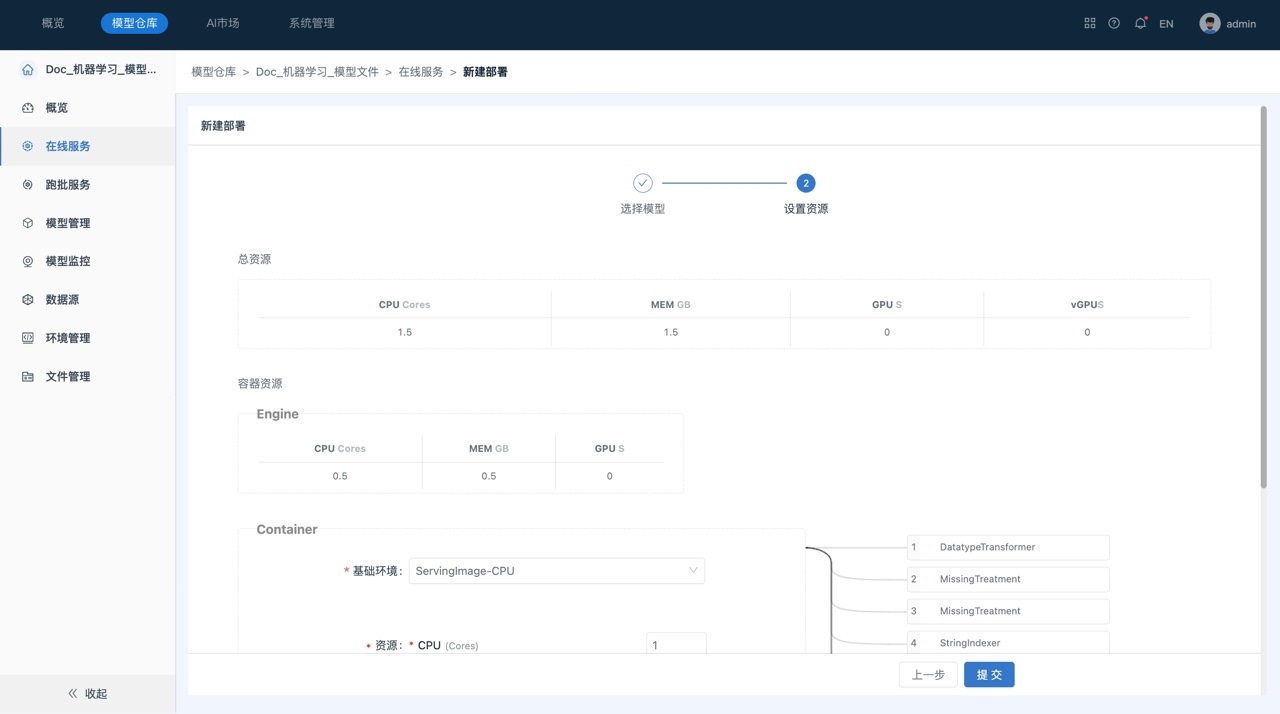
在进行模型部署时,包括一个“Engine”容器以及一个或多个“Container”类型的容器,每个Container容器由多步transformer组成,用户可以根据计算量调整Container的资源。
-
(可选)调整Container资源。
调整资源,包括容器使用的镜像以及CPU、内存和GPU资源。 -
单击提交,启动部署。部署过程中,支持用户进行“终止”部署的操作。
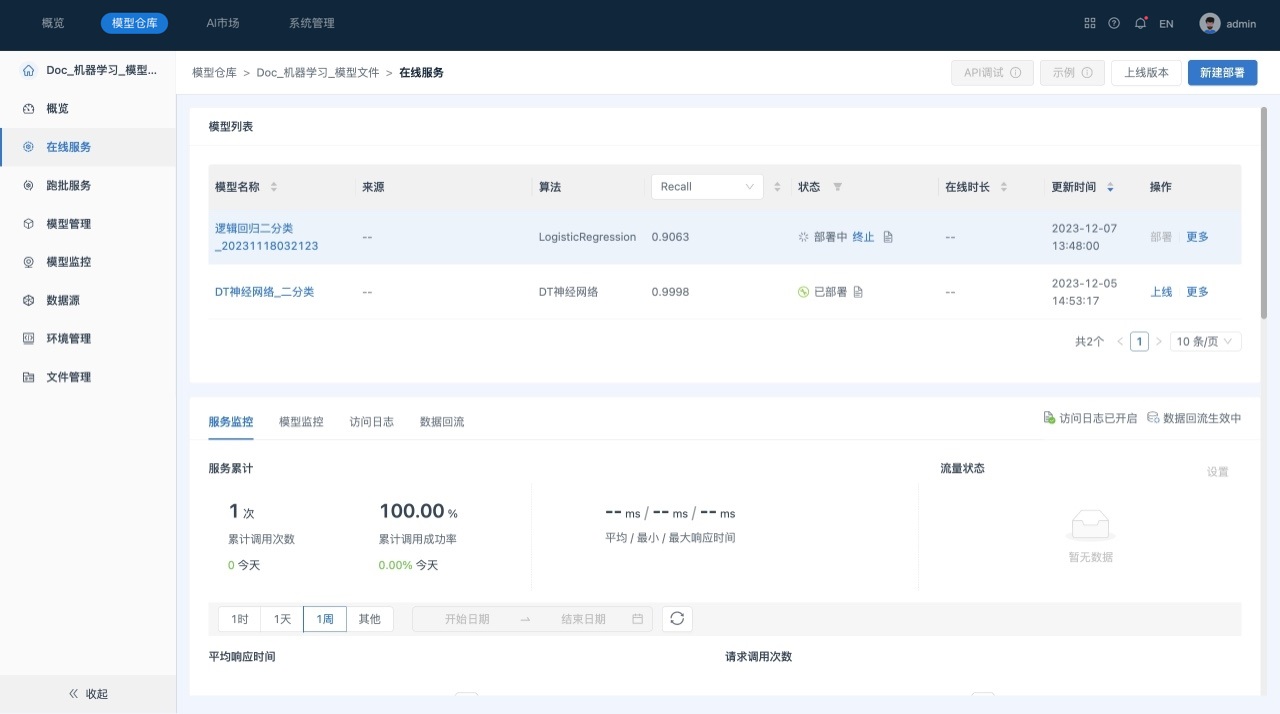
部署成功后,可以查看模型部署状态等信息:
- 状态以及日志:部署成功或失败以及具体日志信息。
- 调试:对部署成功的模型,提供API服务,可用于内部测试,调试API服务状态。
上线服务模型
在成功部署模型后,可以将其上线,从而以服务的形式对内外部应用提供预测和调用。同时系统提供弹性伸缩、灰度发布、影子上线等特性从而帮助客户以最低的资源成本获取高并发、稳定的在线算法模型服务。
