使用Distributed Training Tools在弹性容器集群中进行微调
在大模型专题中用PyTorch在弹性容器集群中进行微调,我们已经实践了如何在弹性容器集群中进行微调,但是这样的方式有个缺点:无法在任务结束时,自动关闭pod,导致一直在消耗DCU。
本示例给出一个基于K8s基础的Job资源,在弹性容器集群中运行分布式微调任务。
方案概述
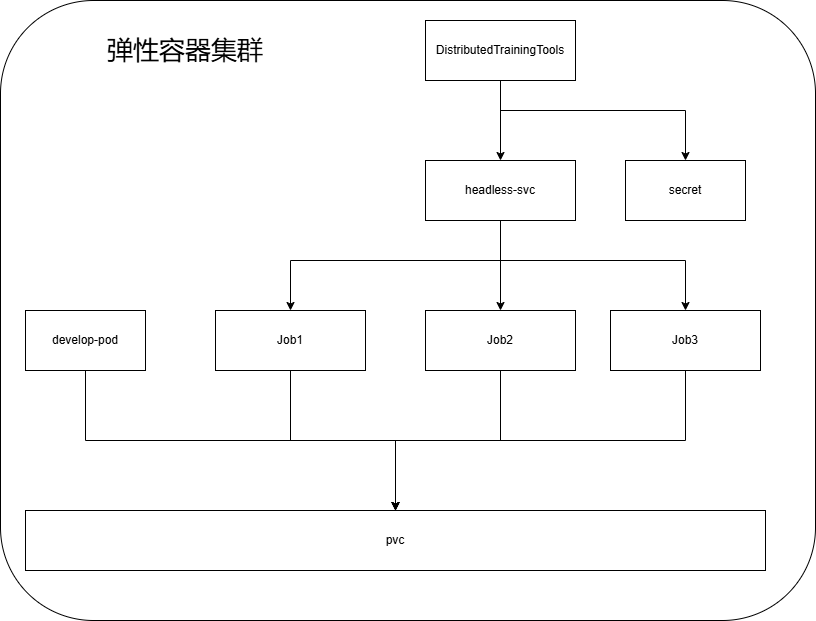
该方案基于K8s的基础资源Job,通过Job来启动多个pod作为一个集群,并在该集群上运行分布式计算任务。当任务完成后,会自动释放这些pod资源。
使用Job的优点:
- 自动化:Job专门用于运行一次性任务,这些任务在完成后通常不需要持续运行。
- 弹性:用户可以指定并行运行的Pod数量,以满足不同任务的需求。
当然,使用Job的时候,集群启动后将开启分布式计算任务,因此需要注意以下几点:
- 启动分布式训练任务之前,需要将数据准备完备,包括数据、代码、环境等。
- 计算任务需要的资源(如GPU、CPU等)需要预留足够的资源,否则可能会导致资源不足而任务失败。
- 计算任务的完成后,集群资源会自动释放,因此计算任务的输出结果需要保存到外部存储,以便后续使用。
因此,本方案中采用PVC(Persistent Volume Claim)来共享计算的代码、数据等,并保存计算任务的输出结果。
另外,通过VS Code,可以同时挂载PVC,那么就可以在VS Code中编辑代码、管理数据,并实时查看任务的输出结果。
前置条件
本教程假定您已经具备以下条件:
- 在您的系统上安装了kubectl,具体步骤参考:安装命令行工具(kubectl)。
- 开通了Alaya NeW弹性容器集群,具体步骤参考:开通弹性容器集群
教程源代码
首先下载本教程所需要的源码文件。
清单
本教程包含以下文件,以下是文件的作用说明。
| 文件名 | 说明 |
|---|---|
| Dockerfile | 镜像构建文件:用来构建docker镜像 |
| dev_pod.yaml | 定义Pod资源:启动一个pod用来开发 |
| distributed_training_tools.py | 快速部署脚本 |
| llama_sft | 微调示例代码(文件夹) |
llama_sft微调示例代码包含以下文件,以下是文件的作用说明。
| 文件名 | 说明 |
|---|---|
| ds_config.json | deepspeed配置文件 |
| sft_data.json | 微调数据集 |
| llama_sft.py | Python脚本 |
| llama_sft_ds_job.sh | 使用job资源进行多节点多GPU微调脚本 |
清单文件详细介绍
Dockerfile
基于Pytorch的基础镜像,自定义镜像。
创建conda环境;
安装额外的 Python 包,例如:transformers,torch,peft,jupyterlab;
设置工作目录为/workspace等操作。
# 使用官方 PyTorch 镜像作为基础镜像
FROM pytorch/pytorch:2.3.1-cuda12.1-cudnn8-devel
# 更新包列表并安装系统级软件包
RUN apt-get update && \
apt-get install -y rclone curl vim iputils-ping sudo && \
apt-get clean && rm -rf /var/lib/apt/lists/*
# 设置环境变量,避免在非交互模式下使用 conda 时出现警告
ENV CONDA_AUTO_UPDATE_CONDA=false \
PATH=/opt/conda/envs/py310/bin:$PATH
# 创建一个新的 conda 环境并激活它
RUN conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ && \
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/ && \
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/ && \
conda config --set channel_priority strict && \
conda config --remove channels defaults && \
RUN conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ && \
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/ && \
