基于LLaMA Factory的Llama-3.1-70B医学诊断微调实践
LLaMA Factory是一款开源低代码大模型微调框架,集成了业界广泛使用的微调技术,支持通过Web UI界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架之一,GitHub星标超过4万。本示例将基于Llama-3.1-70B模型,介绍如何使用Aladdin及LLaMA Factory训练框架完成模型微调,提升Llama-3.1-70B在医学诊断和临床决策领域的专业能力,使其能理解复杂医疗描述,生成符合医学理论的诊断建议。
本示例采用多卡并行调试方案,专为大规模模型训练场景打造,聚焦计算效率与横向扩展能力,全面应对高复杂度与海量数据训练难题。支持弹性扩缩容,资源可按需调整,同时提供灵活租期选项,助力用户高效部署、降低成本,实现算力投入的最大化回报。
本示例基于Aladdin v2.3.6版本编写,不同版本间操作界面可能存在差异,用户在实际使用时以下载版本的操作界面为准。
前提条件
- 用户已经获取Alaya NeW企业账户和密码,可点击 进行快速注册。
- 当前企业账号的余额充裕,可满足用户使用推理计算服务的需要。如需了解更多请联系我们。
- 用户已在VS Code/Cursor代码编辑器内安装Aladdin插件,安装详情可参考安装Aladdin。
准备工作
开通弹性容器集群
本示例开通弹性容器集群的操作步骤如下所示。
