跑批服务
跑批服务是一种用于处理大批量数据或周期性执行任务的服务。在跑批服务里,用户可以创建模板化的批处理任务或自定义的批处理任务(使用JupyterLab)来自动执行特定的操作。跑批服务的应用场景包括需要定期处理数据、自动化执行特定操作或者进行复杂计算的业务等。
使用跑批服务时,具有如下特性:
- 运行模式:分为单次运行和定期计划(定期运行、crontab表达式)两种。用户可设置任务的执行周期,例如每天、每周或其他特定时间间隔。
- 自动化执行:可以自动按照预定的计划或时间触发执行任务,无需手动干预。
- 批量处理:处理大量数据或执行任务,适用于需要定期处理数据或执行特定操作的业务场景。
- 资源配置:支持用户指定任务执行所需的资源,以优化任务执行效率。
- 监控和报告:提供执行情况的监控和报告功能,帮助用户了解任务执行状态和结果。
- 任务调度和管理:支持管理任务的调度,包括启动、重试、终止任务。
仅服务管理员拥有定期计划的权限
创建跑批服务
创建模板跑批
场景描述
在服务“Doc-机器学习-模型文件”中创建模板跑批任务,并命名为“模板跑批”。
前提条件
- 已经成功创建所需数据源“mysql-全表”。
- 已经成功导入所需模型“DT神经网络_二分类”。
- 已经成功创建所需文件夹“模板跑批结果”。
- 待跑批模型“DT神经网络_二分类”已审核通过。
操作步骤
-
在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
-
在页面左侧的“侧边栏”区域,选择跑批服务,系统跳转到“跑批服务”列表页面。
-
在跑批服务列表页面,单击页面右上角的新建按钮,选择下拉菜单里的“模板跑批”,系统跳转到“新建模板跑批”页面。
-
在“新建模板跑批”窗口中填写相关参数,如下所示:
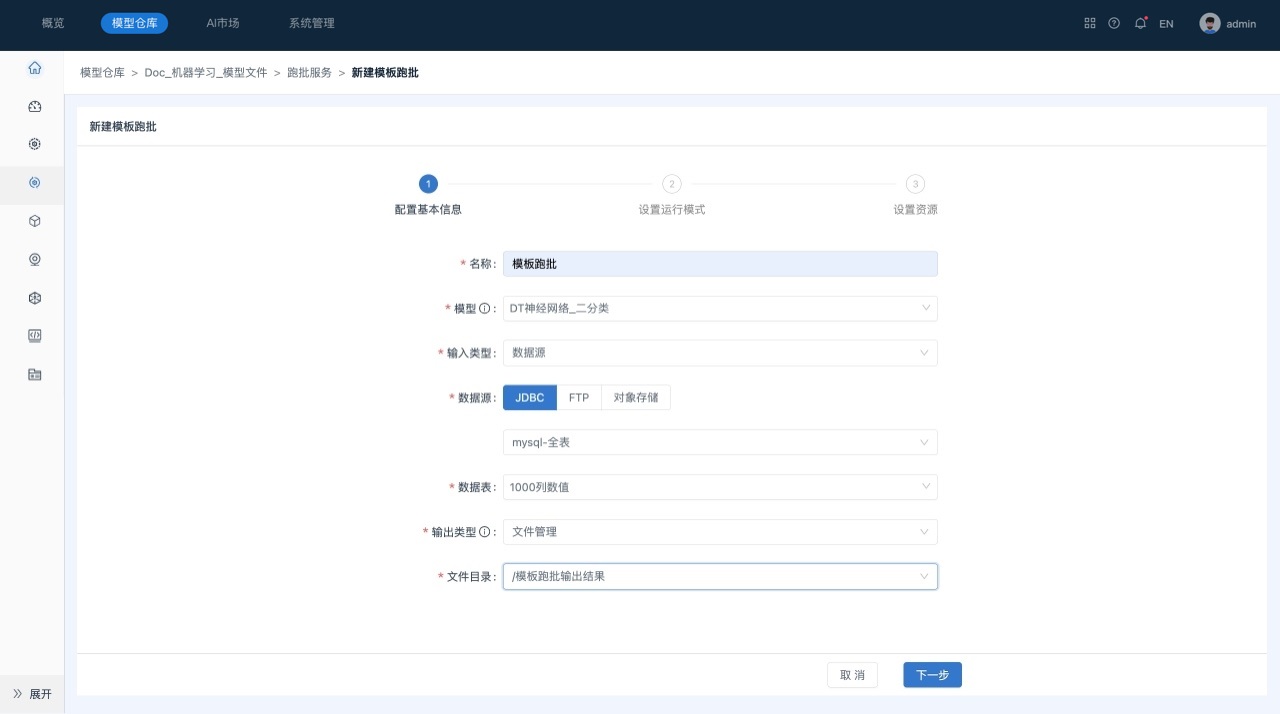
参数说明如下所示:
- 名称:模板跑批任务的名称。
- 模型:选择用于跑批的模型。
- 输入数据:选择模型跑批的输入数据,确保数据符合模型要求的格式和结构。
