YOLO:让图像分类变得像呼吸一样简单
图像分类是计算机视觉领域的一项核心任务,旨在通过分析图像的视觉特征,自动将图像分配到预定义的类别中。 它是人工智能和机器学习技术在视觉理解中的重要应用,能够从复杂的图像数据中提取有价值的信息, 并广泛应用于医疗、农业、安防、自动驾驶、零售、教育、环保等多个领域。
YOLO简介
YOLO(You Only Look Once)是一种革命性的实时目标检测算法,由 Joseph Redmon 等人于 2015 年提出。
它将目标检测任务简化为一个单一的回归问题,通过一次前向传播即可同时完成目标的定位(边界框)和分类(目标类别),从而实现高效、实时的检测。
其核心功能包括:
- 目标检测
- 姿态估计
- 图像分割
- 定向目标检测
- 图像分类
其中图像分类是其功能中最简单的一项,它将整个图像分类为一组预定义类别中的一个。 图像分类器的输出是一个类别标签和一个置信度分数。图像分类在只需要知道图像属于哪个类别,而不需要知道该类别目标的位置或其确切形状时用。
YOLO11提供的模型及支持的任务
| 模型 | 模型文件名 | 支持任务 | 推理 | 验证 | 训练 | 导出 |
|---|---|---|---|---|---|---|
| YOLO11 | yolo11n.pt yolo11s.pt yolo11m.pt yolo11l.pt yolo11x.pt | 目标检测 | ✅ | ✅ | ✅ | ✅ |
| YOLO11-seg | yolo11n-seg.pt yolo11s-seg.pt yolo11m-seg.pt yolo11l-seg.pt yolo11x-seg.pt | 实例分割 | ✅ | ✅ | ✅ | ✅ |
| YOLO11-pose | yolo11n-pose.pt yolo11s-pose.pt yolo11m-pose.pt yolo11l-pose.pt yolo11x-pose.pt | 姿态估计 | ✅ | ✅ | ✅ | ✅ |
| YOLO11-obb | yolo11n-obb.pt yolo11s-obb.pt yolo11m-obb.pt yolo11l-obb.pt yolo11x-obb.pt | 定向目标检测 | ✅ | ✅ | ✅ | ✅ |
| YOLO11-cls | yolo11n-cls.pt yolo11s-cls.pt yolo11m-cls.pt yolo11l-cls.pt yolo11x-cls.pt | 图像分类 | ✅ | ✅ | ✅ | ✅ |
YOLO11各模型在数据集上的性能指标
- 目标检测(COCO)
- 图像分割(COCO)
- 图像分类(ImageNet)
- 姿态估计(COCO)
- 定向目标检测(DOTAv1)
| 模型 | size (pixels) | mAPval 50-90 | Speed CPU ONNX (ms) | Speed T4 TensorRT10 (ms) | params(M) | FLOPs(B |
|---|---|---|---|---|---|---|
| yolo11n.pt | 640 | 39.5 | 56.1 ± 0.8 | 1.5 ± 0.0 | 2.6 | 6.5 |
| yolo11s.pt | 640 | 47.0 | 90.0 ± 1.2 | 2.5 ± 0.0 | 9.4 | 21.5 |
| yolo11m.pt | 640 | 51.5 | 183.2 ± 2.0 | 4.7 ± 0.1 | 20.1 | 68.0 |
| yolo11l.pt | 640 | 53.4 | 238.6 ± 1.4 | 6.2 ± 0.1 | 25.3 | 86.9 |
| yolo11x.pt | 640 | 54.7 | 462.8 ± 6.7 | 11.3 ± 0.2 | 56.9 | 194.9 |
| 模型 | size (pixels) | mAPbox 50-90 | mAPmask 50-90 | Speed CPU ONNX (ms) | Speed T4 TensorRT10 (ms) | params(M) | FLOPs(B |
|---|---|---|---|---|---|---|---|
| yolo11n-seg.pt | 640 | 38.9 | 32.0 | 65.9 ± 1.1 | 1.8 ± 0.0 | 2.9 | 10.4 |
| yolo11s-seg.pt | 640 | 46.6 | 37.8 | 117.6 ± 4.9 | 2.9 ± 0.0 | 10.1 | 35.5 |
| yolo11m-seg.pt | 640 | 51.5 | 41.5 | 281.6 ± 1.2 | 6.3 ± 0.1 | 22.4 | 123.3 |
| yolo11l-seg.pt | 640 | 53.4 | 42.9 | 344.2 ± 3.2 | 7.8 ± 0.2 | 27.6 | 142.2 |
| yolo11x-seg.pt | 640 | 54.7 | 43.8 | 664.5 ± 3.2 | 15.8 ± 0.7 | 62.1 | 319.0 |