-
使用已注册的企业账号登录Alaya NeW系统,选择[产品/弹性容器集群]菜单项,单击“新建集群”按钮,进入弹性容器集群配置页面。
-
配置基本信息,例如:集群名称,集群描述,智算中心,此次使用的集群资源配置至少需要满足以下表格中的要求。弹性容器集群参数配置完成后,单击
立即开通按钮,即可完成弹性容器集群开通操作,用户可在[资源中心/弹性容器集群]页面查看已创建的容器集群,弹性容器集群状态为“运行中”表示集群可正常使用。更多步骤可参考开通弹性容器集群。本次弹性容器集群的配置如下所示。配置项 配置需求 说明 GPU H800 * 8 GPU类型为: H800 存储 300GB - 镜像仓库 100GB 用于保存镜像文件等数据
下载模型
LLaMA Factory涉及示例均在Aladdin的Workshop中演示,创建Workshop的操作步骤如下所示。
-
在VS Code扩展菜单栏搜索Aladdin插件,然后安装该插件。安装插件后,点击插件图标,进入插件登录页面,使用已注册的企业账号登录Aladdin。
-
登录完成后,返回工作区,单击
 进入新建一个Workshop配置页面,填写参数,例如下图所示。
进入新建一个Workshop配置页面,填写参数,例如下图所示。 信息
信息- Environment:运行环境选择预置的
aladdin/llamafactory公共镜像仓库下的镜像。 - VKS:选择用户已开通的弹性容器集群。
- PVC MOUNTS:挂载的SubPath填写开通弹性容器集群时在文件存储目录下新建的文件夹名称,ContainerPath填写
/workspace。
- Environment:运行环境选择预置的
-
配置完成后,单击“Submit”按钮,在弹出的新窗口(后文统称远端页面)选择"Linux",远端页面将自动安装相关插件,待远端页面中出现Remote Aladdin插件图标,Workshop创建操作完成。
-
按
Ctrl+Shift+P(Windows/Linux),打开命令面板,选择Python: Select Interpreter,选择下图高亮所示的Python解释器,然后打开“/workspace/”文件夹。
-
选择[Terminal/New Terminal]菜单项,进入终端页面,在终端页面执行如下命令设置对应区域的镜像地址,查看区域模型列表。更多模型下载加速内容请参看模型加速文章所述。
export HF_ENDPOINT=http://hfmirror.mas.zetyun.cn:8082
curl http://hfmirror.mas.zetyun.cn:8082/repos -
运行如下所示的命令安装huggingface-hub,如下图高亮①所示。
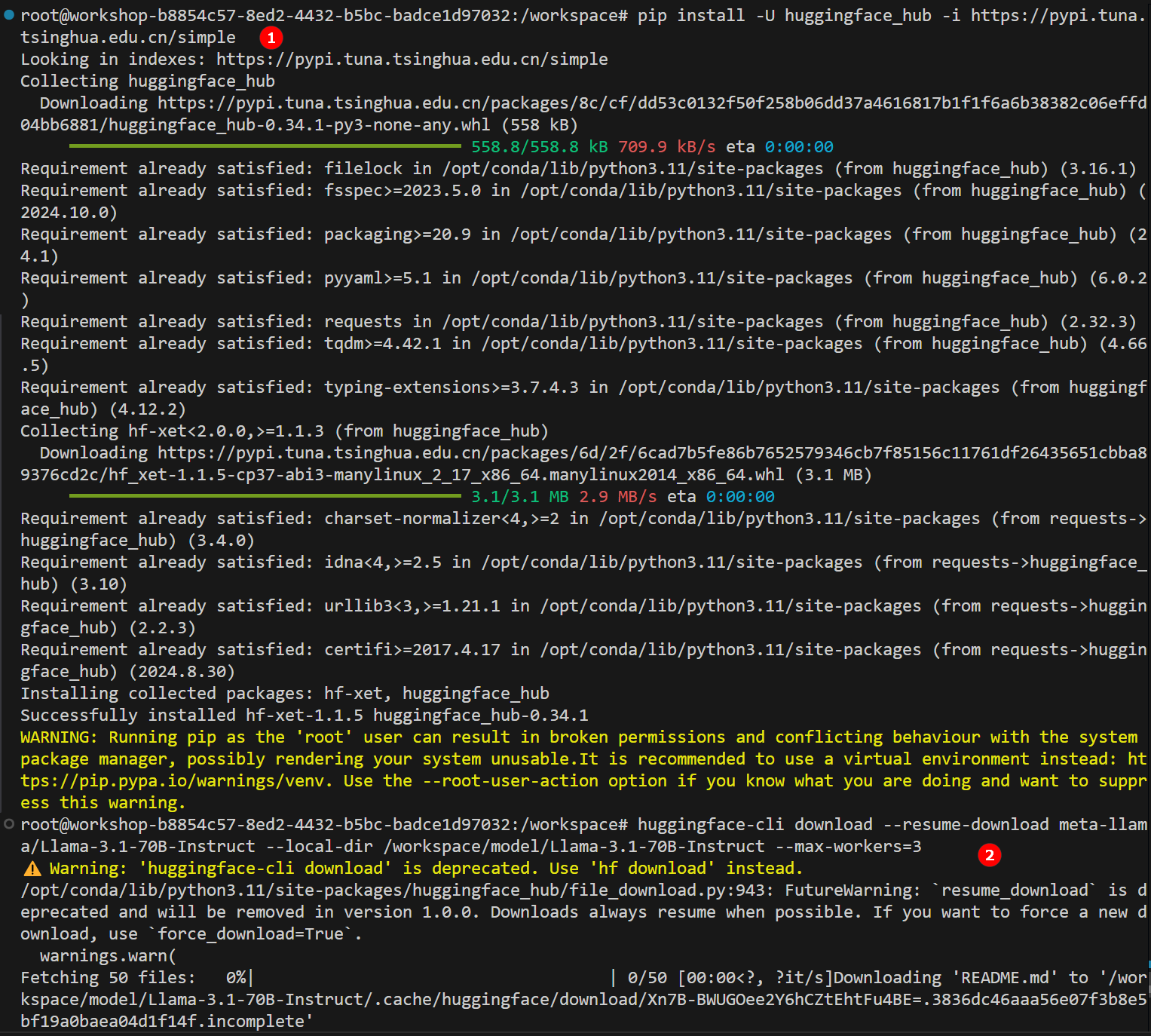
