基于RayJob(KubeRay)的分布式计算实践
KubeRay 是一个 Kubernetes 原生的分布式计算框架,用于管理和调度 Ray 集群。Ray 是一种高性能的分布式计算框架,支持机器学习、分布式训练、数据处理等任务。KubeRay 通过将 Ray 与 Kubernetes 集成,提供了自动化的资源管理和弹性扩展能力,方便用户在云原生环境中运行分布式任务。
本教程主要利用RayJob来实现基于Pytorch的分布式训练的实现。
方案概述
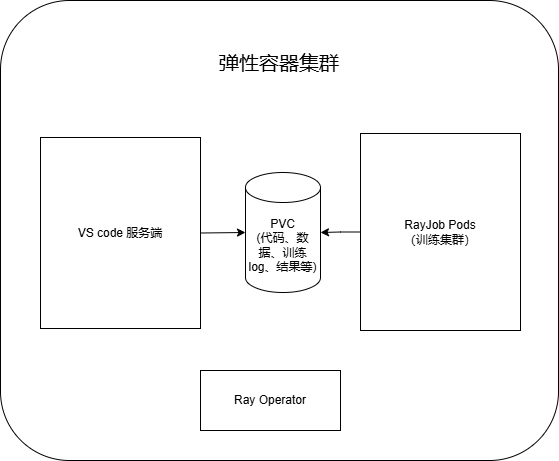
该方案基于KubeRay框架,通过RayJob来启动一个RayCluster,并在该集群上运行分布式计算任务。当任务完成后,KubeRay会自动释放该集群资源。
使用RayJob的优点:
- 自动化:无需手动创建集群,只需提交任务即可启动分布式计算任务。
- 弹性:集群资源按需使用,当任务结束后,集群会自动释放资源,节省GPU等资源的占用。
当然,使用RayJob的时候,集群启动后将开启分布式计算任务,因此需要注意以下几点:
- 集群启动完成后,分布式计算需要的数据要准备完备,包括数据、代码、环境等。
- 计算任务需要的资源(如GPU、CPU等)需要预留足够的资源,否则可能会导致资源不足而任务失败。
- 计算任务的完成后,集群资源会自动释放,因此计算任务的输出结果需要保存到外部存储,以便后续使用。
因此,本方案中采用PVC(Persistent Volume Claim)来共享计算的代码、数据等,并保存计算任务的输出结果。
另外,通过VS Code,可以同时挂载PVC,那么就可以在VS Code中编辑代码、管理数据,并实时查看任务的输出结果。
操作步骤
部署前准备工作
本次部署使用到Docker和Kubernetes,请准备好Docker环境,并确保本地有可用的Kubernestes客户端工具kubectl。
Docker环境安装请参考: 安装Docker
kubectl安装请参考:安装命令行工具(kubectl)
开通集群
资源最低要求
| 资源类型 | 数量 | 说明 |
|---|---|---|
| GPU | 3个起 | gpu-h800 |
| CPU | 32 core起 | |
| 内存 | 256G 起 | |
| 存储 | 200G起 | |
| 镜像仓库 | 100G | 用于保存镜像 |
申请开通
开通集群请参考:开通弹性容器集群
开通对象存储:对象存储的开通及管理
开通镜像仓库:镜像仓库的开通及管理
接下来的步骤中需要用实际的集群信息来替换下面的示例信息。
| 变量名 | 所在文件 | 例子 |
|---|---|---|
| 镜像仓库地址 | job/ray-job-example.yml | registry.hd-01.alayanew.com:8443/alayanew-******-5cfd029439a8 |
| GPU_resource_name | job/ray-job-example.yml | gpu-h800 |
| 镜像仓库域名 | operator/default/harbor-config.json | registry.hd-01.alayanew.com:8443 |
| 用户名 | operator/default/harbor-config.json | hb_abc123 |
| 密码 | operator/default/harbor-config.json | 123456 |
VS Code远程开发环境搭建
可以采用不同的方案,请参考:
本教程采用VS Code网页远程开发。其中的Code-Server容器挂载了共享PVC。
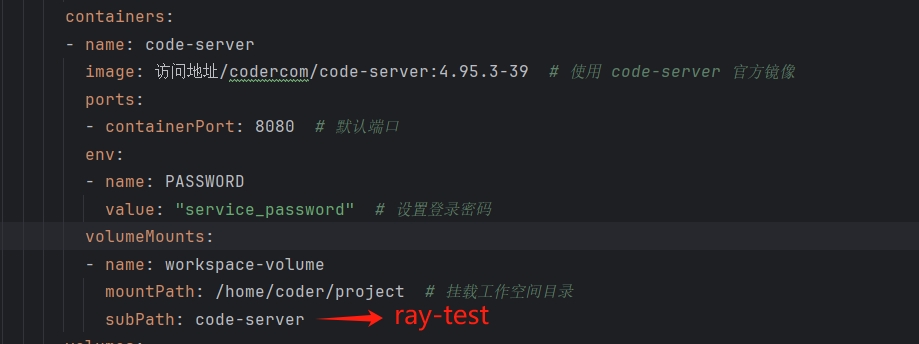
注意:因为Code-Server容器和ray-job数据共享,双方挂载的目录必须是同一个,因此需要指定相同的subPath。
请在deploy-code-server.yml文件中,将subPath改为ray-test。
安装KubeRay
整个安装过程包括以下步骤(采用Kustomize安装),本次部署采用quay.io/kuberay/operator:v1.2.2版本:
- 下载ray-operator镜像并推送到Alaya NeW的镜像仓库。
- 准备脚本
- 部署ray-operator
准备ray-operator镜像
用户名密码:查看开通镜像仓库时的通知短信
镜像仓库地址:参考镜像仓库的使用
镜像仓库地址: 由 镜像仓库域名/项目 组成
请参考以下脚本:
#!/bin/bash
docker pull quay.io/kuberay/operator:v1.2.2
docker tag quay.io/kuberay/operator:v1.2.2 镜像仓库地址/kuberay/operator:v1.2.2
docker login -u [用户名] -p [密码] [镜像仓库域名]
docker push 镜像仓库地址/kuberay/operator:v1.2.2