| 模型 | size (pixels) | acc top1 | acc top5 | Speed CPU ONNX (ms) | Speed T4 TensorRT10 (ms) | params(M) | FLOPs(B |
|---|---|---|---|---|---|---|---|
| yolo11n-cls.pt | 224 | 70.0 | 89.4 | 5.0 ± 0.3 | 1.1 ± 0.0 | 1.6 | 3.3 |
| yolo11s-cls.pt | 224 | 75.4 | 92.7 | 7.9 ± 0.2 | 1.3 ± 0.0 | 5.5 | 12.1 |
| yolo11m-cls.pt | 224 | 77.3 | 93.9 | 17.2 ± 0.4 | 2.0 ± 0.0 | 10.4 | 39.3 |
| yolo11l-cls.pt | 224 | 78.3 | 94.3 | 23.2 ± 0.3 | 2.8 ± 0.0 | 12.9 | 49.4 |
| yolo11x-cls.pt | 224 | 79.5 | 94.9 | 41.4 ± 0.9 | 3.8 ± 0.0 | 28.4 | 110.4 |
| 模型 | size (pixels) | mAPpose 50-90 | mAPpose 50 | Speed CPU ONNX (ms) | Speed T4 TensorRT10 (ms) | params(M) | FLOPs(B |
|---|---|---|---|---|---|---|---|
| yolo11n-pose.pt | 640 | 50.0 | 81.0 | 52.4 ± 0.5 | 1.7 ± 0.0 | 2.9 | 7.6 |
| yolo11s-pose.pt | 640 | 58.9 | 86.3 | 90.5 ± 0.6 | 2.6 ± 0.0 | 9.9 | 23.2 |
| yolo11m-pose.pt | 640 | 64.9 | 89.4 | 187.3 ± 0.8 | 4.9 ± 0.1 | 20.9 | 71.7 |
| yolo11l-pose.pt | 640 | 66.1 | 89.9 | 247.7 ± 1.1 | 6.4 ± 0.1 | 26.2 | 90.7 |
| yolo11x-pose.pt | 640 | 69.5 | 91.1 | 488.0 ± 13.9 | 12.1 ± 0.2 | 58.8 | 203.3 |
| 模型 | size (pixels) | mAPtest 50 | Speed CPU ONNX (ms) | Speed T4 TensorRT10 (ms) | params(M) | FLOPs(B |
|---|---|---|---|---|---|---|
| yolo11n-obb.pt | 1024 | 78.4 | 117.6 ± 0.8 | 4.4 ± 0.0 | 2.7 | 17.2 |
| yolo11s-obb.pt | 1024 | 79.5 | 219.4 ± 4.0 | 5.1 ± 0.0 | 9.7 | 57.5 |
| yolo11m-obb.pt | 1024 | 80.9 | 562.8 ± 2.9 | 10.1 ± 0.4 | 20.9 | 183.5 |
| yolo11l-obb.pt | 1024 | 81.0 | 712.5 ± 5.0 | 13.5 ± 0.6 | 26.2 | 232.0 |
| yolo11x-obb.pt | 1024 | 81.3 | 1408.6 ± 7.7 | 28.6 ± 1.0 | 58.8 | 520.2 |
本文通过最简单的图像分类,来一探YOLO的具体使用。
前置条件
本文通过kubectl命令行工具,将Docker镜像部署在弹性容器集群上,因此需要如下前置条件:
操作步骤
预训练模型及数据准备
本文档使用预训练分类模型yolo11x-cls.pt和 cifar10数据集进行测试。
从modelScope下载模型文件和数据集,modescope使用,请参考modelscope官网
如果没有安装modelscope命令行工具,请先安装:
pip install modelscope
- 下载图像分类预训练模型
yolo11x-cls.pt到本地
modelscope download --model AI-ModelScope/YOLO11 yolo11x-cls.pt --local_dir ./your-local_dir
- 下载cifar10数据集到本地
modelscope download --dataset EFate1006/CIFAR-10 data/cifar-10-python.tar.gz --local_dir ./your-local_dir
- 处理数据集 将下载的数据集解压,cifar10的数据集是二进制格式,需要处理成YOLO图像分类训练支持的如下格式
dataset/
├── train/
│ ├── class_1/
│ │ ├── image_1
│ │ ├── image_2
│ │ ├── image...