系统为用户提供三种模型上线方式:正式上线、灰度上线和影子上线,最多支持同时上线两个模型,即用户可以同时实现模型的正式上线和灰度上线或者正式上线和影子上线。
- 正式上线:通过该方式部署的模型作为服务后端,接收客户端发送的请求数据并返回预测结果。一个服务中上线的第一个模型为正式上线。
- 灰度上线:通过该方式部署的模型作为服务后端并对部分请求流量进行处理,其余流量仍通过正式上线的模型进行处理。当有新版本的模型需要上线时,可以使用灰度上线,从而实现服务后端的平稳迁移。
- 影子上线:在不影响正式模型的前提下,在模型提供在线服务的过程中复制正式上线模型的全部流量。
场景描述
上线“DT神经网络_二分类”模型。
前提条件
- 待上线模型已部署成功。
操作步骤
- 在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
- 在页面左侧的“侧边栏”区域,选择在线服务,系统跳转到“在线服务”列表页面。
- 在在线服务“模型列表”中,单击模型所在行的“上线”,系统显示“上线”对话框,如下所示:
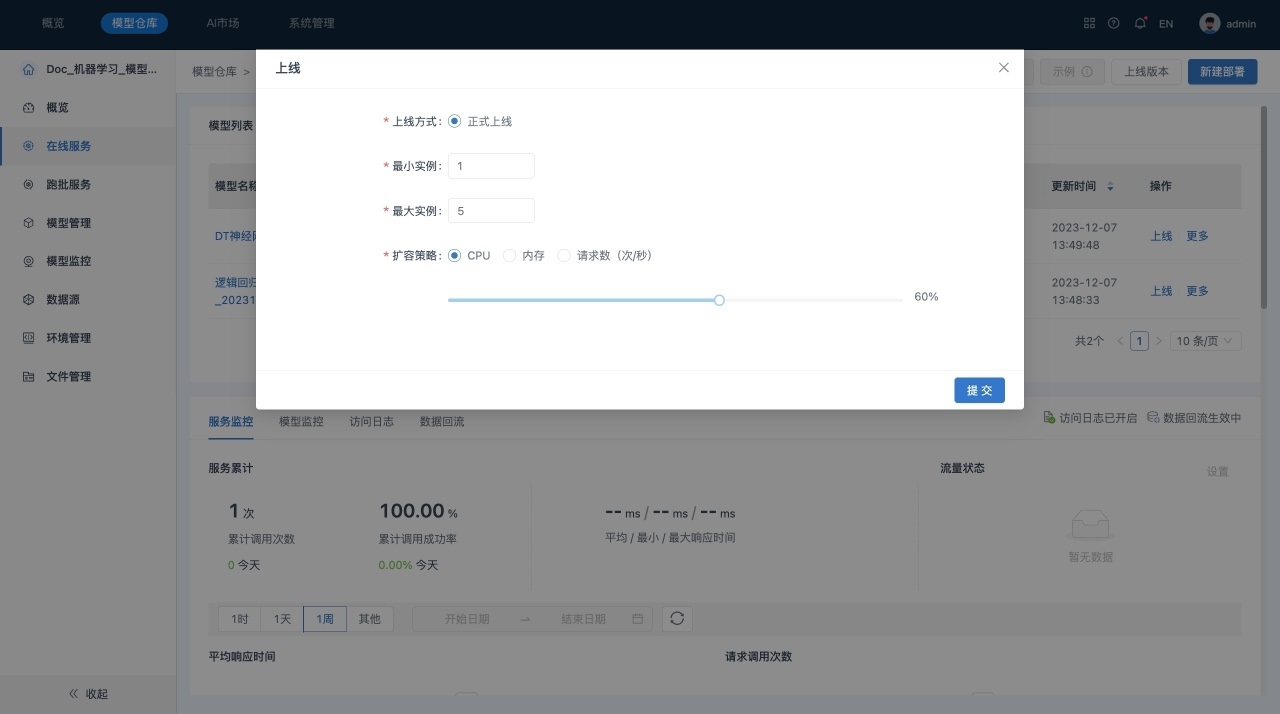
在“上线”对话框中可以设置模型的最小、最大实例数量和扩容策略,上线后,实例的CPU、内存和请求数达到扩容策略的设置值时,系统会自动动态调整实例数量。
当前上线模型为该服务的第一个模型,因此其上线方式为“正式上线”。
5. 完成上线配置并单击提交。
上线后,“模型列表”中模型的状态会变更为“已上线”。
6. 灰度上线。在“模型列表”中,单击“部署完成”模型所在行的“上线”,系统显示“灰度上线”对话框:
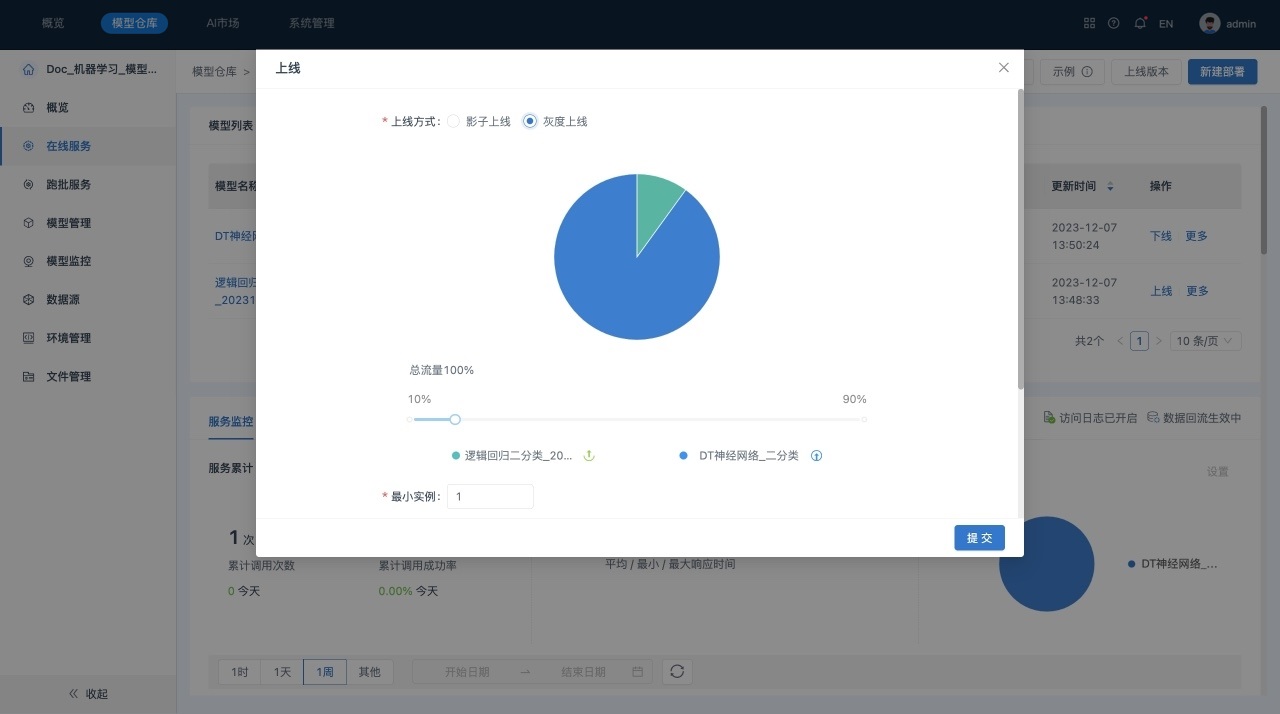
在灰度上线时,可以调整“正式上线”模型与“灰度上线”模型之间的流量比例,进行灰度上线模型的实例配置.
7. 单击提交,完成灰度上线操作。
上线后,“模型列表”中模型的状态会变更为“灰度上线”。
后续操作
- 已上线的模型可以执行下线操作。在“模型列表”中,单击模型所在行的“下线”,可以将模型下线,下线后的模型处于“已部署”状态。
- 如果服务中包括一个“正式上线”和一个“灰度上线”模型,则当将“正式上线”的模型下线后,原处于“灰度上线”状态的模型会自动变为“正式上线”状态。
- 如果服务中包括一个“正式上线”和一个“影子上线”模型,则当“正式上线”的模型下线时,“影子上线”的模型随“正式上线”的模型一起下线。
该页面主要包括如下几部分:
1) 模型列表:包括所有部署、正式上线、灰度上线、影子上线、取消部署状态的模型。
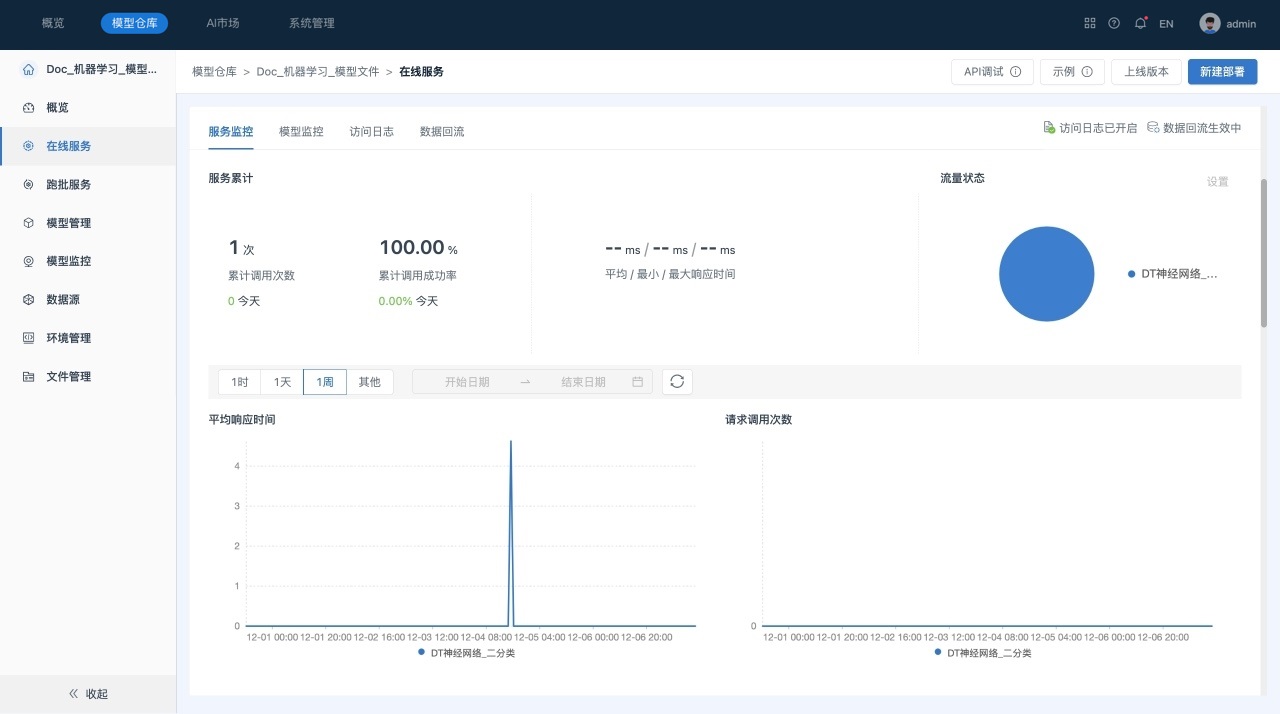
2) 服务监控:展示服务累计调用次数、累计调用成功率、平均/最小/最大响应时间、流量状态、上线模型的平均响应时间以及请求调用次数,CPU、GPU、内存等工作负载的实时使用情况,以及资源明细。
3) 模型监控:展示和当前上线模型相关的所有监控任务。
4) 访问日志:展示访问日志开启状态、开启时间、数据量、自动清理的策略,以及查看数据、导出记录。
5) 数据回流:展示数据回流开启状态、配置的运行模式、目标数据源、资源,以及运行记录。
管理在线服务
针对在线服务,除支持多种调用方式外,平台还提供了服务监控、模型监控、访问日志、数据回流以及服务版本管理能力。
- 通过在线服务对外提供算法模型的推理能力,为适应不同的应用场景,支持多种服务调用方式:
- 同步调用(REST):通过HTTP方式提供模型预测服务,适合小批量、调用准实时、频次不是很高的场景。
- 同步调用(gRPC):基于HTTP2.0通信协议,具有更高的传输效率与性能,适合低延时、高频次的应用场景。
- 异步调用(MQ):以消息中间件为中介,为消息队列中的数据提供预测服务,适合大批量、实时性要求较高的应用场景。
- 批处理(Batch):对存储在文件系统中的数据进行预测,适合批量、非实时处理的场景。
- 为保障服务的稳定运行,系统提供了服务监控功能:
- 容器级监控:平台通过容器为模型提供运行时环境,容器的资源利用率是否合理是监控服务健康持续运行的重要指标。
- 服务级监控:服务调用成功率、响应时长等参数,是监控服务状态的重要指标。
- 模型具有时效性,系统也提供了服务的模型监控功能:
- 监控功能基于模型监控模块实现,监控上线模型是否衰减。
- 支持对不同时间、多个模型之间的评估结果进行对比。
- 跟踪API调用有助于有效管理资源和成本,为业务决策提供支持,系统提供了访问日志和数据回流功能:
- 访问日志:记录着用户访问服务的信息,包括访问时间、访问者的IP地址等。对于了解用户行为、识别潜在问题以及优化服务至关重要。
- 数据回流:将收集到的数据反馈到系统中,实现“数据-模型-服务-数据”的企业AI业务闭环。
- 通过上线版本记录了服务中模型的变更情况:
- 当对服务中的模型执行上下线操作时,会生成新的服务版本。
- 系统支持版本回滚,但若历史版本中的模型已被删除,则不可再回滚至该版本。
场景描述
管理“Doc-机器学习-模型文件”服务中的上线模型。
前提条件
- 服务“Doc-机器学习-模型文件”中的模型已部署成功且上线。
操作步骤
-
在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
-
在页面左侧的“侧边栏”区域,选择在线服务,系统跳转到“在线服务”列表页面。
-
在“在线服务”列表页面中查看服务监控情况,如下所示:
-
查看服务调用示例。
a. 单击页面右上角的服务示例, 系统跳转到“示例”页面,如下所示:
b. 在“示例”页面中,切换“REST”、“MQ”、“Batch”、“gRPC”页签,可以查看不同调用方式的示例代码。
-
调试服务。
a. 单击页面右上角的服务API调试, 系统跳转到“API调试”页面,如下所示: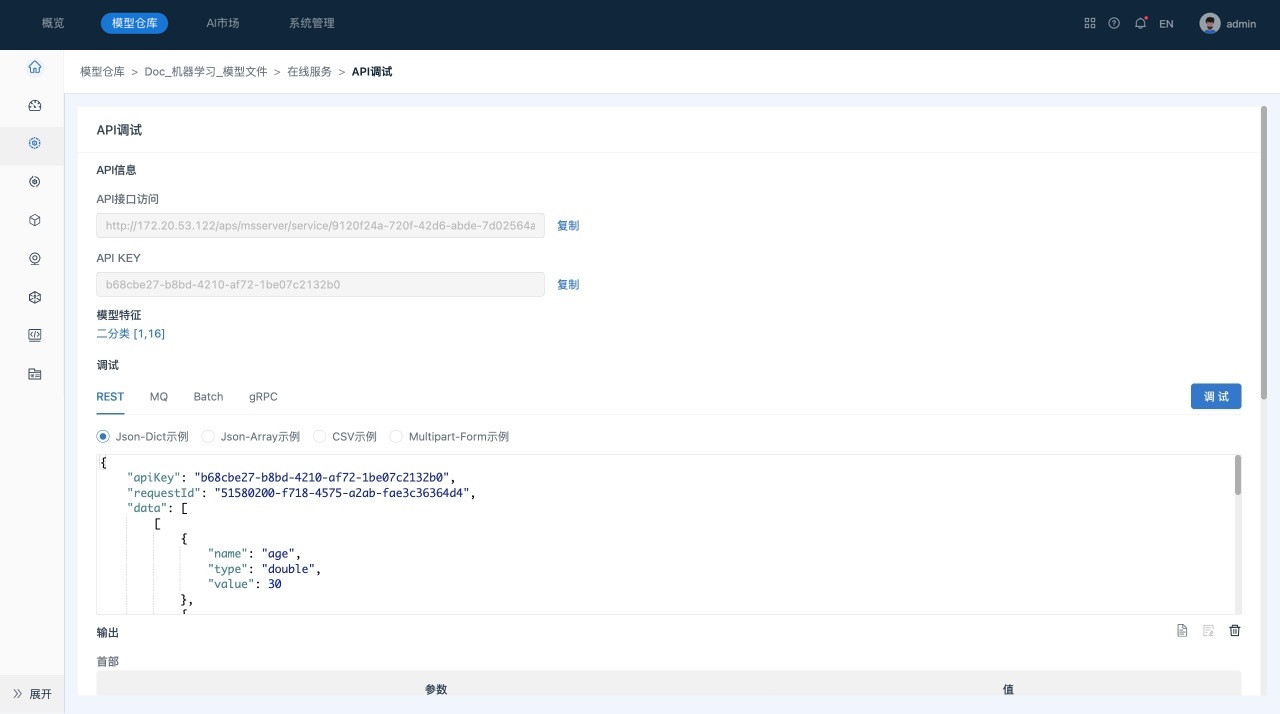
在“调试”区域中,系统自动生成了请求数据,用户也可以修改其中各特征的值。
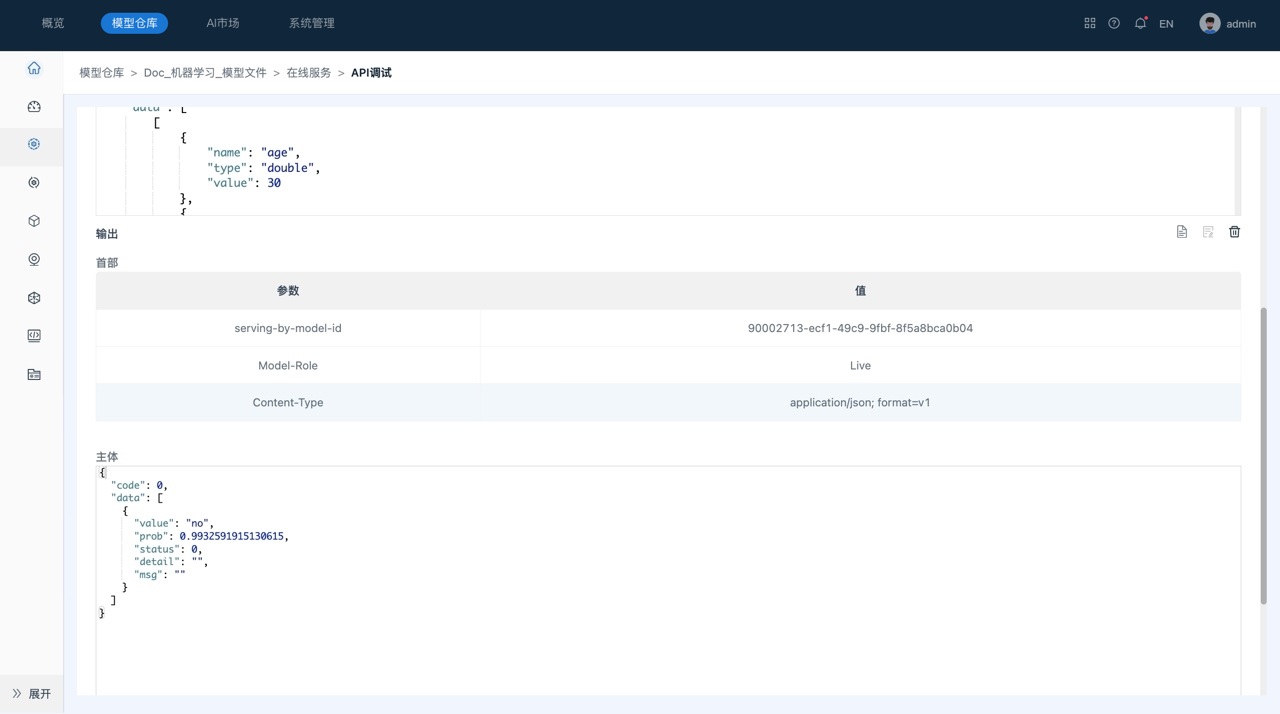
b. 单击调试,可以在运行结果区域可以查看推测结果。
查看在线服务