注意:请替换 镜像仓库地址, 域名, 用户名 密码 为自己实际的。
准备kuberay opertor部署脚本
请下载脚本文件压缩包,并解压到本地目录。按照前面说明的参数对所有文件进行变量替换。
secret准备
secret文件是用于保存敏感信息的,如对象存储的密钥等。本次部署中需要对harbor registry的用户名和密码进行加密,并保存到secret文件中。
- 当执行过前面的步骤后,请将harbor-config.json中的内容做base64编码。linux中可以使用base64命令进行编码。或者在线网站也可以进行编码。可以参考:https://tool.lu/encdec/
- 将编码后的内容保存到operator/default/harbor-secret.yml的.dockerconfigjson字段。 例子:
apiVersion: v1
kind: Secret
metadata:
name: alaya-harbor-secret
type: kubernetes.io/dockerconfigjson
data:
.dockerconfigjson: <base64编码后的内容>
部署ray-operator
在operator/default目录下,执行以下命令:
#!/bin/bash
# 注意,因为脚本文件太长,需要使用kubectl create命令,而不是kubectl apply命令。
kubectl create -k .
确保执行过程中没有错误。
#!/bin/bash
kubectl get po -n ray-test
# 可以看到ray-operator的pod状态为Running(启动需要一段时间)
# NAME READY STATUS RESTARTS AGE
# kuberay-operator-846fd57ff7-zgtfq 1/1 Running 0 25m
kubectl api-resources
# 可以看到其中有rayclusters、rayjobs等资源类型
# rayclusters ray.io/v1 true RayCluster
# rayjobs ray.io/v1 true RayJob
# rayservices ray.io/v1 true RayService
工作镜像准备
本教程将使用Pytorch进行一个简单的分布式训练任务,使用NVIDIA GPU做加速。因此,需要准备一个包含Pytorch、CUDA、NCCL等依赖的镜像。
这里我们使用Ray官方提供的镜像 rayproject/ray-ml,本次实验采用版本nightly.241204.80e698-py310-gpu。
#!/bin/bash
docker pull rayproject/ray-ml:nightly.241204.80e698-py310-gpu
docker tag rayproject/ray-ml:nightly.241204.80e698-py310-gpu 镜像仓库地址/rayproject/ray-ml:nightly.241204.80e698-py310-gpu
docker login -u [用户名] -p [密码] [镜像仓库域名]
docker push 镜像仓库地址/rayproject/ray-ml:nightly.241204.80e698-py310-gpu
注意:请替换 镜像仓库地址, 域名, 用户名 密码 为自己实际的。
当执行完毕后,请检查镜像仓库中是有镜像文件rayproject/ray-ml:nightly.241204.80e698-py310-gpu存在。
关于如何查看镜像仓库,请参考:使用Harbor管理镜像资源
数据、代码准备
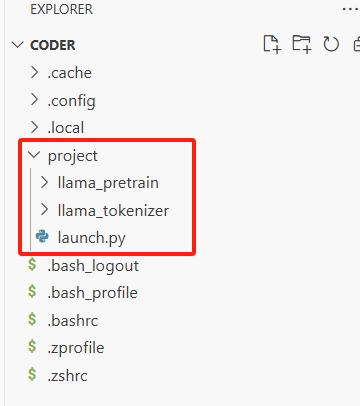
下载准备好的数据代码文件包,解压到本地目录。其中包含目录llama_pretrian、llama_tokenizer以及文件launch.py。
将这些目录和文件上传到VS Code的project目录下(可以通过拖拽完成),结果如下图所示。
代码说明
- llama_pretrian:包含训练数据集。
- llama_tokenizer:包含训练数据集的tokenizer。
- launch.py:启动分布式任务的脚本。
其中launch.py主要是为了适配ray集群工作:
- 使用@ray.remote指定start_torchrun将在集群中的每个启动的任务中执行;后面的参数num_gpus = 1指定每个任务需要的资源。
- 本教程中创建的集群包括一个主节点和两个工作节点,每个节点分配一个GPU,因此num_gpus=1。
- 使用ray.init(address="auto")初始化ray集群。
- 使用start_torchrun.remote(rank, nproc_per_node, num_nodes, master_addr, master_port)启动远程任务,并指定torchrun的参数。
- 在远程任务中输出每个任务的log,并将结果保存到文件。
import ray
from ray.util import ActorPool