│ ├── class_2/
│ ├── image_1
│ ├── image_2
│ ├── image...
└── val/
├── class_1/
│ ├── image_1
│ ├── image_2
│ ├── image...
├── class_2/
├── image_1
├── image_2
├── image...
处理脚本如下:
import pickle
import numpy as np
import os
from PIL import Image
# 读取 CIFAR-10 数据集
def load_cifar10_batch(file_path):
with open(file_path, 'rb') as f:
data_dict = pickle.load(f, encoding='bytes')
images = data_dict[b'data'] # 图片数据
labels = data_dict[b'labels'] # 标签
images = images.reshape(-1, 3, 32, 32).transpose(0, 2, 3, 1) # 转换为 (N, H, W, C) 格式
return images, labels
# 读取训练集
train_images, train_labels = [], []
for i in range(1, 6):
file_path = f'/mnt/datasets/cifar-10-batches-py/data_batch_{i}'
images, labels = load_cifar10_batch(file_path)
print(f"labels:{labels}")
train_images.append(images)
train_labels.append(labels)
train_images = np.concatenate(train_images)
train_labels = np.concatenate(train_labels)
print(f"train_labels:{train_labels}")
# 读取测试集
test_images, test_labels = load_cifar10_batch('/mnt/datasets/cifar-10-batches-py/test_batch')
# 类别名称
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
# 创建目录
os.makedirs('/mnt/datasets/cifar10/train', exist_ok=True)
os.makedirs('/mnt/datasets/cifar10/val', exist_ok=True)
# 保存训练集图片
for i, (image, label) in enumerate(zip(train_images, train_labels)):
class_name = class_names[label]
class_dir = os.path.join('/mnt/datasets/cifar10/train', class_name)
os.makedirs(class_dir, exist_ok=True)
img = Image.fromarray(image)
img.save(os.path.join(class_dir, f'train_{i}.jpg'))
# 保存测试集图片
for i, (image, label) in enumerate(zip(test_images, test_labels)):
class_name = class_names[label]
class_dir = os.path.join('/mnt/datasets/cifar10/val', class_name)
os.makedirs(class_dir, exist_ok=True)
img = Image.fromarray(image)
img.save(os.path.join(class_dir, f'val_{i}.jpg'))
镜像准备
下载源码
从github官网下载源码
git clone https://github.com/ultralytics/ultralytics.git
准备启动文件
为了便于调试开发,启动一个FastApi服务容器,main.py如下:
from fastapi import FastAPI, File, UploadFile, Form, Query, Body
import shutil
import os
from loguru import logger
app = FastAPI()
@app.post("/upload")
async def upload_file(dataset: UploadFile = File(...), modelName: str = Form(...)):
"""
上传文件
:param dataset:
:param modelName:
:return:
"""
upload_dir = '/mnt/yolo/upload'
# 设置文件保存的路径
upload_file_path = os.path.join(upload_dir, dataset.filename)
# 保存文件到磁盘
with open(upload_file_path, "wb") as f:
shutil.copyfileobj(dataset.file, f)
logger.info('文件保存完成') # 直接从上传的文件对象复制到磁盘文件
return {"code": 0, "data": None, "message": "success"}
@app.get("/test")
async def test():
"""
测试
:return:
"""
return {"code": 0, "data": "测试服务", "message": "success"}
准备requirements.txt依赖包文件
pip==24.2
fastapi
loguru
uvicorn
python-multipart
opencv-python==4.0.6.66
准备镜像文件
将main.py和requirements.txt文件,放置到源码根目录下,根据以下Dockerfile打镜像,并推送镜像仓库。
FROM nvcr.io/nvidia/pytorch:24.07-py3
ENV DEBIAN_FRONTEND=noninteractive
ENV TZ=Asia/Shanghai
# 安装必要依赖
RUN apt-get update &&\
apt-get install -y tzdata && \
apt-get clean && rm -rf /var/lib/apt/lists/*
# 切换工作目录
WORKDIR /ultralytics
# 拷贝宿主机内容到当前工作目
COPY . .
