秒懂你的需求 -基于多模态动态检索的机器人自适应任务规划
LamRA是一种基于大型多模态模型(LMM)的通用检索框架,旨在解决传统多模态检索方法依赖任务特定微调、泛化能力受限的问题。随着多模态信息检索的复杂化,现有视觉语言模型(如CLIP)在跨模态对齐和复杂文本理解上存在局限,且难以适应新兴任务。LamRA通过插入轻量级LoRA模块,赋予生成式LMM双重能力:
- 通用检索:采用两阶段训练策略(文本预训练+多模态指令微调),使模型能处理跨模态、组合式检索等多样化任务;
- 智能重排序 :结合点式和列表式联合训练,利用候选池难例挖掘提升精度。实验表明,LamRA在10余个检索任务(如图文互搜、组合图像检索)中均超越SOTA,尤其在零样本场景下对未见任务(如长文本图像检索)展现强大泛化能力,最高提升63.7%的召回率,为多模态检索提供了高效统一的解决方案。
本实践针对LamRA-Ret框架的预训练阶段,系统探索了不同数据类型对检索性能的影响。通过构建纯图像(基于区域编辑数据)、纯文本(NLI文本三元组)、图文对(ShareGPT4V长文本)及混合型四类数据集,结合MSCOCO/Flickr30K基准测试发现:纯文本预训练(采用查询-正例对并利用批次内负采样)表现最佳,其检索性能随数据规模稳定提升,而简单混合多模态数据反而导致性能下降。实验最终选定语言单模态预训练方案,为后续多模态指令微调奠定了高效基础,验证了文本语义强化在多模态检索中的核心驱动作用。
准备工作
- AlayaNeW平台完成企业账户注册,可点击 进行快速注册。
- 企业已开通弹性容器集群,参考 开通弹性容器集群。
本实践弹性容器集群的资源配置至少需要满足以下表格中的要求。
| 配置项 | 配置需求 |
|---|---|
| GPU | H800 * 8 |
| CPU | 8核 |
| 内存 | 100GB |
| 磁盘 | 200GB |
操作步骤
-
连接Alaya NeW镜像仓库:点击Environment-> Setting Registry,镜像仓库类型选择“AlayaNeW”后,配置镜像仓库用户名、密码后 可连接Alaya NeW镜像仓库,包含公共镜像项目和企业镜像仓库项目,点击Environment-> Setting Project可切换项目。

-
在Aladdin的
WORKSHOP功能区单击 图标新建一个LamRA作为本次微调任务的开发环境,示例如下图所示。
图标新建一个LamRA作为本次微调任务的开发环境,示例如下图所示。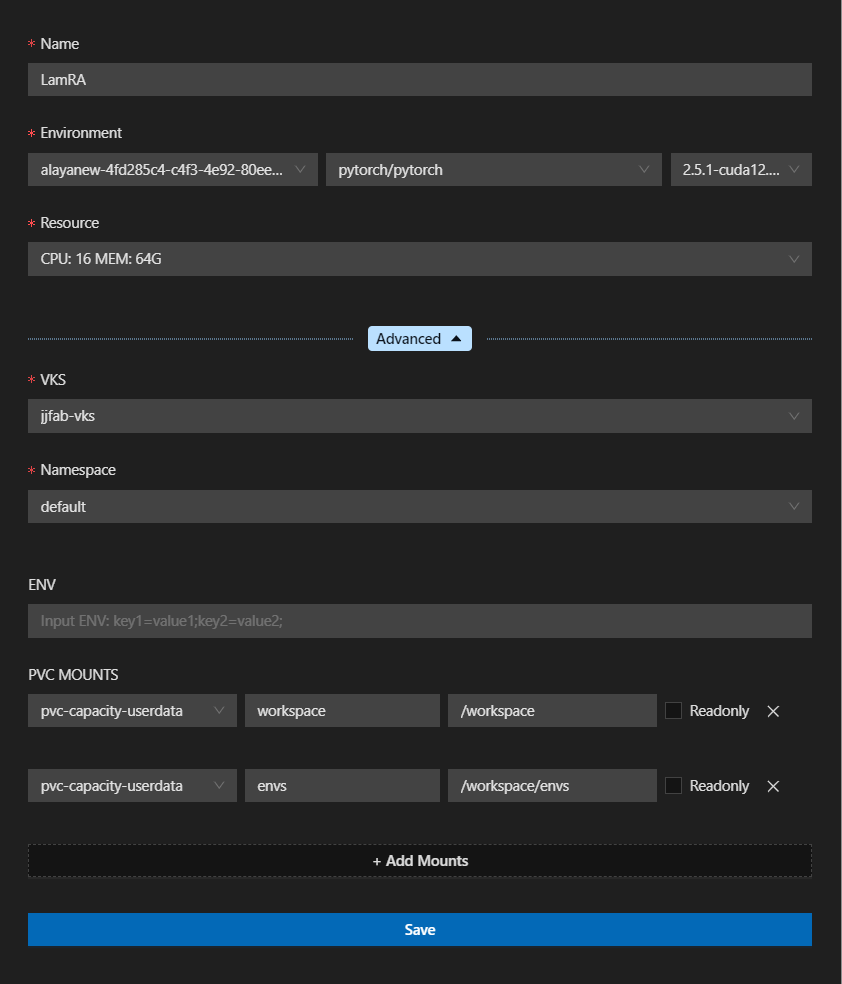
本实践配置的参数配置及说明如下所示。
- Name:LamRA,用于唯一标识一个WORKSHOP。
- Environment:pytorch/pytorch,此处选择需要导入的镜像。
- VKS:jjfab-vks,此处选择Aladdin账户内的弹性容器集群。
- PVC MOUNTS:两处均绑定
pvc-capacity-userdata,SubPath配置分别为workspace、envs,ContainerPath配置分别为/workspace、/workspace/envs。 - 其余参数均保持默认值。
-
提交后等待启动成功后会自动打开一个新的vscode窗口,连接进入到workshop中,并下载vscode相关插件,等待插件安装完成,会看到aladdin的图标。

-
在资源管理器下,单击打开文件夹,可选择工作的存储路径,推荐使用/workspace工作路径。可通过File -> Open Folder更换工作路径。

-
环境准备, 打开命令行执行以下命令配置环境
cd /workspace
git clone https://github.com/Code-kunkun/LamRA
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --set channel_priority strict
conda config --remove channels defaults
conda init
conda create -n lamra python=3.10 -y
conda activate lamra
pip install --upgrade pip # enable PEP 660 support
pip install -r requirements.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip install ninja -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorboard -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install flash-attn --no-build-isolation
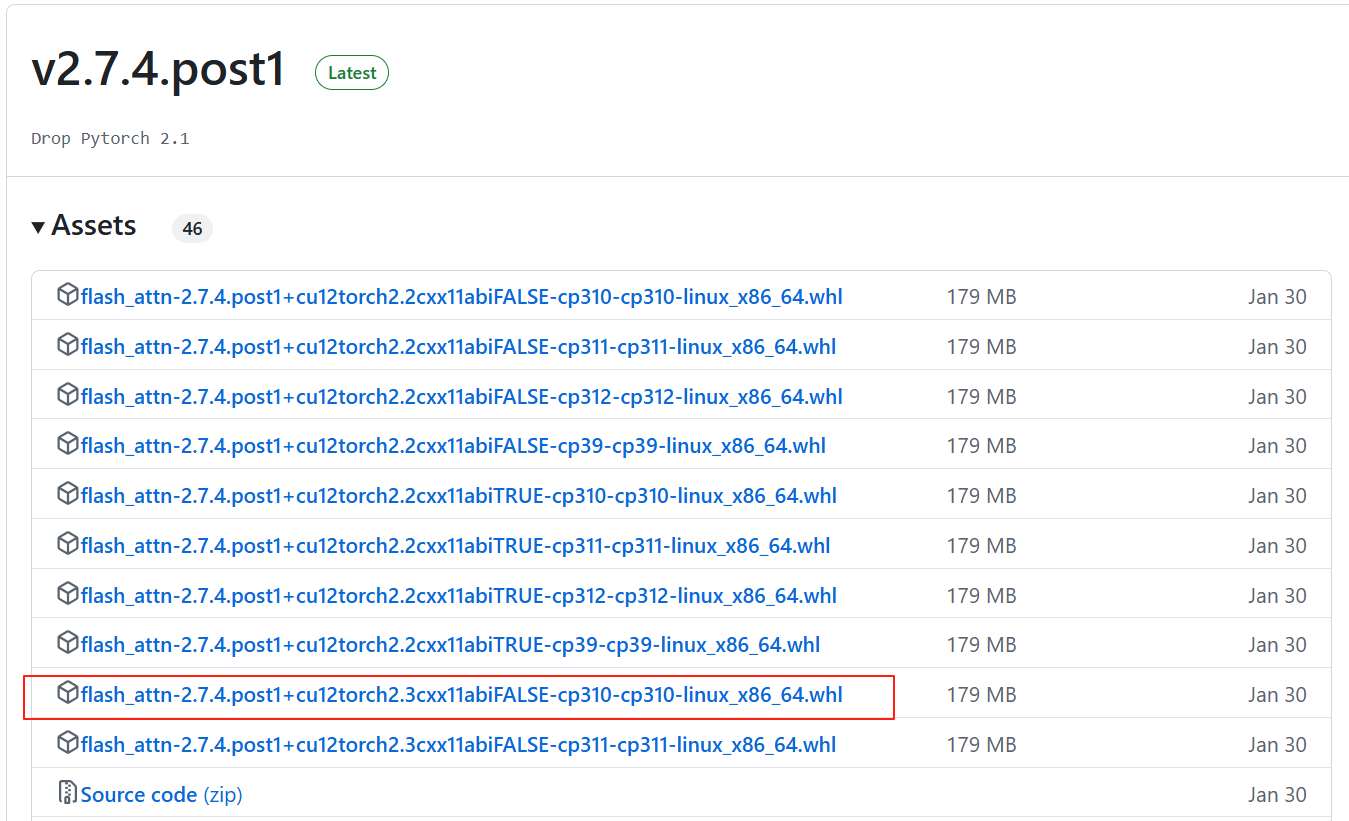
使用pip install flash-attn --no-build-isolation时编译时间过长,故环境准备使用了github上提供编译完成的flash_attn-2.7.4.post1+cu12torch2.3cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
- 模型参数下载
export HF_ENDPOINT=http://hfmirror.mas.zetyun.cn:8082
pip install -U huggingface_hub
for i in {1..1000}; do
huggingface-cli download --resume-download Qwen/Qwen2-VL-7B-Instruct \
--max-workers 2 \
--local-dir Qwen2-VL-7B-Instruct && break || sleep 10
echo "重第 $i 次,退出请按 Ctrl+C"
done
模型参数下载路径为:/workspace/LamRA/checkpoints/hf_models

- 预训练数据下载,保存至路径/workspace/LamRA/data/,点击附件链接即可下载“nli_for_simcse.csv”文件。

- 预训练
Run shell会远程启动Shell脚本,运行成功或者失败均会自动释放资源,运行时会产生session,运行完成或运行失败不再展示session。
选择预训练shell脚本(/workspace/LamRA/scripts/lamra_ret/pretrain.sh)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --set channel_priority strict
conda config --remove channels defaults
conda init
source ~/.bashrc
conda activate lamra
NUM_GPUS=8