- 输出数据:选择跑批预测结果的输出路径。
-
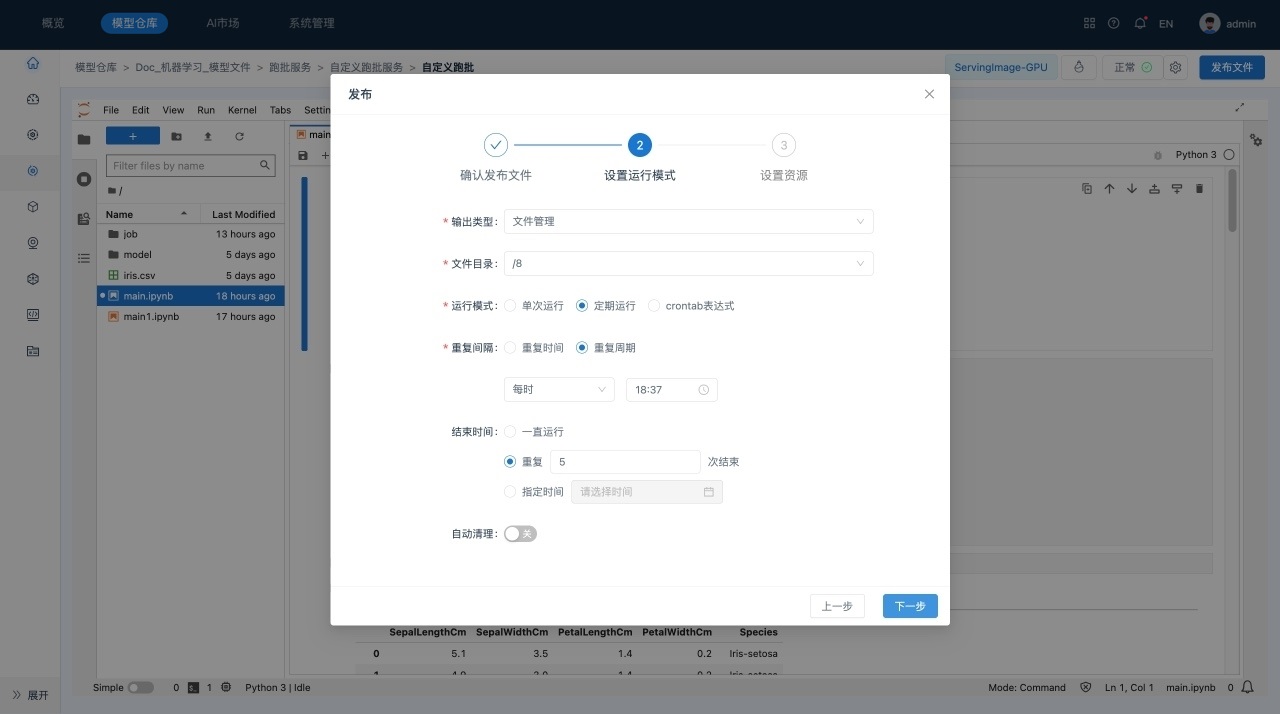
单击下一步,进行跑批服务的运行模式配置、自动清理策略配置。
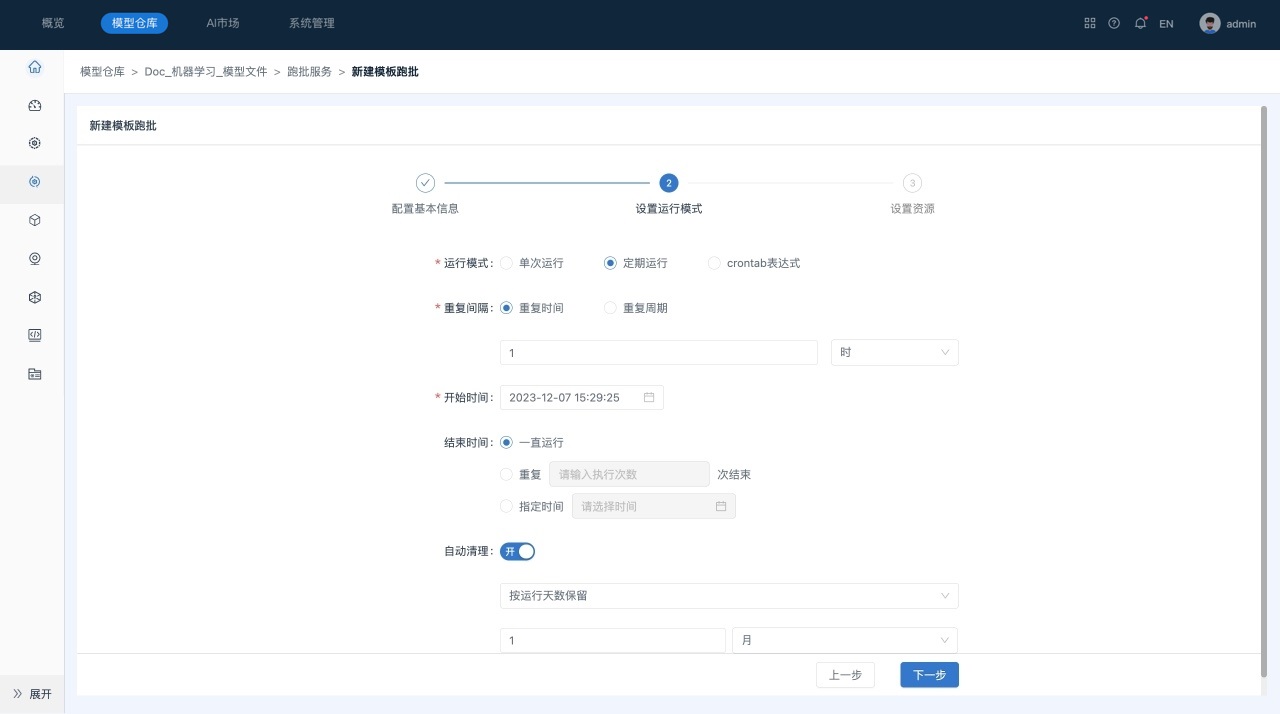
-
单击下一步,进行跑批服务资源配置。用户自定义是否使用GPU。
-
单击提交,系统自动开始模板跑批任务。
后续操作
在“跑批任务列表”中,显示所有模板跑批任务和自定义跑批任务。
该页面主要包括如下几部分:
1) 跑批任务列表:包括未开启、生效中、已关闭、已结束4种状态的跑批任务。
2) 服务监控:展示服务累计运行次数、累计运行成功率、跑批任务运行记录。
3) 模型监控:展示和当前跑批模型相关的所有监控任务。
创建自定义跑批
模型文件的自定义跑批
场景描述
在服务“Doc-机器学习-模型文件”中创建自定义跑批服务,并命名为“自定义跑批”。
前提条件
- 已经成功创建所需数据源“mysql-全表”。
- 已经成功导入所需模型。
- 已经成功创建所需文件夹“模板跑批结果”。
- 待跑批模型已审核通过。
- 容器状态为“正常”。
操作步骤
-
在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
-
在页面左侧的“侧边栏”区域,选择跑批服务,系统跳转到“跑批服务”列表页面。
-
在跑批服务列表页面,单击页面右上角的新建按钮,选择下拉菜单里的“自定义跑批”。
-
单击 “自定义跑批”,系统跳转到“自定义跑批”页面,对资源和环境设置进行确认。
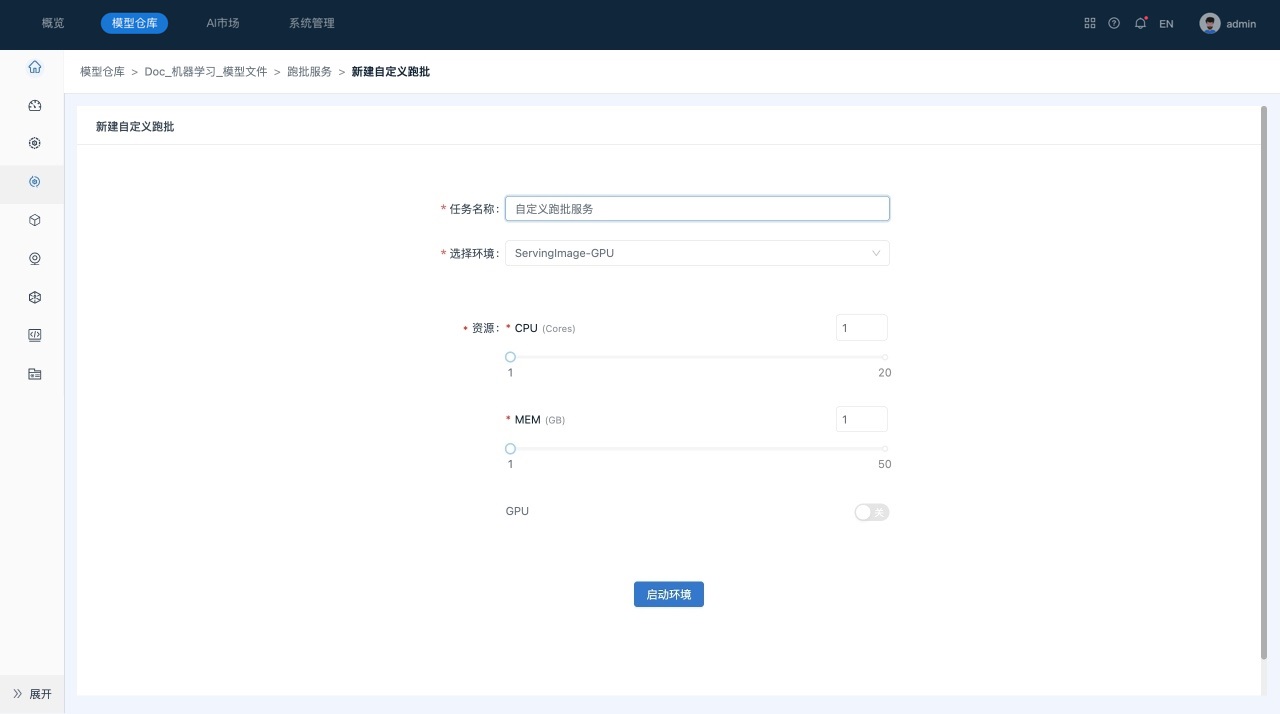
-
单击“启动环境”。
该操作会启动用户选择的环境,并在环境中启动Jupyter Lab服务。
用户可以在启动界面查看启动日志,在启动后,系统会自动进入到Jupyter Lab界面,如下所示: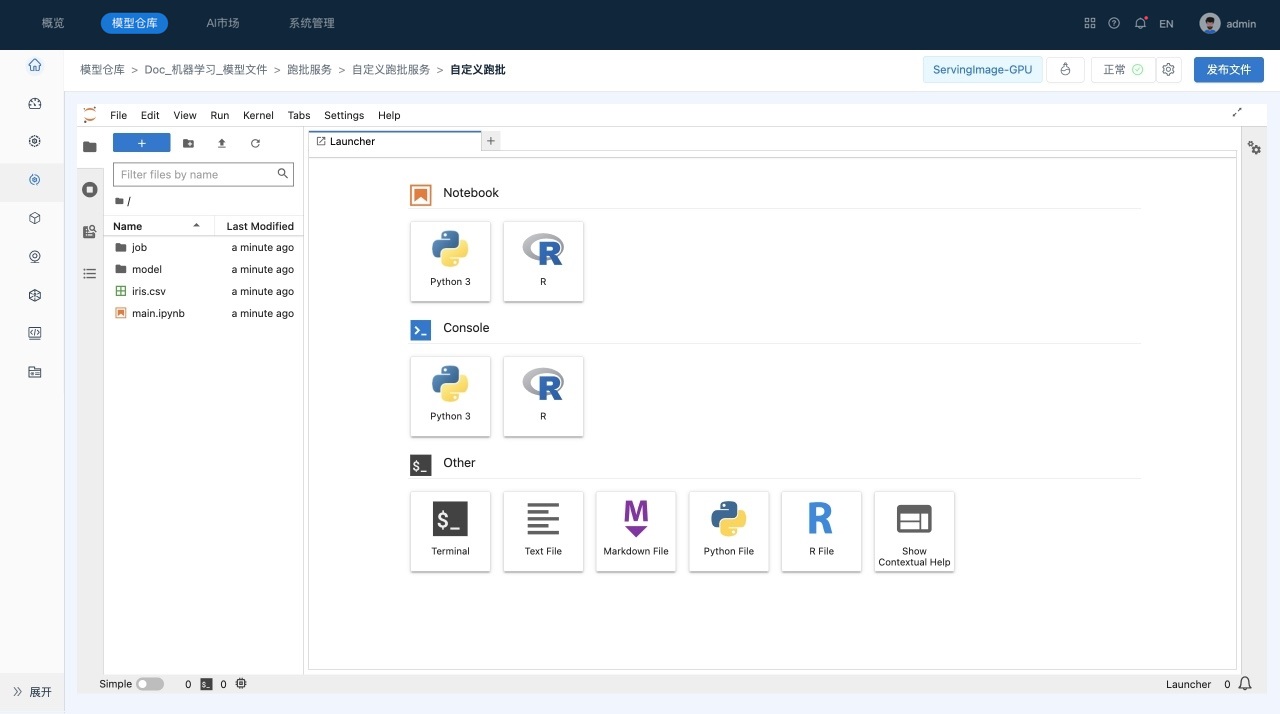
- 工具栏,提供了常用的管理功能。
- 资源管理器,包括文件管理、运行会话、命令帮助、服务等模块。
- 主工作区域,用于查看文件、编辑和运行Notebook等。
- 状态栏,显示当前后台运行的任务等信息。
-
创建一个Python3类型的Notebook。 在Lanucher面板中,单击“Python3”,即可创建并打开一个Python3类型的Notebook,修改名称为“鸢尾花决策树分类”。
-
在Notebook中编辑“鸢尾花决策树分类”代码,如下所示:
# 读取数据源中的csv
ds = dc.datasource("source://FTP-01")
df = ds.read_file(path="/bank/Binary_Bank_Header.csv")
# 下载模型:输入参数是模型url,支持多个,需要是列表。返回值为每个模型下载后的本地路径
def download_models(model_uris):
retval = []
from dc_model_repo import model_repo_infer_client as model_repo_client
for i, model_uri in enumerate(model_uris):
# 下载模型
print(f"Downloading {i}: {model_uri}")
model_tmp_path = f"./model_{i}.zip"
model_path = f"./model_{i}"
model_repo_client.get(model_uris[i], model_tmp_path, timeout=(2, 60))
# 解压模型文件
def unzip_file(zip_src, dst_dir):
import zipfile
r = zipfile.is_zipfile(zip_src)
if r:
fz = zipfile.ZipFile(zip_src, 'r')
for file in fz.namelist():
fz.extract(file, dst_dir)
else:
print('This is not zip')
unzip_file(model_tmp_path, model_path)
retval.append(model_path)
return retval
# 根据url下载模型
model_dir = download_models([model://e853306a-d364-41bb-8a94-efe7db05cb65])[0]
# 加载模型
from dc_model_repo.pipeline.pipeline import DCPipeline
pipeline = DCPipeline.load(model_dir) # 加载Pipeline
pipeline.prepare()
# 使用加载的模型对输入的数据进行预测,根据需要将预测结果与原始数据进行合并。
pred = pipeline.predict(df)
df.reset_index(inplace=True, drop=True)
pred.reset_index(inplace=True, drop=True)
df_result = pd.concat([df, pred], axis=1)
df_result
# 将结果写入到指定位置:对于结构化数据,以csv形式,保存到从dc.conf.output中获取的output目录中。
output_dir = dc.conf.output
-
完成编辑并保存后,单击右上角的发布文件,系统显示“发布”对话框,对需要发布的文件、运行模式设置、脚本资源和环境设置进行确认。
后续操作
可以在“跑批任务列表”多次新建自定义跑批任务。
自定义跑批任务详情页面主要包括如下几部分内容:
1) 任务的基本信息,包括任务名称、环境信息、模型信息、跑批状态以及输出信息。单击页面基本信息中的模型名称,系统会跳转到模型详情页面。
2) 任务的参数配置,包括运行模式、资源信息、自动清理策略。
3) 任务的运行记录,包括任务名称、开始/完成时间、运行状态。任务运行成功后,单击预览或下载,查看预测结果。
4) 查看代码,查看单次运行的脚本内容。
5) 查看Jupyter Lab,可查看自定义的历史脚本内容。
6) 编辑Jupyter Lab,可进入Jupyter Lab再次编辑、发布脚本内容。
镜像模型的自定义跑批
场景描述
在服务“Doc-机器学习-镜像模型”中创建跑批服务,并命名为“自定义跑批”。
前提条件
- 已经成功创建所需数据源“mysql-全表”。
- 已经成功导入所需模型。
- 已经成功创建所需文件夹“模板跑批结果”。
- 待跑批模型已审核通过。
- 容器状态为“正常”。
操作步骤
-
在“模型仓库”主界面,选择服务“Doc-机器学习-镜像模型”,进入该服务主页面。
-
在页面左侧的“侧边栏”区域,选择跑批服务,系统跳转到“跑批服务”列表页面。
-
在跑批服务列表页面,单击页面右上角的新建按钮,选择下拉菜单里的“自定义跑批”。
-
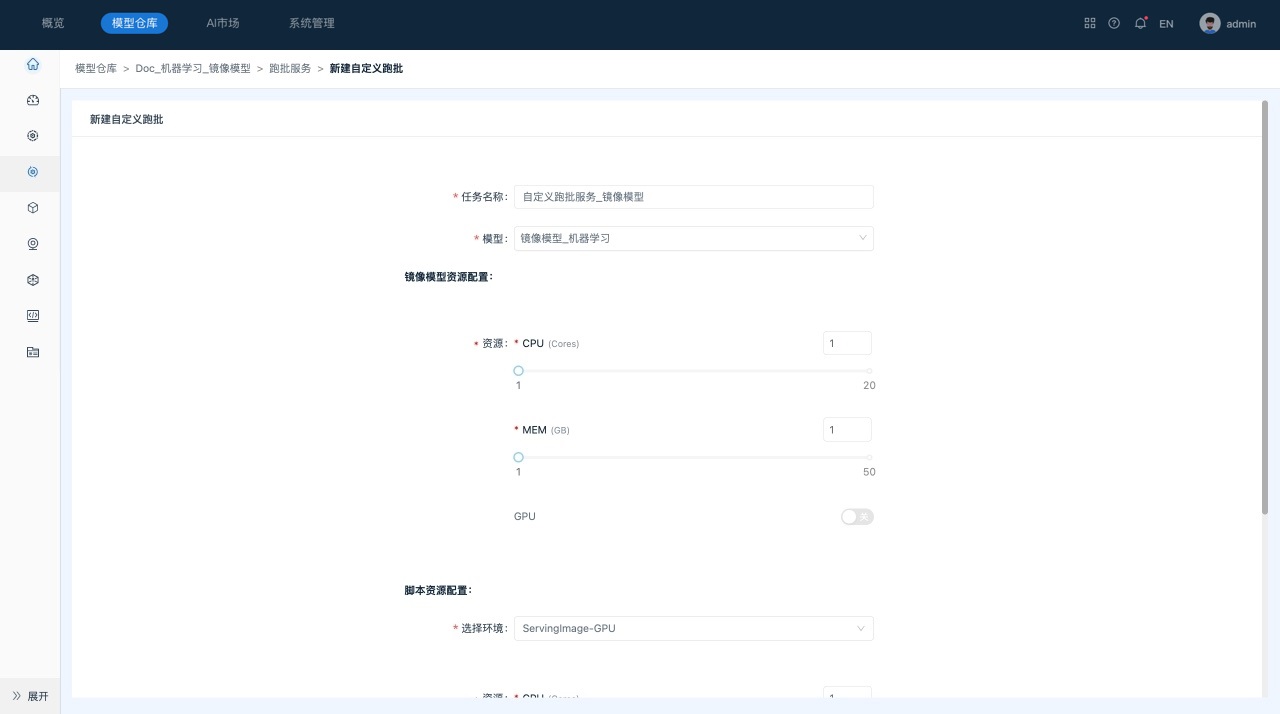
单击 “自定义跑批”,系统跳转到“自定义跑批”页面,对镜像模型资源、脚本资源和环境设置进行确认。
-
单击“启动环境”。
该操作会启动用户选择的环境,并在环境中启动Jupyter Lab服务。
用户可以在启动界面查看启动日志,在启动后,系统会自动进入到Jupyter Lab界面,如下所示: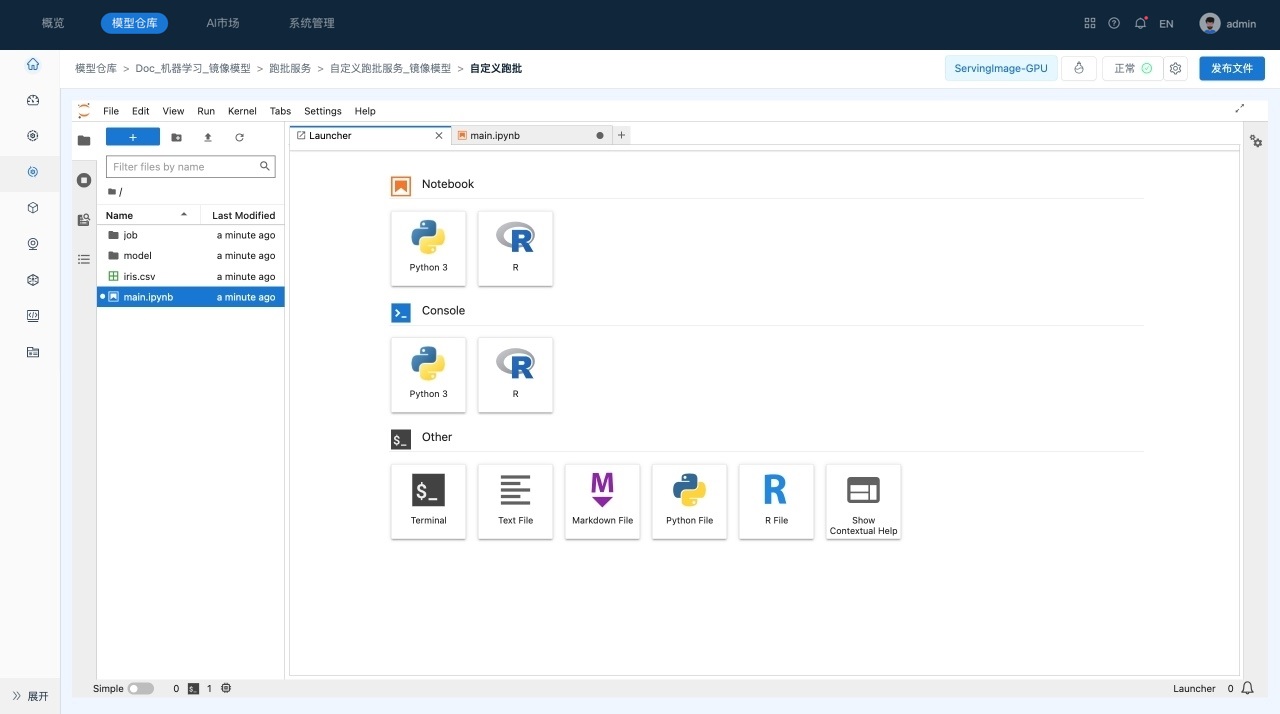
- 工具栏,提供了常用的管理功能。
- 资源管理器,包括文件管理、运行会话、命令帮助、服务等模块。
- 主工作区域,用于查看文件、编辑和运行Notebook等。
- 状态栏,显示当前后台运行的任务等信息。
-
创建一个Python3类型的Notebook。 在Lanucher面板中,单击“Python3”,即可创建并打开一个Python3类型的Notebook,修改名称为“鸢尾花决策树分类”。
-
在Notebook中编辑“鸢尾花决策树分类”代码,如下所示:
import requests
import json
url = dc.conf.global_params.image_service_url
headers = {
'Connection': 'keep-alive',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Content-Type': 'application/json'
}
def predict(payload):
response = requests.request("POST", url, headers=headers, data=payload)
return response.text
def convert_sample_to_content(sample):
"""这个方法里把待预测的样本转换成api所需的请求体,此处略去"""
pass
"# 1.读取文件管理里面的input.json文件\n",
ds = dc.datasource("document://input.json")
file_path = ds.extract("")
predictions = []
print('读取文件管理中的csv:',file_path)
"# 2.读取文件中的参数,并保存预测结果\n",
predictions = []
with open(file_path, 'r') as json_file:
for line in json_file:
try:
response = predict(line)
pred = json.loads(response)
predictions.append(pred)
except json.JSONDecodeError as e:
print(f"Error decoding JSON: {e}")
predictions
print('预测结果:',predictions)
print('预测成功!')
"# 3.将预测结果保存到文件管理中的文件\n",
import pandas as pd
output_dir = dc.conf.output
for arr in predictions:
pred = pd.DataFrame(predictions)
from pathlib import Path
Path(output_dir).mkdir(exist_ok=True, parents=True)
pred.to_csv(Path(output_dir, "prediction.csv"), index=False)
print('预测结束')
-
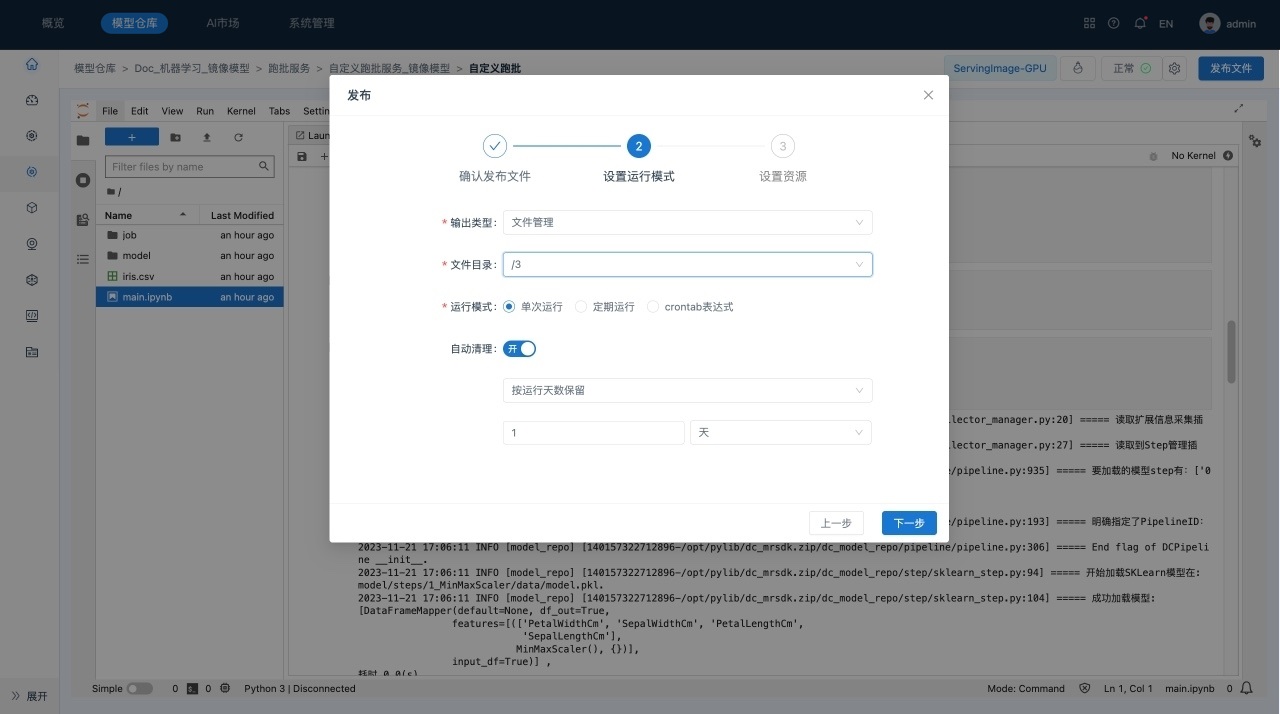
完成编辑并保存后,单击右上角的运行,系统显示“发布”对话框,对需要发布的文件、运行模式设置、镜像模型资源、脚本资源和环境设置进行确认。
管理跑批服务
针对跑批服务,平台提供了服务监控、模型监控管理能力。
- 为保障服务的稳定运行,系统提供了服务监控功能:
- 服务级监控:服务调用成功率、响应时长等参数,是监控服务状态的重要指标。
- 模型具有时效性,系统也提供了服务的模型监控功能:
- 监控功能基于模型监控模块实现,监控跑批模型是否衰退。
- 支持对不同时间、多个模型之间的评估结果进行对比。
场景描述
管理“Doc-机器学习-模型文件”服务中的跑批模型。
前提条件