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/ && \
conda config --set channel_priority strict && \
conda config --remove channels defaults && \
conda create -n py310 python=3.10 -y && \
echo "source activate py310" > ~/.bashrc
# 安装所需的 Python 包和 Jupyter Notebook
RUN conda run -n py310 pip install --no-cache-dir \
transformers==4.41.2 \
deepspeed==0.14.3 \
peft==0.11.1 \
torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu121 \
numpy==1.23.5 \
aim==3.19.1 \
jupyter \
-i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
# 暴露 Jupyter 默认端口
EXPOSE 8888
# 设置工作目录
WORKDIR /workspace
# 启动 Jupyter Notebook 服务
CMD ["conda", "run", "-n", "py310", "jupyter", "notebook", "--ip=0.0.0.0", "--port=8888", "--no-browser", "--allow-root"]
dev_pod
在本示例中,启动了一个pod,专门用来开发使用,您可以使用VS Code连接到这个pod中,进行模型下载,脚本编写,编码等工作。
apiVersion: v1
kind: Pod
metadata:
name: dev-pod
namespace: llama
labels:
app: dev
spec:
restartPolicy: Never
containers:
- name: dev-container
image: registry.hd-01.alayanew.com:8443/vc-huangxs/pytorch:2.3.1-cuda12.1-cudnn8-pyton310-transformers4.41.2-devel # 替换自己镜像
imagePullPolicy: Always
resources:
requests: # Added resource requests
memory: "4Gi"
cpu: "500m"
limits:
memory: "8Gi" # Added memory limit
cpu: "1000m" # Added CPU limit
ports: # 添加端口映射
- containerPort: 80 # 容器内应用的端口
name: http-port
protocol: TCP
command: ["sh", "-c", "tail -f /dev/null"]
volumeMounts:
- name: workspace
mountPath: "/workspace"
subPath: "dtt/workspace"
imagePullSecrets:
- name: harbor-secret
volumes:
- name: workspace
persistentVolumeClaim:
claimName: pvc-capacity-userdata
distributedTrainingTools.py
快速部署脚本。
按照提示说明修改自定义参数(kubeconfig、VKD-ID、pvc_name、work_dir、cmd等),并执行。
脚本会自动创建指定的命名空间,并创建好pvc,secret,service,job等资源,开始分布式训练任务。
快速开始
镜像准备
用户名密码:查看开通镜像仓库时的通知短信
镜像仓库访问地址:参考镜像仓库的使用
镜像仓库访问地址:由 访问域名/项目 组成
使用文件清单中的Dockerfile自定义镜像,这里您可根据自己的实际情况来自定义自己的镜像。
# pull image
docker pull pytorch/pytorch:2.3.1-cuda12.1-cudnn8-devel
# build image
docker build -t pytorch:2.3.1-cuda12.1-cudnn8-pyton310-transformers4.41.2-devel -f [/path/to/Dockerfile] .
#login
docker login 镜像仓库访问域名/ -u [user] -p [passwd]
# tag
docker tag \
pytorch:2.3.1-cuda12.1-cudnn8-pyton310-transformers4.41.2-devel \
[镜像仓库访问地址]/pytorch:2.3.1-cuda12.1-cudnn8-pyton310-transformers4.41.2-devel
# push
docker push [镜像仓库访问地址]/pytorch:2.3.1-cuda12.1-cudnn8-pyton310-transformers4.41.2-devel
创建k8s基础资源
# 声明弹性容器集群配置
export KUBECONFIG="[/path/to/kubeconfig]"
# 创建namespace
kubectl create namespace llama
# 创建secret
kubectl create secret docker-registry harbor-secret \
--docker-server=镜像仓库访问域名\
--docker-username="user" \
--docker-password="password" \
--docker-email="email" \
--namespace llama
在dev-pod中做开发准备
我们可以在dev-pod中进行模型下载,脚本开发等前期准备工作。
创建dev-pod
kubectl create -f dev_pod.yaml

进入pod中的工作目录
kubectl exec -it pod/dev-pod bash -n llama

下载模型
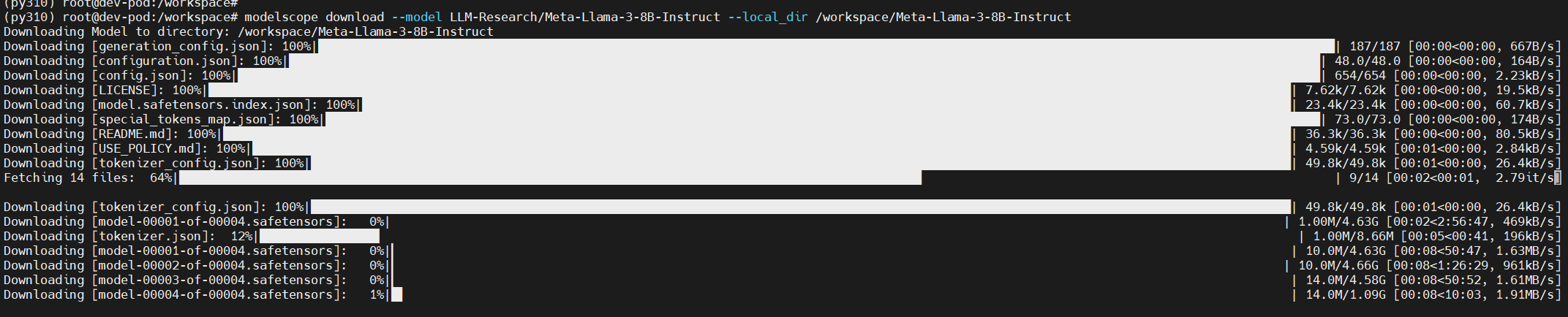
将模型下载到持久化目录,之后就不用再次下载了。
本教程中挂载的持久化目录为“/workspace”。
这里我们将模型下载到以下目录“/workspace/Meta-Llama-3-8B-Instruct”。
pip install modelscope
modelscope download --model LLM-Research/Meta-Llama-3-8B-Instruct --local_dir /workspace/Meta-Llama-3-8B-Instruct
脚本准备