pip install -U huggingface_hub -i https://pypi.tuna.tsinghua.edu.cn/simple -
使用huggingface cli下载模型meta-llama/Llama-3.1-70B-Instruct,如上图高亮②所示。
huggingface-cli download --resume-download meta-llama/Llama-3.1-70B-Instruct --local-dir /workspace/model/Llama-3.1-70B-Instruct --max-workers=3
LLaMA Factory准备
-
用户创建Workshop时选择的环境中已内置了LLaMA Factory源码,因此在此处将LLaMA Factory源码复制到Workshop挂载目录下即可,复制命令如下所示,示例页面如下图所示。

cp -r [源码目录] /[挂载目录] -
点击下载Aladdin启动LLaMA Factory脚本文件,在本地解压下载后的文件,并将final.sh、start.sh文件拖拽至LLaMA Factory源码文件夹下,然后在上述文件所在目录下分别执行如下所示的命令。
chmod +x start.sh
chmod +x final.sh提示- 用户需将start.sh文件中LLaMA Factory的源码路径修改为实际的源码路径。
- 用户需将final.sh文件中LLaMA Factory的源码路径修改为实际的源码路径。
下载数据集
-
下载微调数据集后解压到本地,将
jsonl文件拖拽到LLaMA Factory/data文件下。 -
修改LLaMA Factory/data文件夹下“dataset_json.info”文件,在json文件开始位置添加如下所示脚本。
"medical_sft": {
"file_name": "/workspace/LLaMA-Factory/data/medical_o1_sft_Chinese_alpaca_cot.jsonl",
"columns": {
"prompt": "prompt",
"response": "response"
}
}
可视化工具准备
SwanLab是一款开源且轻量级的AI模型训练可视化追踪工具。在本次微调任务中,我们将使用SwanLab记录整个微调过程。在开始之前,请确保您已经登录SwanLab平台。登录后,点击“设置/常规”,即可获取API Key,示例如下图所示。

在start.sh文件页面添加安装SwanLab的命令行,命令如下所示,添加位置如下图所示。
pip install swanlab deepspeed==0.16.4 -i https://pypi.tuna.tsinghua.edu.cn/simple/
操作步骤
完成准备工作后,用户开始进行微调,具体的操作步骤如下所示。
-
在