# 安装python 包
RUN pip install --no-cache-dir -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
EXPOSE 8000
ENV PYTHONPATH=/ultralytics
CMD ["uvicorn", "main:app","--host", "0.0.0.0", "--port", "8000"]
打镜像并推送镜像仓库
关于镜像仓库使用,请参考镜像仓库的使用
用户名密码:查看开通镜像仓库时的通知短信
访问地址:由 访问域名/项目 组成
在DockerFile同目录下,指向如下命令,打包镜像
docker build -t 访问地址/ultralytics:1.0.6
将镜像推送镜像仓库
docker login 域名 -u your-username -p your-password
docker push 访问地址/ultralytics:1.0.6
创建服务
首先创建拉取镜像密钥,详情参考创建密钥
根据如下k8s文件,创建服务
apiVersion: apps/v1
kind: Deployment
metadata:
name: ultralytics-deploy
namespace: yolo
spec:
replicas: 1
selector:
matchLabels:
app: yolo
template:
metadata:
labels:
app: yolo
spec:
imagePullSecrets:
- name: harbor-secret
restartPolicy: Always
containers:
- name: yolo-container
image: registry.hd-01.alayanew.com:8443/alayanew********/ultralytics:1.0.6 # 替换为您自己的镜像名称
env:
- name: http_proxy # 环境变量名称
value: "http://100.64.1.252:8080"
- name: https_proxy # 环境变量名称
value: "http://100.64.1.252:8080"
imagePullPolicy: Always
command: ["uvicorn", "main:app","--host", "0.0.0.0", "--port", "8000"]
#command: ['/bin/bash', '-c', 'while true; do sleep 30; done']
resources:
requests:
memory: "4Gi"
cpu: "500m"
nvidia.com/gpu-h800: 1 # 请求 1 个 GPU,key替换为您开通的集群GPU资源信息
limits:
memory: "8Gi"
cpu: "2000m"
nvidia.com/gpu-h800: 1 # 限制 1 个 GPU, key替换为您开通的集群GPU资源信息
ports:
- containerPort: 8000
volumeMounts:
- name: data-volume
mountPath: /mnt
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: pvc-capacity-userdata
---
apiVersion: v1
kind: Secret
metadata:
name: harbor-secret
namespace: yolo
type: kubernetes.io/dockerconfigjson
data:
.dockerconfigjson: base64编码后的docker config.json内容
---
apiVersion: v1
kind: Service
metadata:
name: ultralytics-svc
namespace: yolo
spec:
selector:
app: yolo
type: ClusterIP
ports:
- port: 8000
protocol: TCP
targetPort: 8000
上传模型及数据
由于本次测试,模型和数据集体量较小,可以使用kubectl cp 命令,将本地模型文件及数据集,上传容器pvc挂载目录。 模型和数据集比较大的情况,请使用对象存储处理,具体请参考对象存储的使用
kubectl cp <本地文件路径> <命名空间>/<Pod名称>:/mnt/models
kubectl cp <本地文件路径> <命名空间>/<Pod名称>:/mnt/datasets
使用VS Code开发训练及推理
使用VS Code连接k8s容器进行开发,具体请参考VS Code客户端远程开发(devContainer/kubernetes)
训练
在项目根目录下,新建train_test.py,基于预训练模型yolo11x-cls.pt 和 cifar10数据集,训练新的分类模型
import json
import os
from ultralytics import YOLO
import torch
# 默认使用cpu
device = 'cpu'
# 检查是否有可用的 GPU
if torch.cuda.is_available():
print("GPU 可用")
gpu_nums = torch.cuda.device_count()
print(f"GPU 数量:{gpu_nums}")
gpu_name = torch.cuda.get_device_name(0)
print(f"GPU 设备名称:{gpu_name}")
device = 0
else:
print("GPU 不可用,将使用 CPU")
# 加载预训练模型
model = YOLO('/mnt/models/yolo11x-cls.pt')
model.to(device=device)
print(f"模型名称:{model.model_name}")
# print(f"模型信息:{model.info}")
# 使用数据集训练
# Train the model
print(f"训练开始:************")
