上线服务模型
在成功部署模型后,可以将其上线,从而以服务的形式对内外部应用提供预测和调用。同时系统提供弹性伸缩、灰度发布、影子上线等特性从而帮助客户以最低的资源成本获取高并发、稳定的在线算法模型服务。
系统为用户提供三种模型上线方式:正式上线、灰度上线和影子上线,最多支持同时上线两个模型,即用户可以同时实现模型的正式上线和灰度上线或者正式上线和影子上线。
- 正式上线:通过该方式部署的模型作为服务后端,接收客户端发送的请求数据并返回预测结果。一个服务中上线的第一个模型为正式上线。
- 灰度上线:通过该方式部署的模型作为服务后端并对部分请求流量进行处理,其余流量仍通过正式上线的模型进行处理。当有新版本的模型需要上线时,可以使用灰度上线,从而实现服务后端的平稳迁移。
- 影子上线:在不影响正式模型的前提下,在模型提供在线服务的过程中复制正式上线模型的全部流量。
场景描述
上线“LLM_Model”模型。
前提条件
- 待上线模型已部署成功。
操作步骤
- 在“模型仓库”主界面,选择服务“LLM Chat服务”,进入该服务主页面。
- 在页面左侧的“侧边栏”区域,选择在线服务,系统跳转到“在线服务”列表页面。
- 在在线服务“模型列表”中,单击模型所在行的“上线”,系统显示“上线”对话框,如下所示:
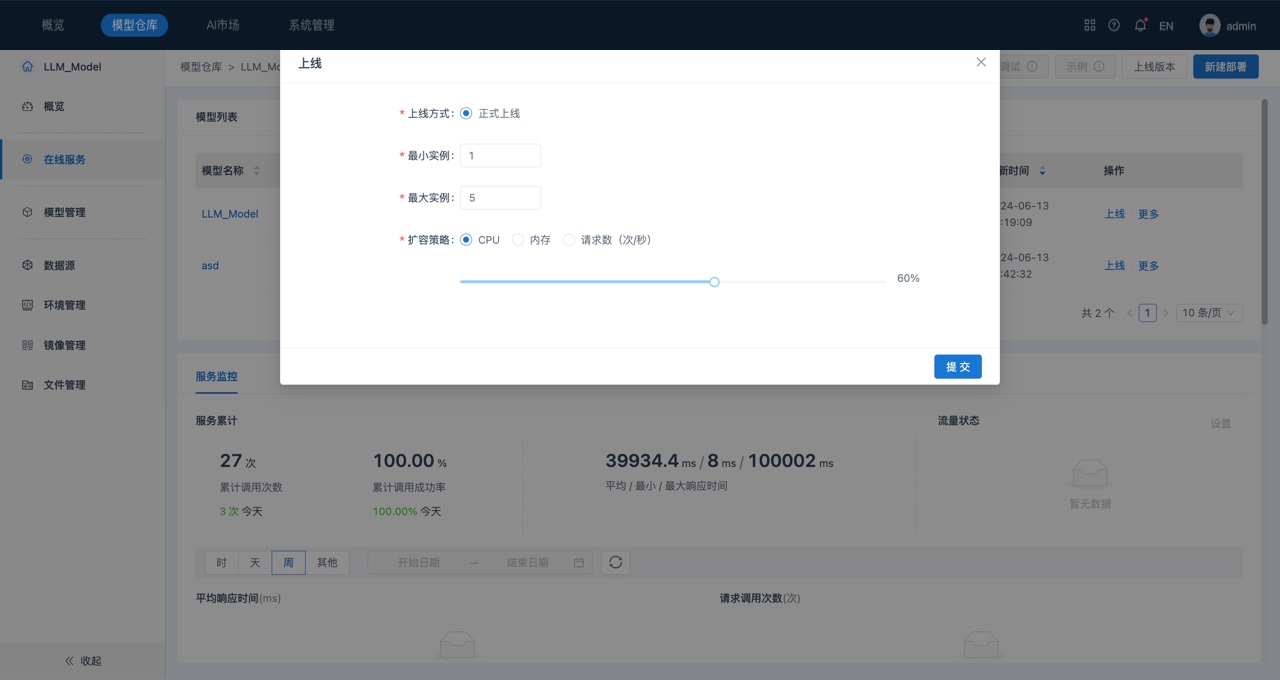
在“上线”对话框中可以设置模型的最小、最大实例数量和扩容策略,上线后,实例的CPU、内存和请求数达到扩容策略的设置值时,系统会自动动态调整实例数量。
当前上线模型为该服务的第一个模型,因此其上线方式为“正式上线”。
5. 完成上线配置并单击提交。
上线后,“模型列表”中模型的状态会变更为“已上线”。
6. 灰度上线。在“模型列表”中,单击“部署完成”模型所在行的“上线”,系统显示“灰度上线”对话框:
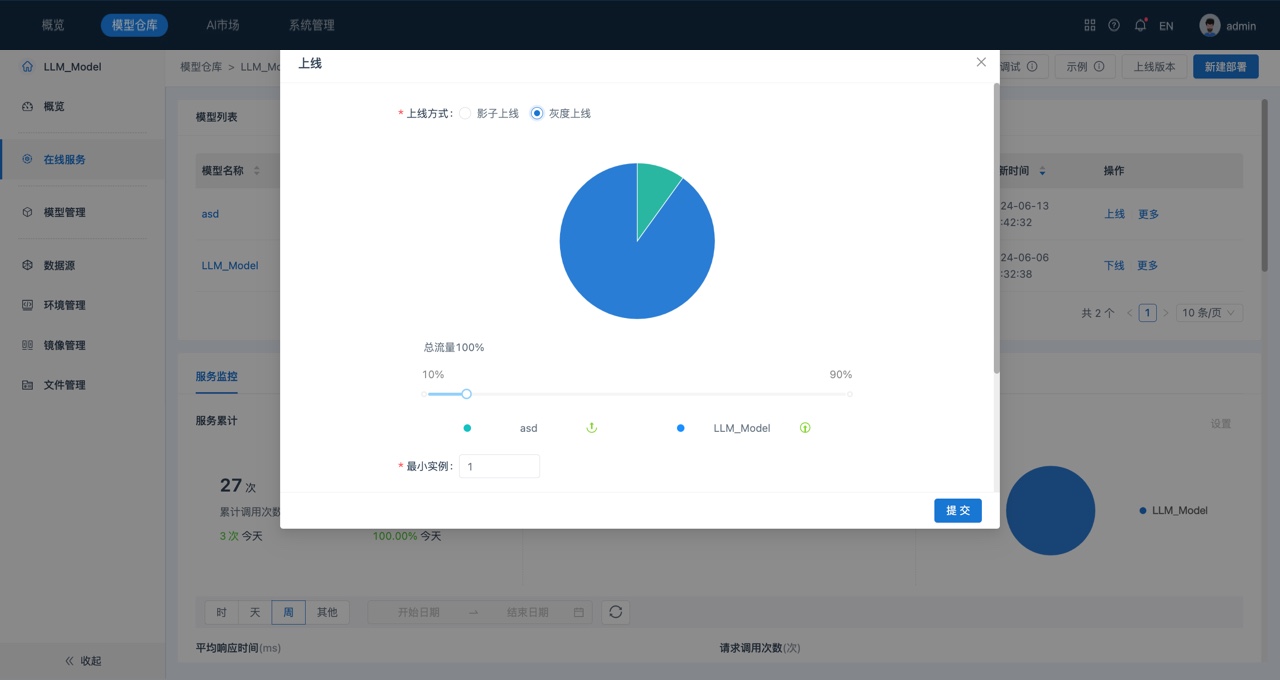
在灰度上线时,可以调整“正式上线”模型与“灰度上线”模型之间的流量比例,进行灰度上线模型的实例配置.
7. 单击提交,完成灰度上线操作。
上线后,“模型列表”中模型的状态会变更为“灰度上线”。
后续操作
- 已上线的模型可以执行下线操作。在“模型列表”中,单击模型所在行的“下线”,可以将模型下线,下线后的模型处于“已部署”状态。
- 如果服务中包括一个“正式上线”和一个“灰度上线”模型,则当将“正式上线”的模型下线后,原处于“灰度上线”状态的模型会自动变为“正式上线”状态。
- 如果服务中包括一个“正式上线”和一个“影子上线”模型,则当“正式上线”的模型下线时,“影子上线”的模型随“正式上线”的模型一起下线。
该页面主要包括如下几部分:
1) 模型列表:包括所有部署、正式上线、灰度上线、影子上线、取消部署状态的模型。
2) 服务监控:展示服务累计调用次数、累计调用成功率、平均/最小/最大响应时间、流量状态、上线模型的平均响应时间以及请求调用次数,CPU、GPU、内存等工作负载的实时使用情况,以及资源明细。