final.sh文件编辑界面中,右键点击页面的空白处,在弹窗菜单中选Run Shell,如下图所示。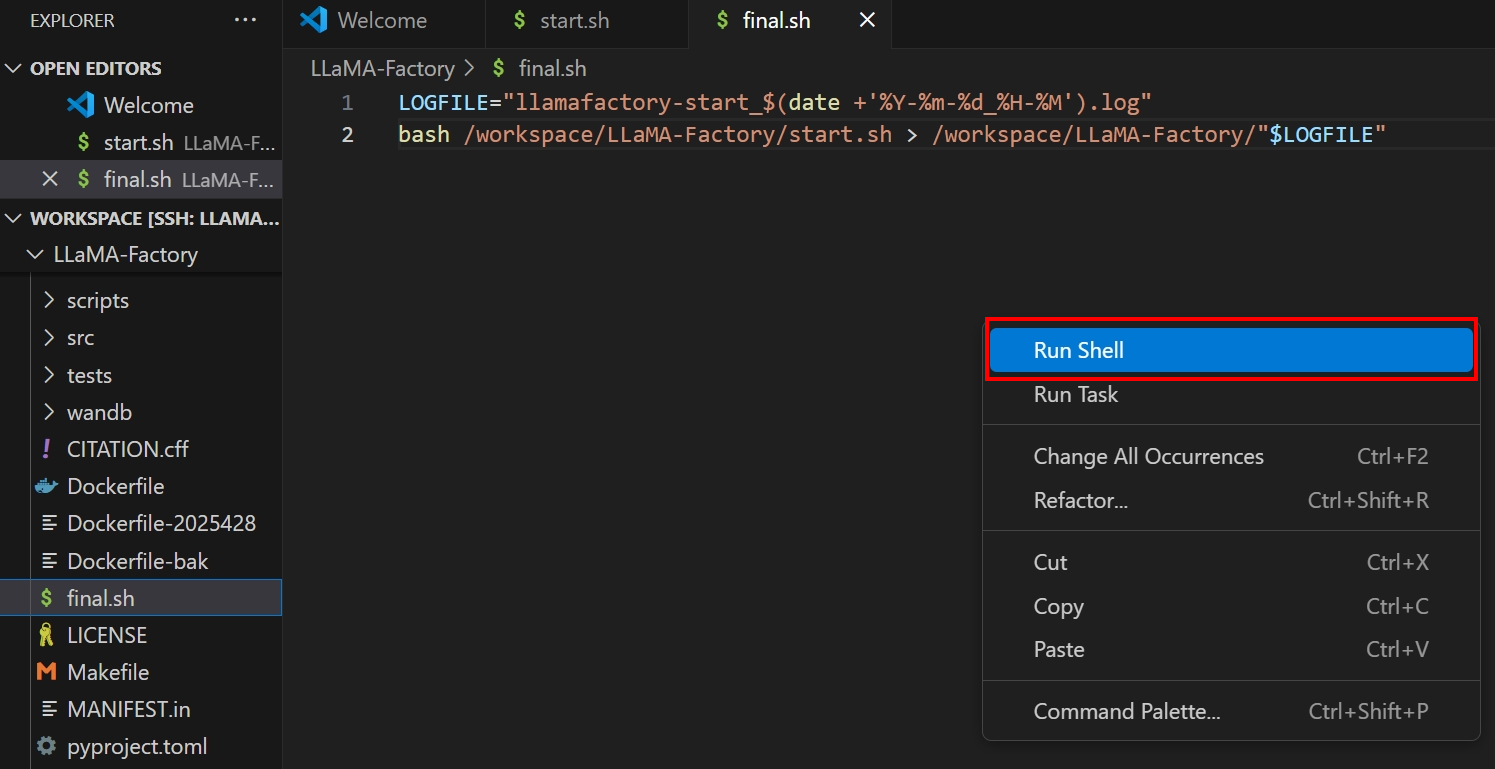
在参数配置页面配置环境、资源等参数,其中资源配置8卡,GPU类型选择如下图所示。
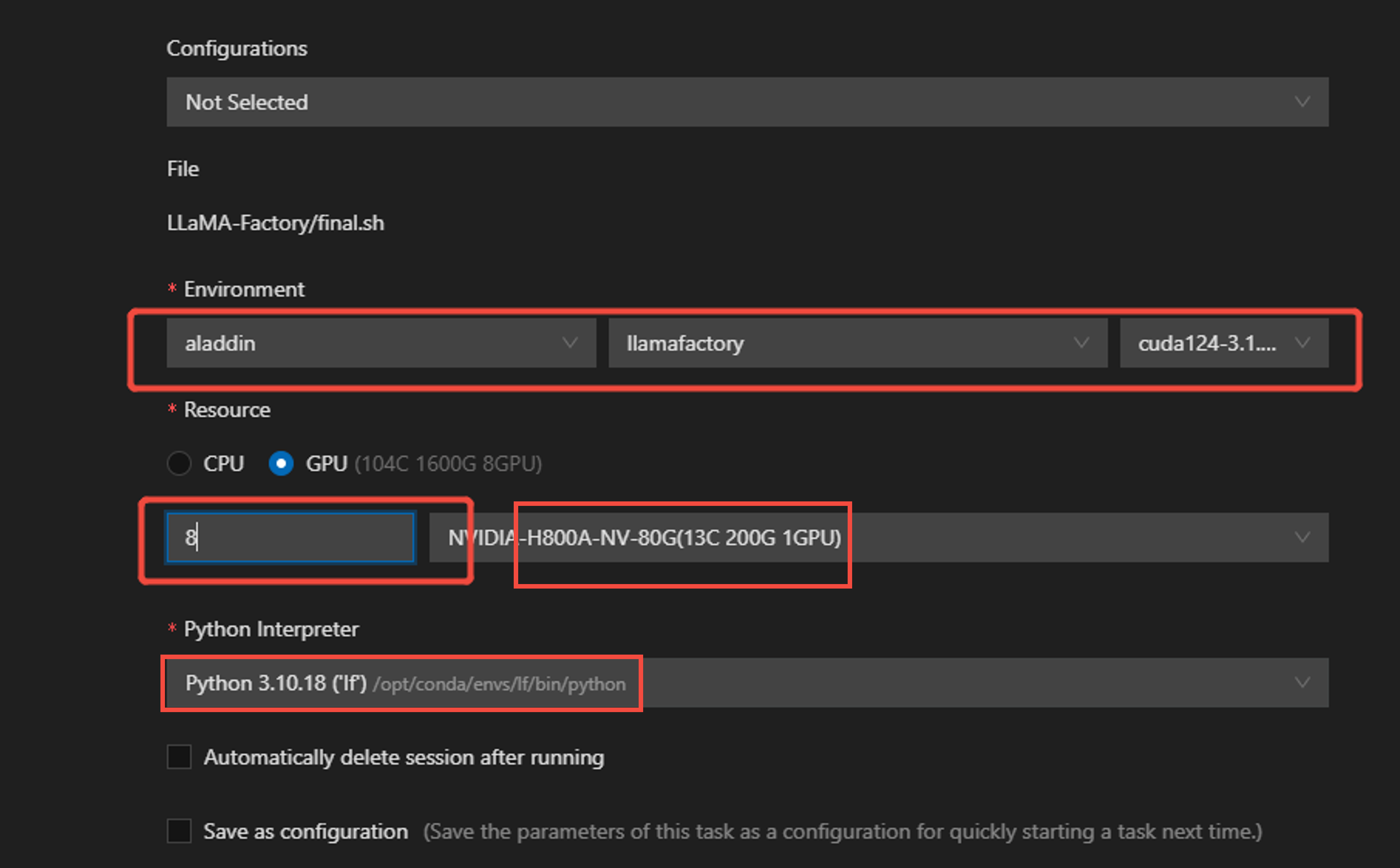
-
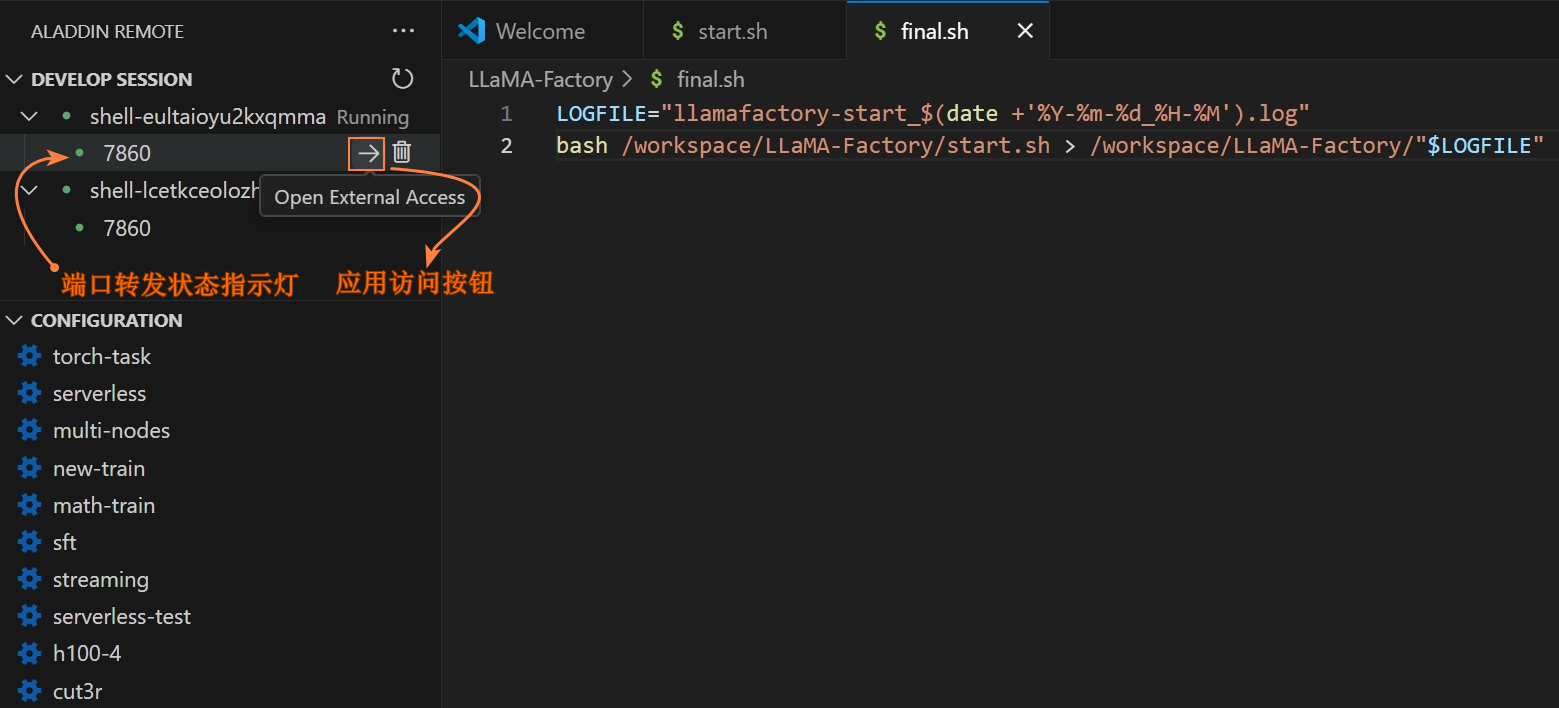
在参数配置页面展开“Advanced”配置,点击下方的“Add External Access”,新增一个外部访问配置,在输入框中填写7860端口,例如下图所示。
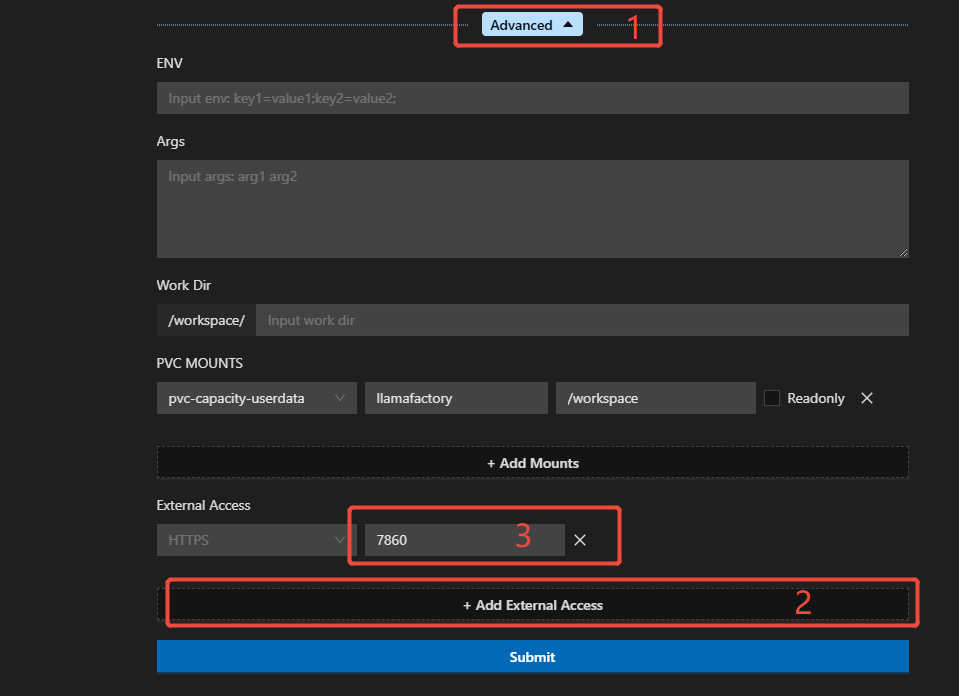
-
配置完成后,点击“Submit”按钮,系统创建DEVELOP SESSION。
-
当外部访问状态提示灯变为绿色时,点击箭头图标即可访问应用。弹窗口中选择“打开外部网站”,用户即可通过WebUI访问该应用。
-
进入WebUI后,可以切换到中文(zh),如下图高亮①。本实践选择
LLama-3.1-70B-instruct模型,如下图高亮②所示。微调方法则保持默认值lora,使用LoRA轻量化微调方法能极大程度地节约显存。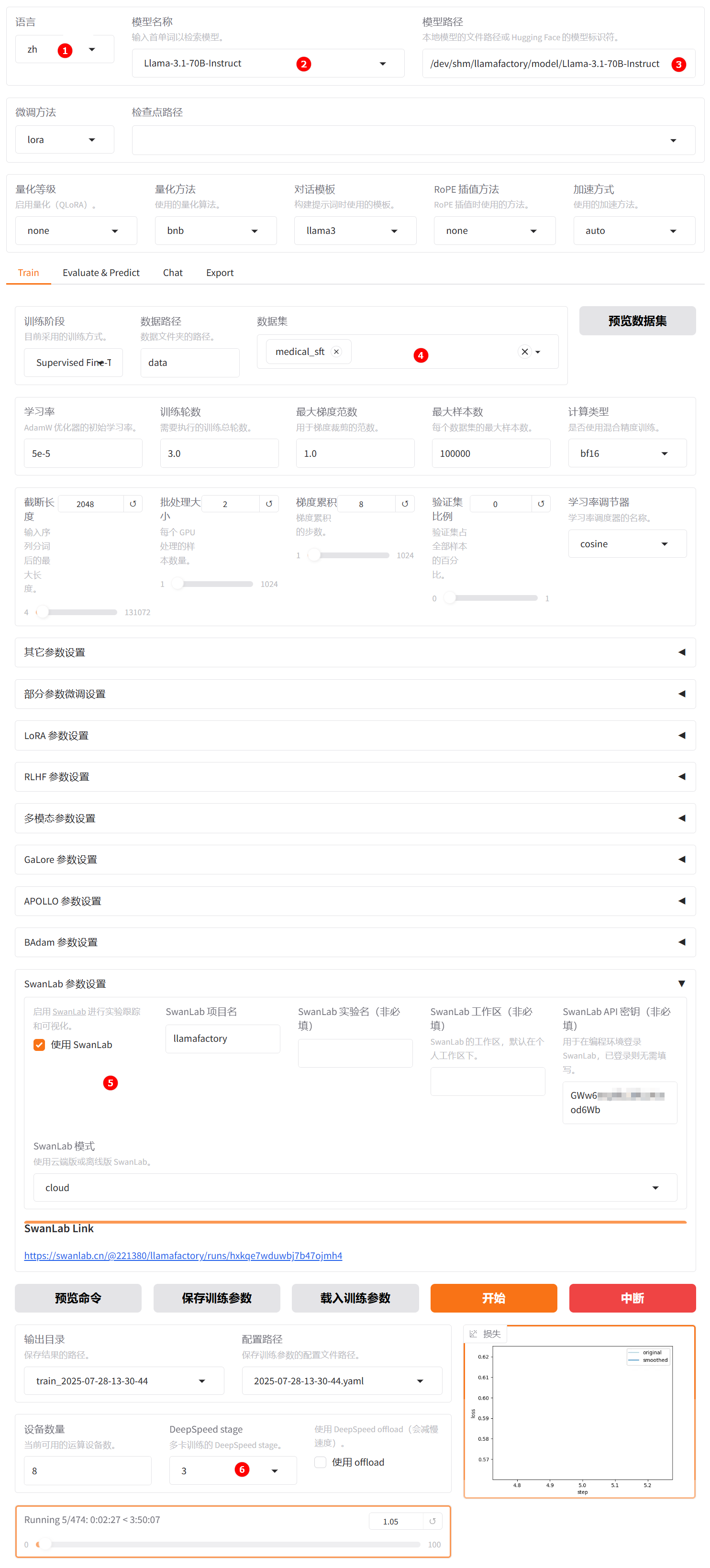
-
数据集使用
medical_sft,例如上图高亮④所示。找到SwanLab参数设置菜单栏,勾选使用SwanLab选项,在SwanLab API秘钥处填写准备工作章节已获取的API Key,如上图高亮⑤所示。 -