results = model.train(data="/mnt/datasets/cifar10", epochs=1, imgsz=32)
print(f"训练结束:************")
print(f"训练结果:\n{results}")
训练过程如图:
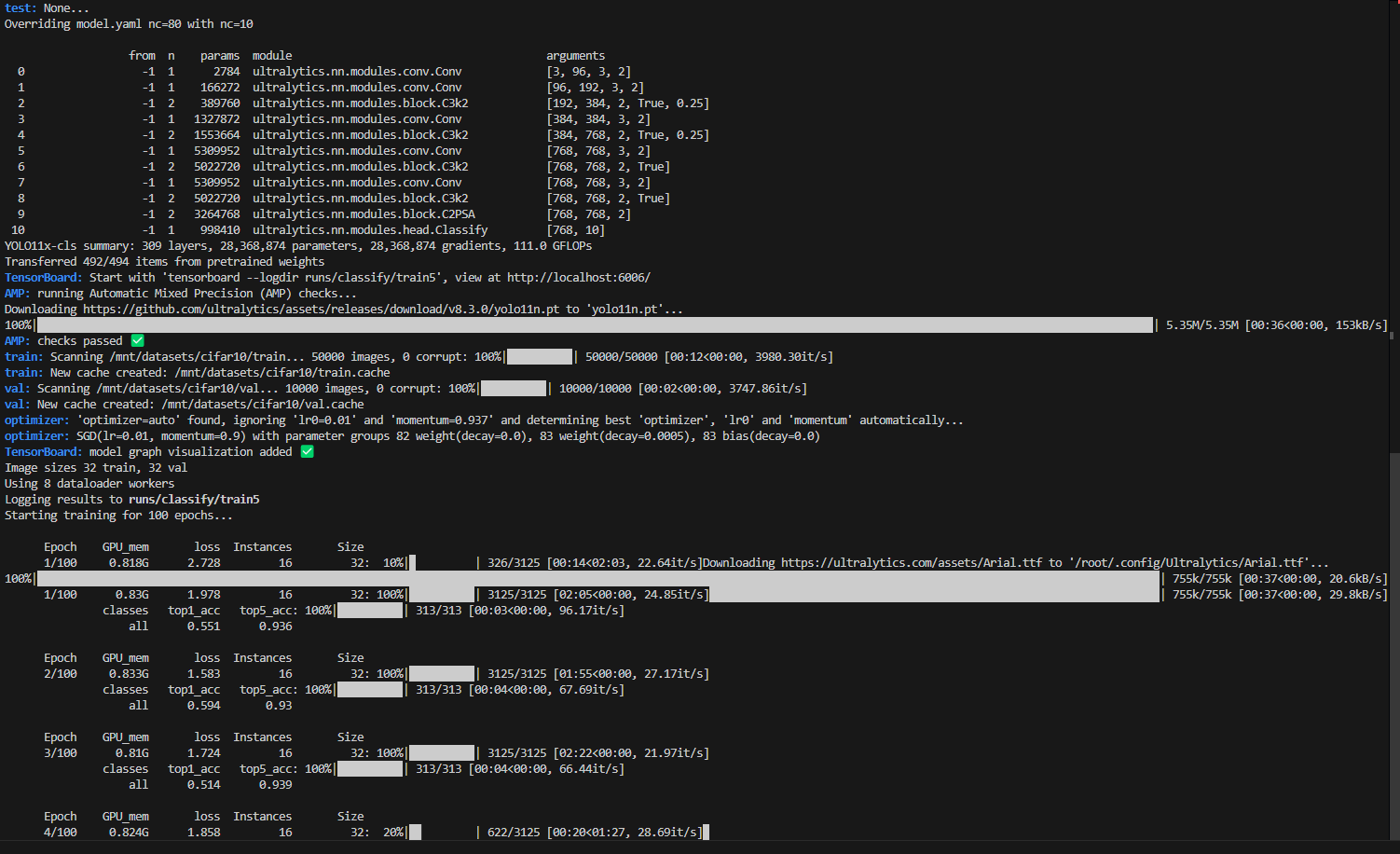
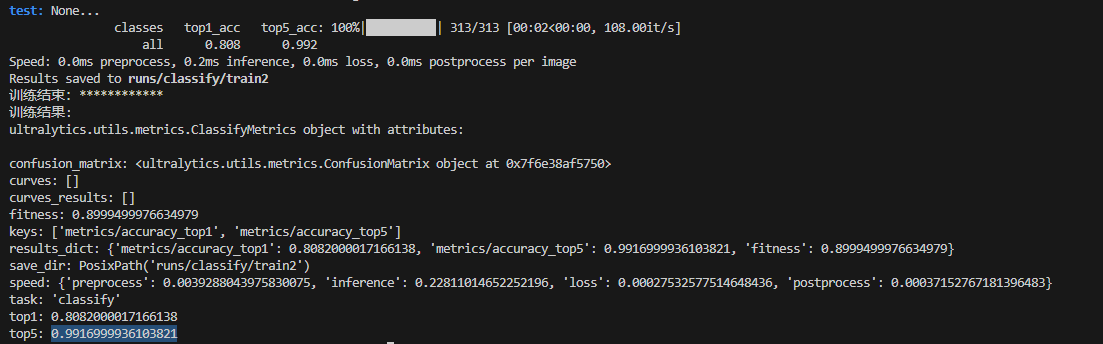
推理
在项目根目录下,新建infer_test.py,用新训练的模型,推理一张图片所属类别,代码如下:
import json
from ultralytics import YOLO
import torch
# 默认使用cpu
device = 'cpu'
# 检查是否有可用的 GPU
if torch.cuda.is_available():
print("GPU 可用")
gpu_nums = torch.cuda.device_count()
print(f"GPU 数量:{gpu_nums}")
gpu_name = torch.cuda.get_device_name(0)
print(f"GPU 设备名称:{gpu_name}")
device = 0
else:
print("GPU 不可用,将使用 CPU")
model = YOLO('/mnt/models/cifar10-cls.pt')
model.to(device=device)
print(f"模型名称:{model.model_name}")
# print(model.cuda)
# 对图片进行推理
results = model('/mnt/test_data/dog/dog6.webp', device=device) # 替换为你的图片路径
# 获取类别名称
class_names = model.names
print(f"所有分类:{class_names}")
# 使用GPU Speed: 9.2ms preprocess, 4.5ms inference, 0.1ms postprocess per image at shape (1, 3, 224, 224)
# 使用CPU Speed: 9.3ms preprocess, 256.0ms inference, 0.1ms postprocess per image at shape (1, 3, 224, 224)
print(f"结果数量:{len(results)}")
# 解析结果
for result in results:
probs = result.probs # 获取类别概率分布
# print(f"结果probs:{probs}")
top1_label = probs.top1 # 获取概率最高的类别标签
top1_confidence = probs.top1conf.item() # 获取概率最高的类别的置信度
top1_name = class_names[top1_label] # 获取类别名称
print(f"分类结果: 类别名称 = {top1_name}, 置信度 = {top1_confidence}")
结果如下:
