部署服务模型
模型部署是将大模型应用到实际业务的重要环节。为了帮助用户更好的实现一站式端到端的大模型应用,平台提供了模型部署功能,部署的模型可以作为在线服务的后端提供预测能力。 通过“部署”操作最多可以部署4个模型,但可以通过将已上线的模型下线,从而使得处于部署状态的模型最大达到6个。
大模型部署时支持设置模型精度,包括FP16(半精度浮点数)、FP8(8位浮点数)、INT8(8位整数)、INT4(4位整数)。在推理阶段通过合理选择精度类型,可以显著提升模型的推理速度和资源利用率。
场景描述
部署“LLM_Model”模型。
前提条件
- 待部署模型已审核通过。
操作步骤
- 在“模型仓库”主界面,选择服务“LLM Chat服务”,进入该服务主页面。
- 在页面左侧的“侧边栏”区域,选择在线服务,系统跳转到“在线服务”列表页面。
- 在在线服务页面中,单击页面右上角的“新建部署”,系统跳转到“新建部署”页面,如下所示:
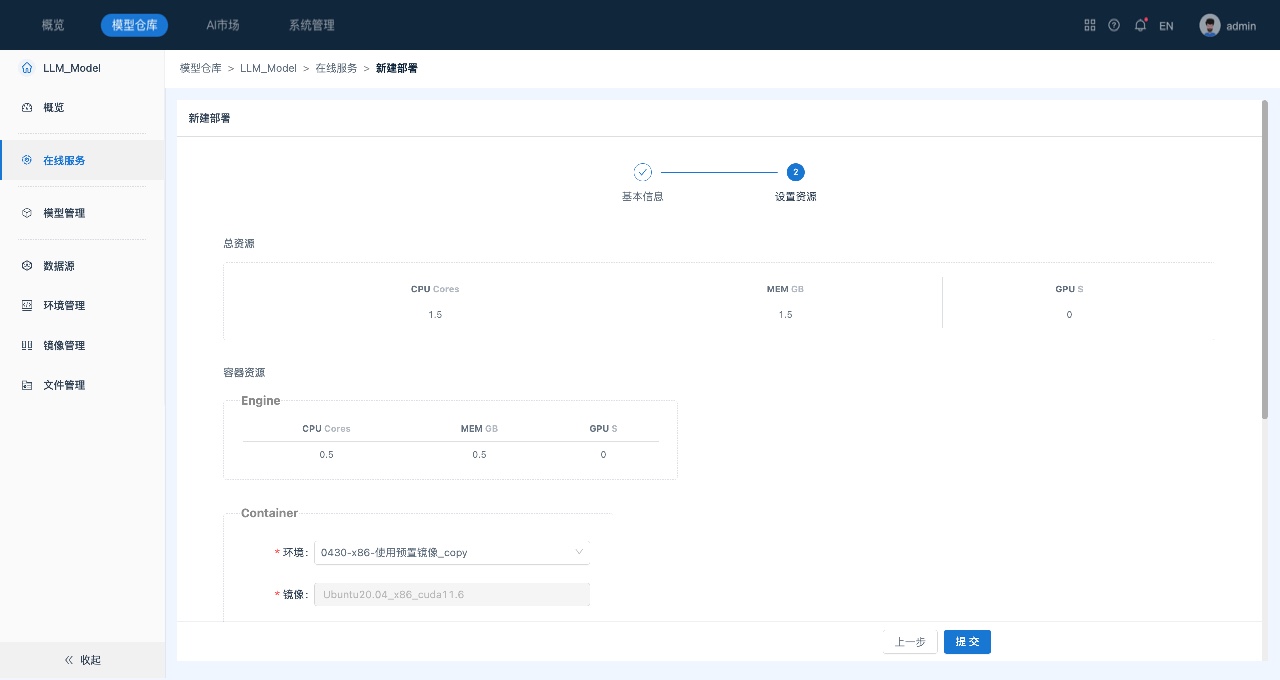
在进行模型部署时,可进行“模型精度”和“资源”配置,资源配置包括一个“Engine”容器以及一个或多个“Container”类型的容器,每个Container容器由多步transformer组成,用户可以根据计算量调整Container的资源。
4. (可选)调整Container资源。
调整资源,包括容器使用的镜像以及CPU、内存和GPU资源。
5. 单击提交,启动部署。部署过程中,支持用户进行“终止”部署的操作。
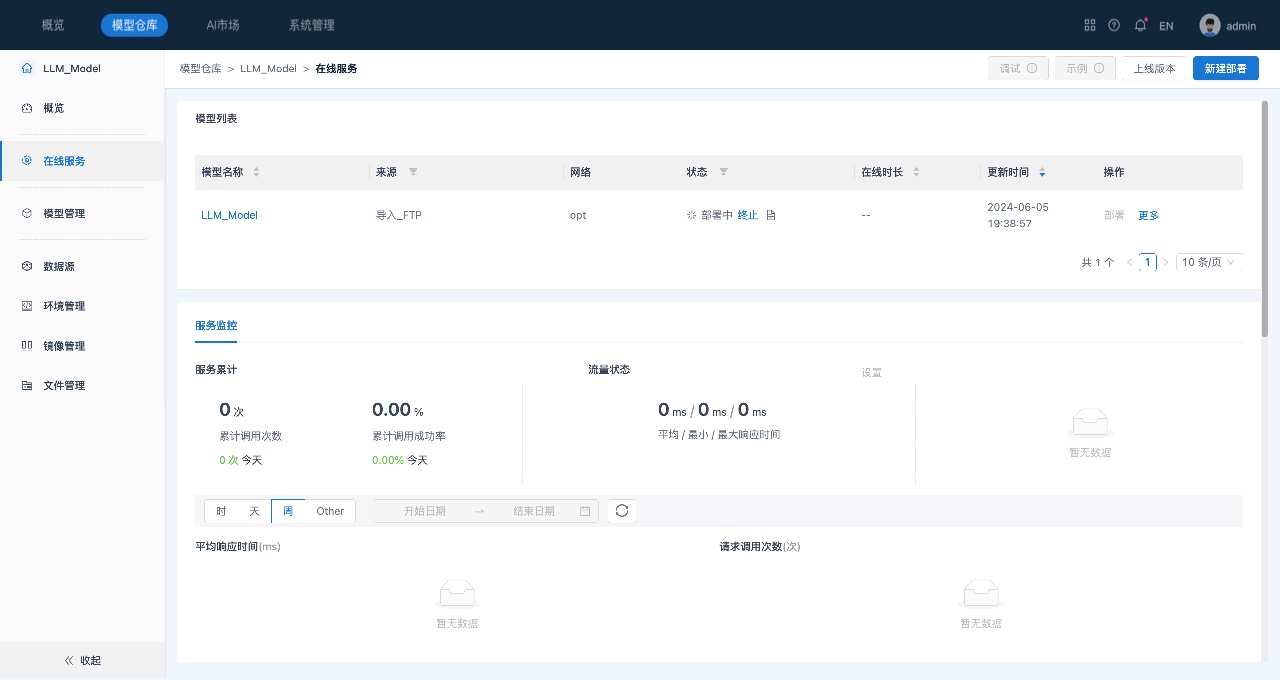
部署成功后,可以查看模型部署状态等信息:
- 状态以及日志:部署成功或失败以及具体日志信息。
- 调试:对部署成功的模型,提供交互式对话、对话API和生成API三种模型/服务调试方式,可用于内部测试。