DISTRIBUTED_ARGS="
--nnodes=1 \
--nproc_per_node ${NUM_GPUS} \
--rdzv_backend c10d \
--rdzv_endpoint localhost:0
"
MODEL_ID=qwen2-vl-7b
TRAIN_DATA_PATH=./data/nli_for_simcse.csv # path to the training data csv file
EVAL_DATA_PATH=None
TRAIN_VISION_ENCODER=False
USE_VISION_LORA=False
TRAIN_VISION_PROJECTOR=False
USE_LORA=True
Q_LORA=False
LORA_R=64
LORA_ALPHA=128
RUN_ID=${MODEL_ID}_LamRA_Ret_Pretrain
DS_STAGE=zero2
PER_DEVICE_BATCH_SIZE=72
GRAD_ACCUM=1
NUM_EPOCHS=2
LR=2e-4 # The training will be more stable under this learning rate
# LR=4e-4 # This learning rate may result in unstable training; consider multiple attempts, lowering it, or using our provided checkpoint
MODEL_MAX_LEN=1024
torchrun $DISTRIBUTED_ARGS train/train_nli.py \
--model_id $MODEL_ID \
--data_path $TRAIN_DATA_PATH \
--output_dir ./checkpoints/$RUN_ID \
--report_to tensorboard \
--run_name $RUN_ID \
--deepspeed ./ds_configs/${DS_STAGE}.json \
--bf16 True \
--num_train_epochs $NUM_EPOCHS \
--per_device_train_batch_size $PER_DEVICE_BATCH_SIZE \
--per_device_eval_batch_size $PER_DEVICE_BATCH_SIZE \
--gradient_accumulation_steps $GRAD_ACCUM \
--eval_strategy "epoch" \
--save_strategy "epoch" \
--save_total_limit 2 \
--learning_rate ${LR} \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--model_max_length $MODEL_MAX_LEN \
--gradient_checkpointing True \
--dataloader_num_workers 4 \
--train_vision_encoder $TRAIN_VISION_ENCODER \
--use_vision_lora $USE_VISION_LORA \
--train_vision_projector $TRAIN_VISION_PROJECTOR \
--use_lora $USE_LORA \
--q_lora $Q_LORA \
--lora_r $LORA_R \
--lora_alpha $LORA_ALPHA
右键选择RUN shell