@ray.remote(num_gpus = 1)
def start_torchrun(rank, nproc_per_node=1, num_nodes=1, master_addr="127.0.0.1", master_port=29500):
import os
import subprocess
import socket
# 获取主机名
hostname = socket.gethostname()
# 获取主机的 IP 地址
ip_address = socket.gethostbyname(hostname)
root_dir = '/workspace'
print(f"Node {rank} is running on {hostname}, ip address: {ip_address}")
cmd = [
"torchrun",
"--nproc_per_node", str(nproc_per_node),
"--nnodes", str(num_nodes),
"--node_rank", str(rank),
"--master_addr", master_addr,
"--master_port", str(master_port),
f"{root_dir}/llama_pretrain/llama_pretrain.py",
"--model_type", "llama",
"--config_overrides", "num_attention_heads=32,num_hidden_layers=1,num_key_value_heads=1",
"--tokenizer_name", f"{root_dir}/llama_tokenizer",
"--train_file", f"{root_dir}/llama_pretrain/data/pretrain_data.txt",
"--per_device_train_batch_size", "1",
"--per_device_eval_batch_size", "1",
"--bf16", "True",
"--overwrite_output_dir",
"--do_train",
"--do_eval",
"--logging_strategy", "steps",
"--logging_steps", "10",
"--output_dir", f"{root_dir}/llama_pretrain/tmp",
"--save_strategy", "no",
"--num_train_epochs", "1",
]
print(f"Running command: {cmd}")
# 定义日志文件路径
out_log_path = f"{root_dir}/logs/node_{rank}/out.log"
err_log_path = f"{root_dir}/logs/node_{rank}/err.log"
# 确保目录存在
os.makedirs(os.path.dirname(out_log_path), exist_ok=True)
os.makedirs(os.path.dirname(err_log_path), exist_ok=True)
# 打开日志文件
with open(out_log_path, "w") as out_file, open(err_log_path, "w") as err_file:
# 运行子进程并重定向输出
subprocess.run(
cmd,
stdout=out_file, # 重定向标准输出到 out.log
stderr=err_file # 重定向标准错误到 err.log
)
return rank
if __name__ == '__main__':
import os
ray.init(address="auto")
master_addr = ray._private.services.get_node_ip_address()
master_port = 29500 # 固定端口
num_nodes = 3 # 节点数量
nproc_per_node = 1 # 每个节点的进程数
print(f"Master Address (from Ray): {master_addr}")
tasks = [
start_torchrun.remote(rank, nproc_per_node, num_nodes, master_addr, master_port)
for rank in range(num_nodes)
]
# 收集结果
results = ray.get(tasks)
for i, rank in enumerate(results):
print(f"Node {rank} complete successfully")
执行分布式任务
进入前面下载的脚本文件目录的job子目录(确保已经按照前面所述修改字段),执行以下命令:
#!/bin/bash
kubectl apply -k .
# 执行结果:
# service/ray-service created
# serviceexporter.osm.datacanvas.com/ray-itf created
# rayjob.ray.io/rayjob-sample created
检查部署的结果:
#!/bin/bash
kubectl get po -n ray-test
# 执行结果可以发现多了4个pod,其中3个组成raycluster。rayjob-sample-nwdtp 是rayjob是job pob,管理任务。
# rayjob-sample-nwdtp 1/1 Running 0 11m
# rayjob-sample-raycluster-5stjj-head-qx87c 1/1 Running 0 11m
# rayjob-sample-raycluster-5stjj-workergroup-worker-9stdq 1/1 Running 0 11m
# rayjob-sample-raycluster-5stjj-workergroup-worker-nzgpd 1/1 Running 0 11m
通过发布出来的服务(参见发布服务)可以查看任务面板:
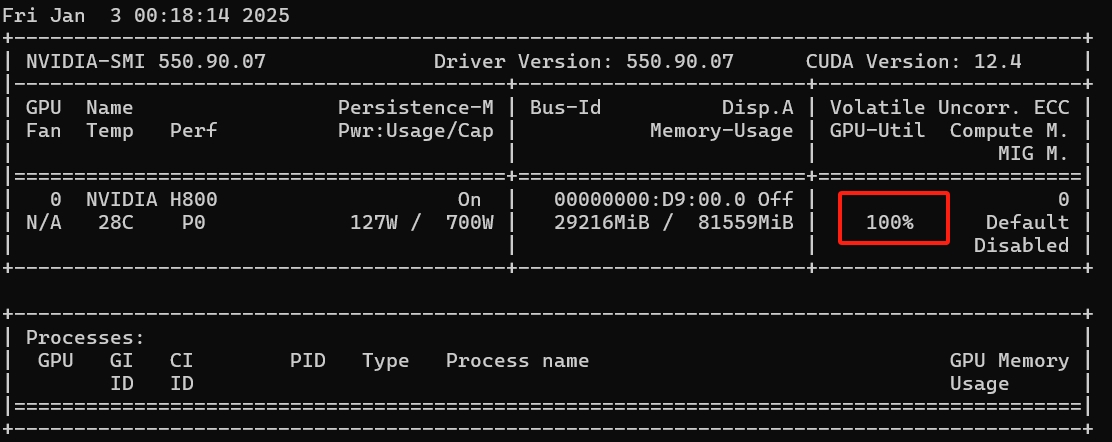
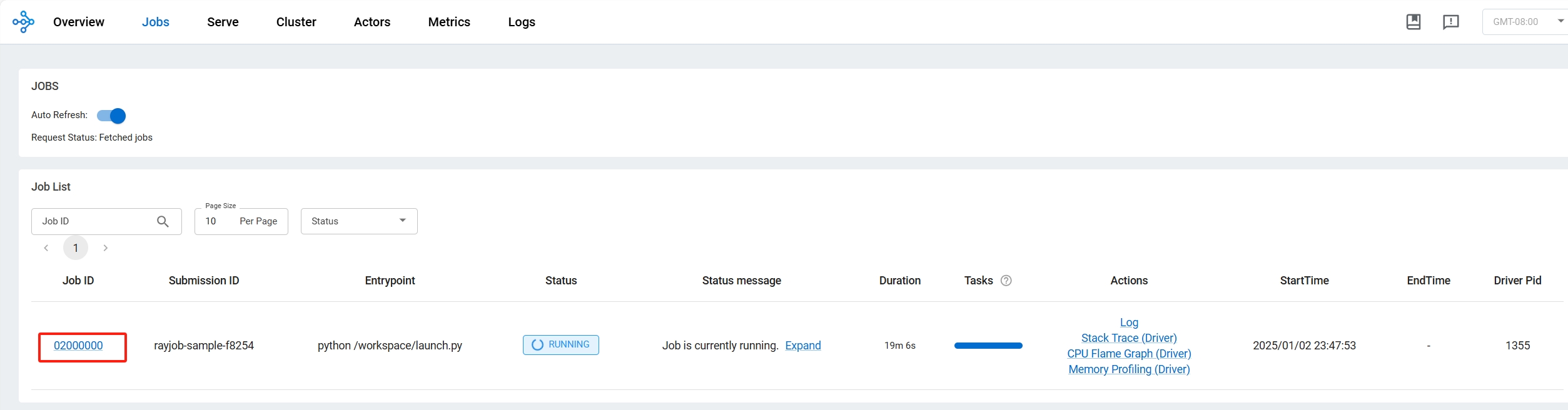 通过进入到主节点或者工作节点,可以查看GPU的工作负荷:
通过进入到主节点或者工作节点,可以查看GPU的工作负荷:
kubectl exec -it rayjob-sample-raycluster-5stjj-head-qx87c -n ray-test -- nvidia-smi
 在VS Code中,可以通过输出的日志文件查看任务的进展:
在VS Code中,可以通过输出的日志文件查看任务的进展:
在采用3块H800 GPU卡的情况下,本次训练任务大概在一个多小时候结束。当训练完成后,我们再次执行下面命令:
#!/bin/bash
kubectl get po -n ray-test
# 执行结果可以看到rayjob-sample-nwdtp的状态变为Completed。同时raycluster中的pod已经被销毁。
# rayjob-sample-nwdtp 0/1 Completed 0 72m
总结
KubeRay 是一个强大的工具,将 Ray 的分布式计算能力与 Kubernetes 的资源管理能力结合,为云原生场景下的分布式任务提供了强大支持。适合需要高性能分布式计算和动态资源管理的团队和应用场景。 本教程通过一个简单的训练任务,利用RayJob实现了Pytorch分布式训练任务的自动化调度和资源管理。利用RayJob,能够在训练完成后自动释放资源,降低资源占用率,提高资源利用率。