模型上线后,即可在模型详情页查看该模型上线后的基本信息、资源监控、实例信息和上线记录。
场景描述
查看“DT神经网络_二分类”模型上线后的资源使用情况。
前提条件
- “DT神经网络_二分类”模型已上线。
操作步骤
- 在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
- 在页面左侧的“侧边栏”区域,选择在线服务,系统跳转到在线服务“模型列表”页面。
- 在模型列表页面,单击 “DT神经网络_二分类”模型名称,进入到模型详情页面,如下所示。
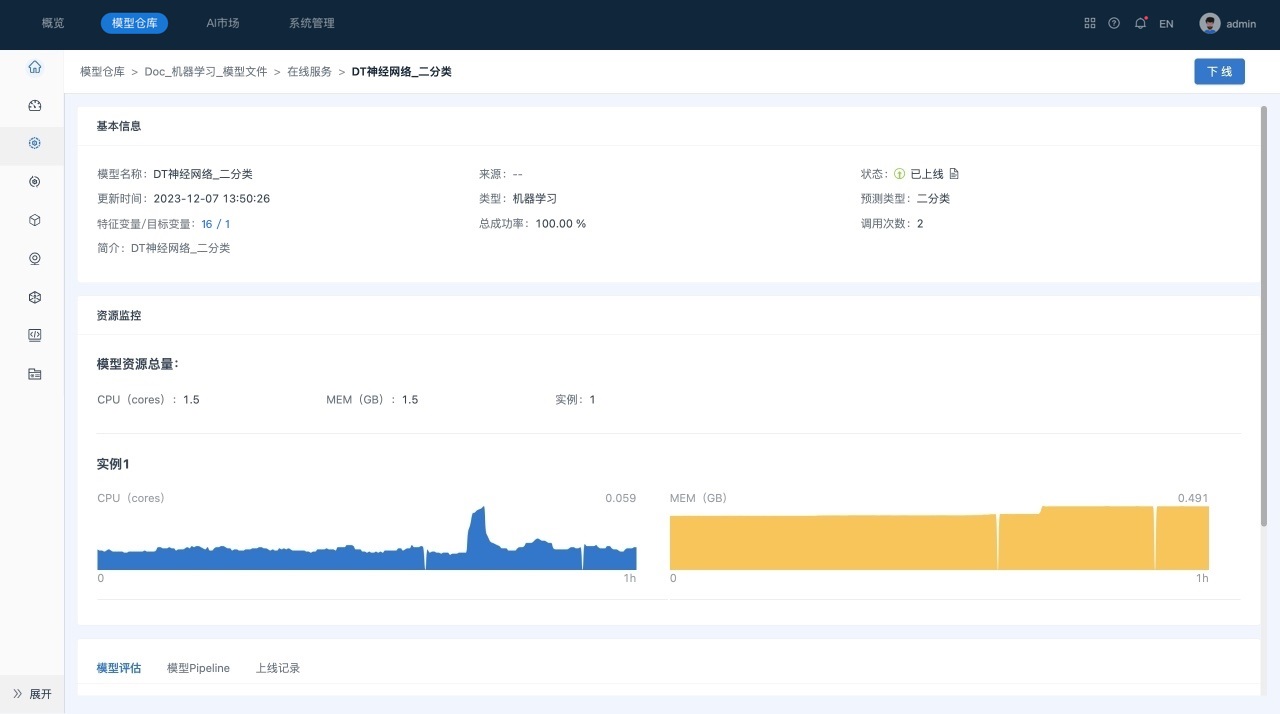
已上线模型详情页面主要包括如下几部分内容:
1) 基本信息,包括模型名称、变量信息、上线状态以及调用信息等。
2) 资源监控,包括模型资源总量、实例的资源实时使用情况。
3) 模型评估,显示该模型的历史评估结果。
4) 模型Pipeline。
5) 上线记录,显示模型的部署、上线、下线等操作记录。