选择镜像和需要的GPU资源,支持将参数设置保存为configration,保存后的configration会展示在Configration列表下,再次启动可选择Configration后直接填入参数。
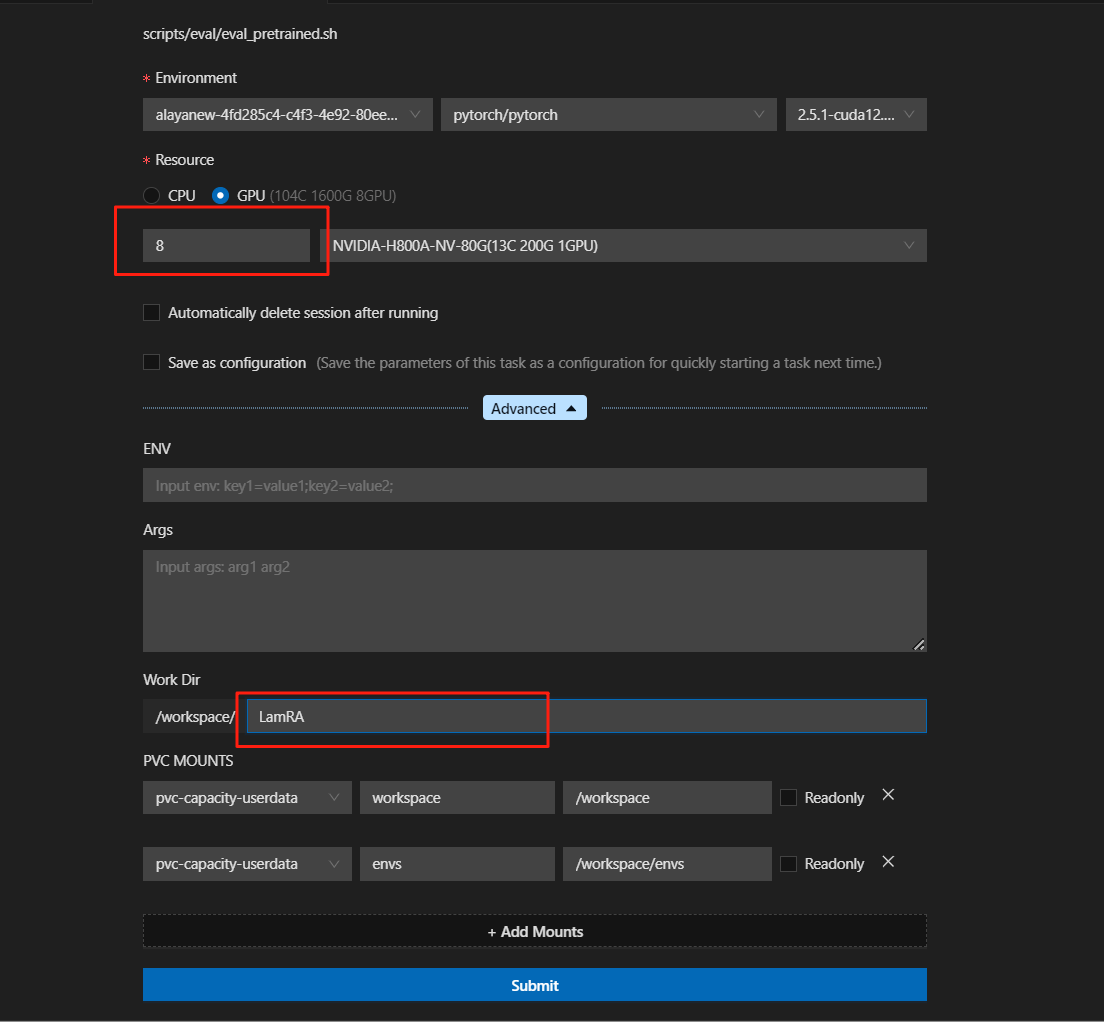
提交后运行

- 评估
评估数据下载
https://huggingface.co/datasets/code-kunkun/LamRA_Eval/tree/main

将评估数据同步到/workspace/LamRA/data下
解压tar文件
tar -zxvf flickr.tar.gz
选择评估shell脚本/workspace/LamRA/workspace/LamRA/scripts/eval/eval_pretrained
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --set channel_priority strict
conda config --remove channels defaults
conda init
source ~/.bashrc
conda activate lamra
CUDA_VISIBLE_DEVICES='0,1,2,3,4,5,6,7' accelerate launch --multi_gpu --main_process_port 29508 eval/eval_zeroshot/eval_flickr.py \
--image_data_path ./data/flickr/images \
--text_data_path ./data/flickr/flickr_text.json \
--original_model_id ./checkpoints/hf_models/Qwen2-VL-7B-Instruct \
--model_id ./checkpoints/qwen2-vl-7b_LamRA_Ret_Pretrain
右键选择RUN shell

选择镜像和需要的GPU资源
提交后运行

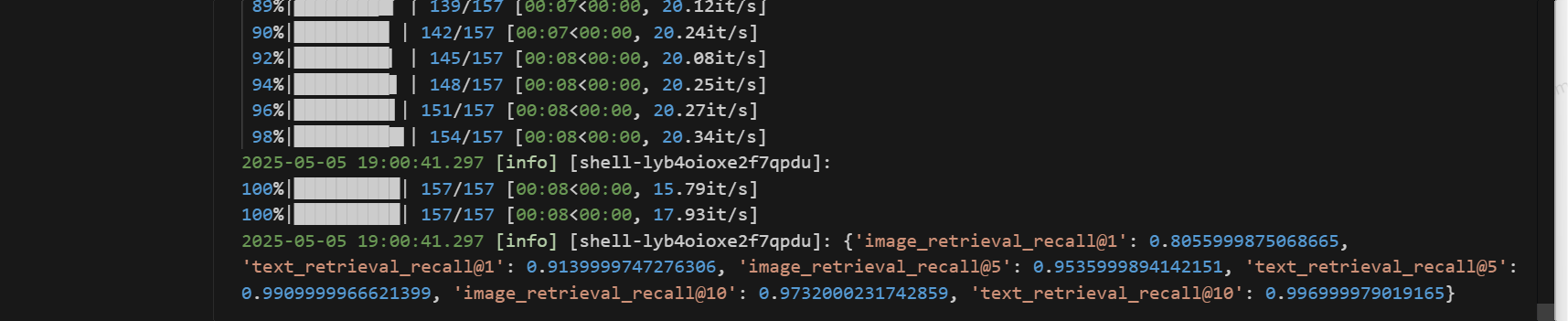
评估结果
检索性能评估指标
| 指标名称 | 数值 |
|---|---|
| 图像检索 Recall@1 | 0.8055999875068665 |
| 文本检索 Recall@1 | 0.9139999747276306 |
| 图像检索 Recall@5 | 0.9535999894142151 |
| 文本检索 Recall@5 | 0.9909999966621399 |
| 图像检索 Recall@10 | 0.9732000231742859 |
| 文本检索 Recall@10 | 0.996999979019165 |
总结
通过本实践,我们得知:1) 在不同类型的预训练数据中,检索性能持续提高。2)性能根据数据类型而波动,仅使用语言的预训练数据产生了最佳结果。3)简单地组合不同类型的预训练数据可能会意外地降低性能。