- 服务“Doc-机器学习-模型文件”中的模型已审核成功。
操作步骤
-
在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
-
在页面左侧的“侧边栏”区域,选择跑批服务,系统跳转到“跑批服务”列表页面。
-
在跑批任务列表页面中查看服务监控情况,如下所示:
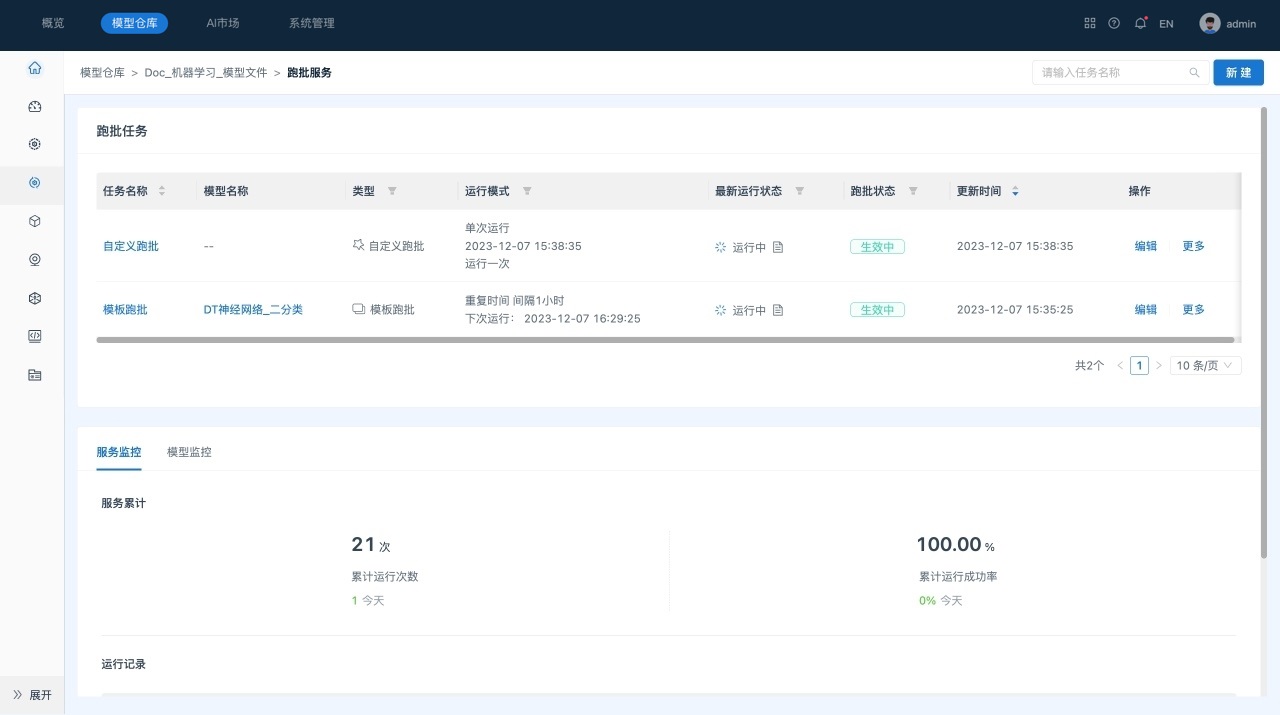
查看跑批服务
创建模板跑批任务后,即可在跑批详情页查看该任务的基本配置和预测结果。
场景描述
查看“模板跑批”运行后的预测结果。
前提条件
- 已创建模板跑批任务。
操作步骤
-
在“模型仓库”主界面,选择服务“Doc-机器学习-模型文件”,进入该服务主页面。
-
在页面左侧的“侧边栏”区域,选择跑批服务,系统跳转到“跑批任务”列表页面。
-
在跑批任务列表页面,单击 “模板跑批”任务,进入到“模板跑批”的任务详情页面,如下所示。
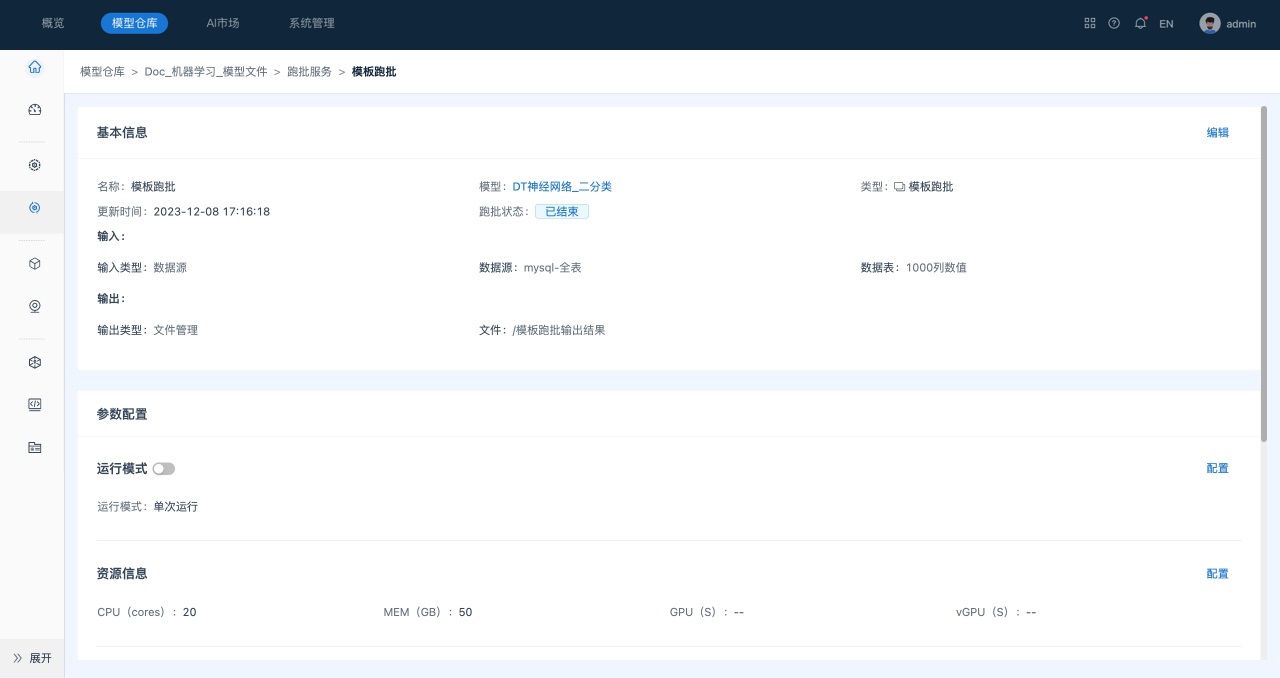
模板跑批任务详情页面主要包括如下三部分内容:
1) 基本信息,包括任务名称、模型信息、跑批状态以及输入输出信息。单击页面基本信息中的模型名称,系统会跳转到模型详情页面。
2) 参数配置,包括运行模式、资源信息、自动清理策略。
3) 运行记录,包括任务名称、开始/完成时间、运行状态。任务运行成功后,单击预览或下载,查看预测结果。