将
DeepSpeed Stage设置为3,点击“预览命令”可展示当前所有配置,您如果想通过代码运行微调,可以复制这段命令,在命令行运行;本次实践选用WebUI方式微调,点击“开始”启动模型微调。 -
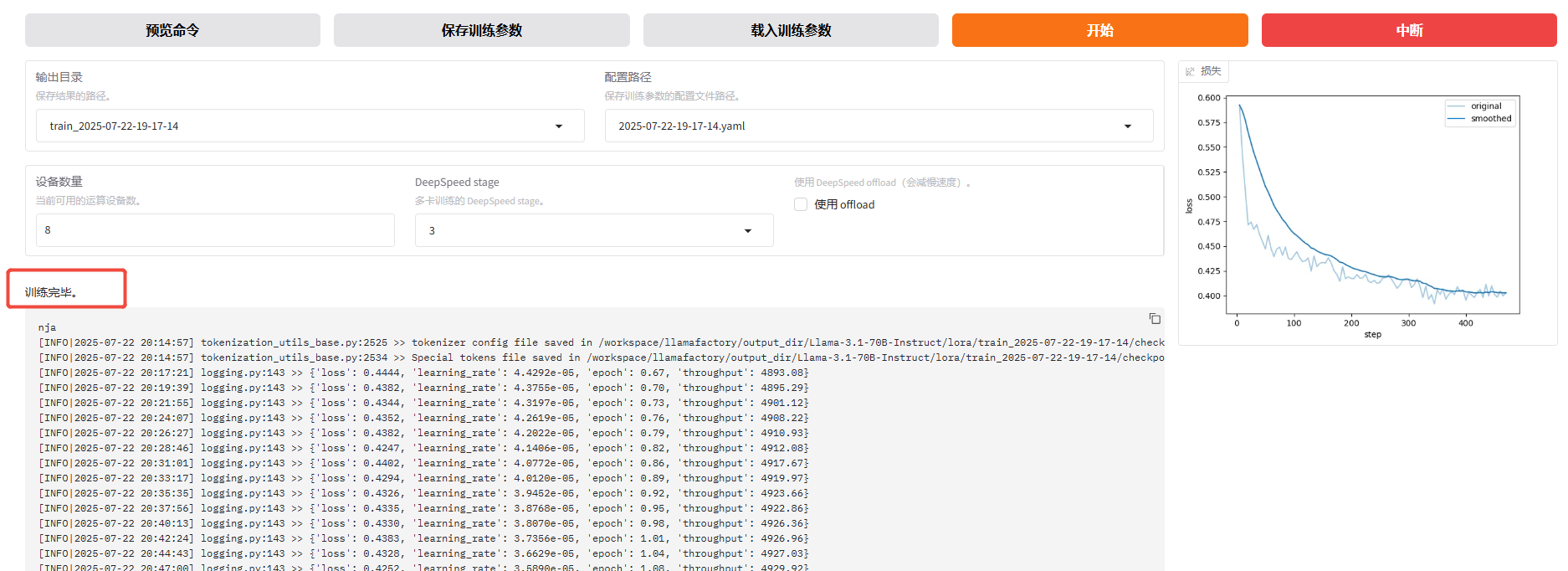
开始微调后,页面下方会显示微调的日志。用户可在已登录的SwanLab的“实验”处查看各类图表,例如下图所示。

同时,也将呈现微调的进度以及Loss曲线。进行多轮微调后示例页面如下图所示,从图中可看出Loss趋近收敛,微调完成后,输出框显示“训练完毕”。
-
训练完成后在WebUI界面,检查点路径处选择已经微调过的模型路径,例如下图高亮2所示,单击“加载模型”按钮,加载微调后的模型,如下图高亮3所示,选择“chat”页签,使用加载好的微调模型进行对话。

- 微调后模型对话
- 原生模型对话
-
在页面底部的对话框输入想要和模型对话的内容,单击“提交”按钮发送消息。观察模型的回复,发现它能够给出具体且有针对性的建议。
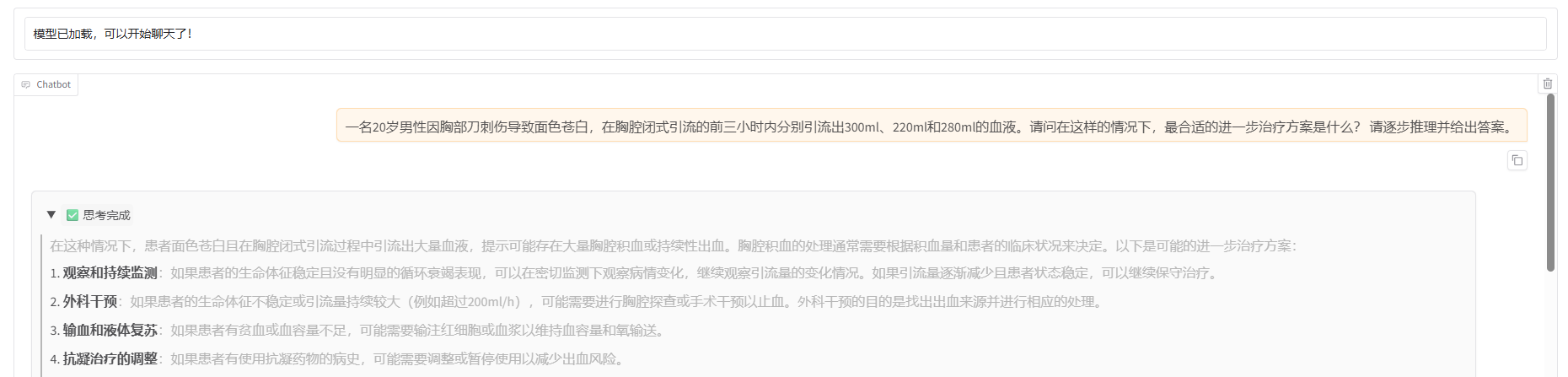

-
清空“检查点路径”LoRA配置,然后单击“加载模型”按钮,切换至原生的
Llama-3.1-70B-Instruct模型,在页面底部的对话框输入相同的问题,观察模型的回复,发现原始模型仅能提供常识性或表面化的建议,缺乏深入思考能力,。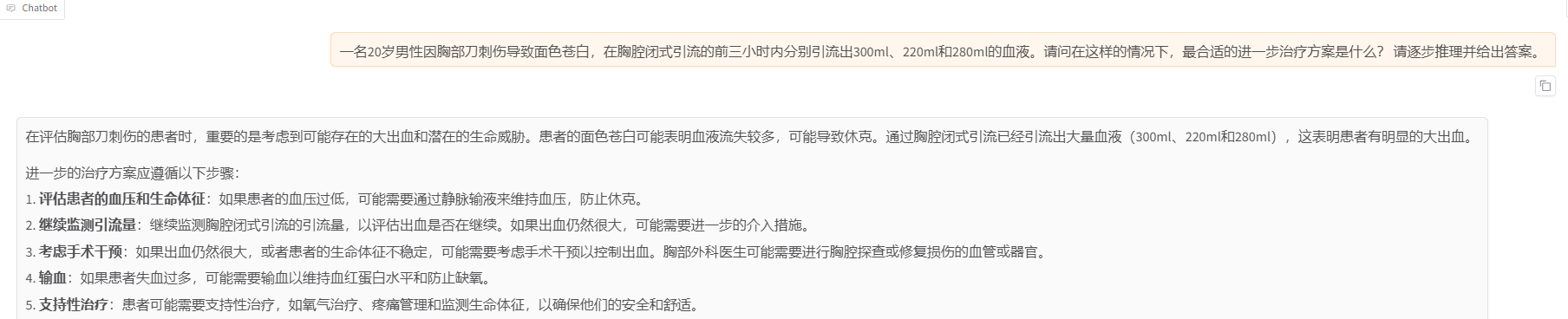

综合看来通过使用微调后的模型进行对话,可以获得更具参考价值的回答。相较于原生模型,后者往往提供的是宽泛且笼统的可能性描述,而经过特定任务或数据集微调后的模型能够基于实际的场景生成更为精准、有针对性的回答。
总结
本实践展示了如何借助Aladdin工具与LLaMA Factory框架,基于轻量级LoRA方法对Llama-3.1-70B模型进行高效微调,使其具备理解复杂医疗描述并生成专业诊断建议的能力。在大卡资源支撑下结合弹性容器集群调度机制,实现了训练资源的灵活调用与动态扩缩容。
在实际的使用中用户可按需租用GPU算力,支持小时级计费与任务级资源分配,显著降低闲置成本,加速从模型开发到部署的全流程。不论是大模型推理还是多模态任务微调,均可通过弹性集群实现快速适配,兼顾性能与灵活性。
综合来看,基于弹性容器集群的大卡微调方案具备以下优势:
- 资源弹性: 支持随任务动态扩缩,按需调度多张高性能 GPU;
- 租期灵活: 支持短租、即用即还,极大降低企业算力投入门槛;
- 效率更高: 多卡并行与容器自动调度协同优化,显著缩短微调时间;
- 适配广泛: 能力覆盖多种模型结构与训练任务,适合快速业务部署。
该方案为企业级AI应用提供了即插即用的基础架构,有效支撑从算法验证到产品上线的全流程落地。