本教程中,我们已经预置了脚本。将配置文件从预置脚本中拉取下来。
- 运行如下命令获取压缩包文件,然后解压文件。
wget https://docs.alayanew.com/assets/files/demo-9b5e4699933a23e1ef274f94b4b4fa53.zip
- 解压后将
llama_sft文件夹拷贝至/workspace路径下。
一键启动训练任务
python distributed_training_tools.py --namespace="<your_namespace>" \
--kubeconfig="</path/to/kubeconfig>" \
--vks_id="<your_vks_id>" \
--pvc_name="<your_pvc_name>" \
--work_dir="</path/to/workdir>" \
--cmd="<The script you want to execute in the pod>" \
--labels="<distributed-training>" \
--image="<The image >" \
--harbor_secret="<harbor-secret>" \
--service_name="<distributed-training-svc>" \
--docker_server="registry.hd-01.alayanew.com:8443" \
--docker_username="<your_harbor_username>" \
--docker_password="<your_harbor_password>" \
--email="<your_email>" \
--gpu_type="<nvidia.com/gpu-h800>" \
--gpu_count="<2>" \
--nnodes="<2>" \
--nproc_per_node="<2>"
注意:请替换以上参数为你自己的实际参数
请确保您的pvc改在目录与镜像的工作目录能够匹配,执行脚本存在,并且有相应的执行权限。
查看启动的pod信息
kubectl get all -n llama

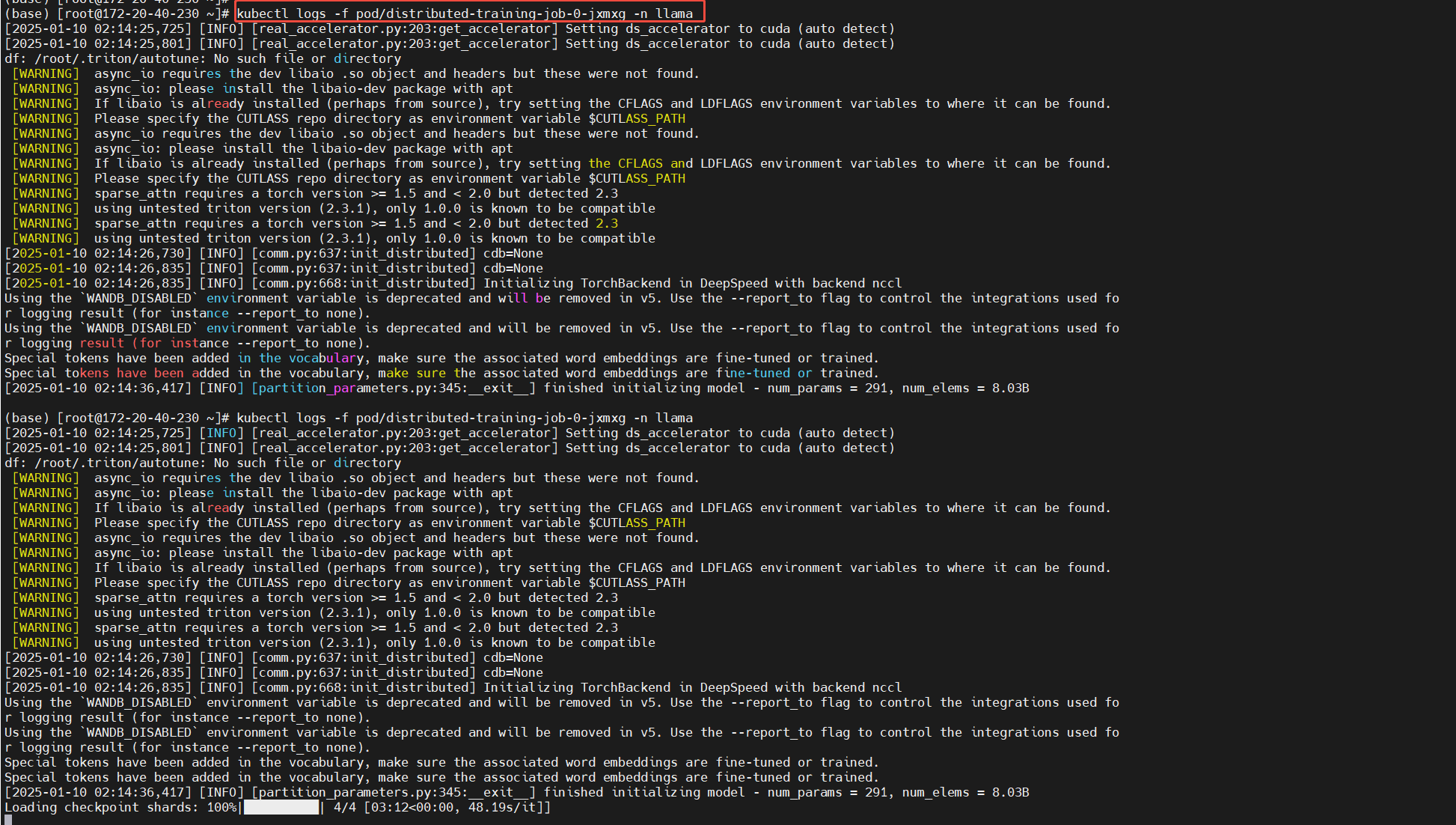
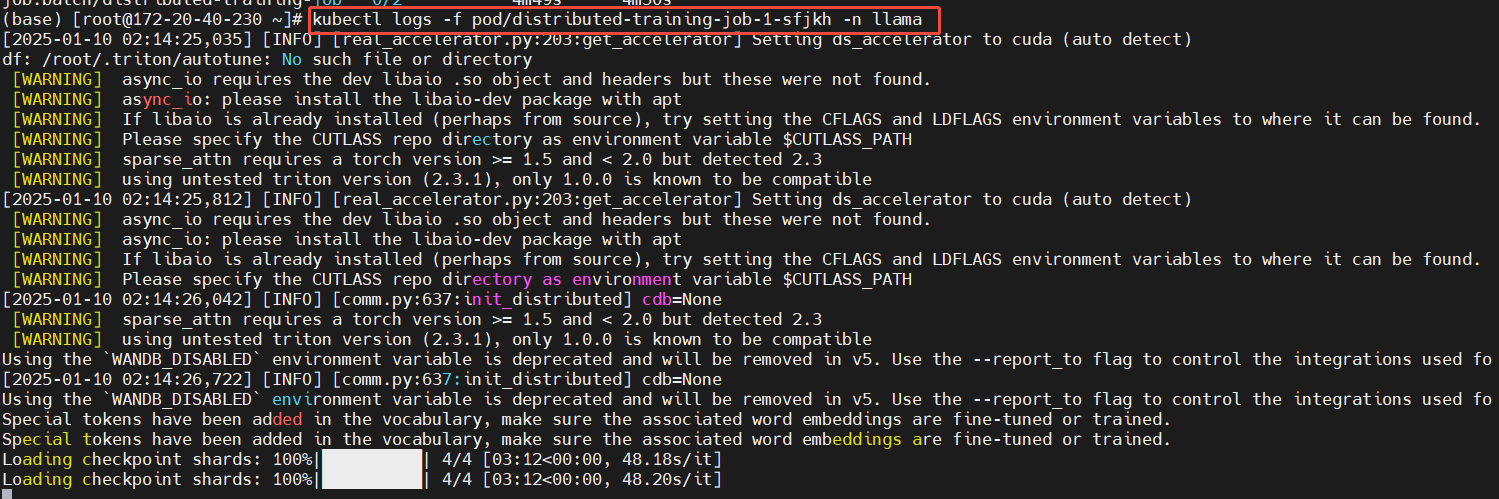
查看日志
主节点
从节点
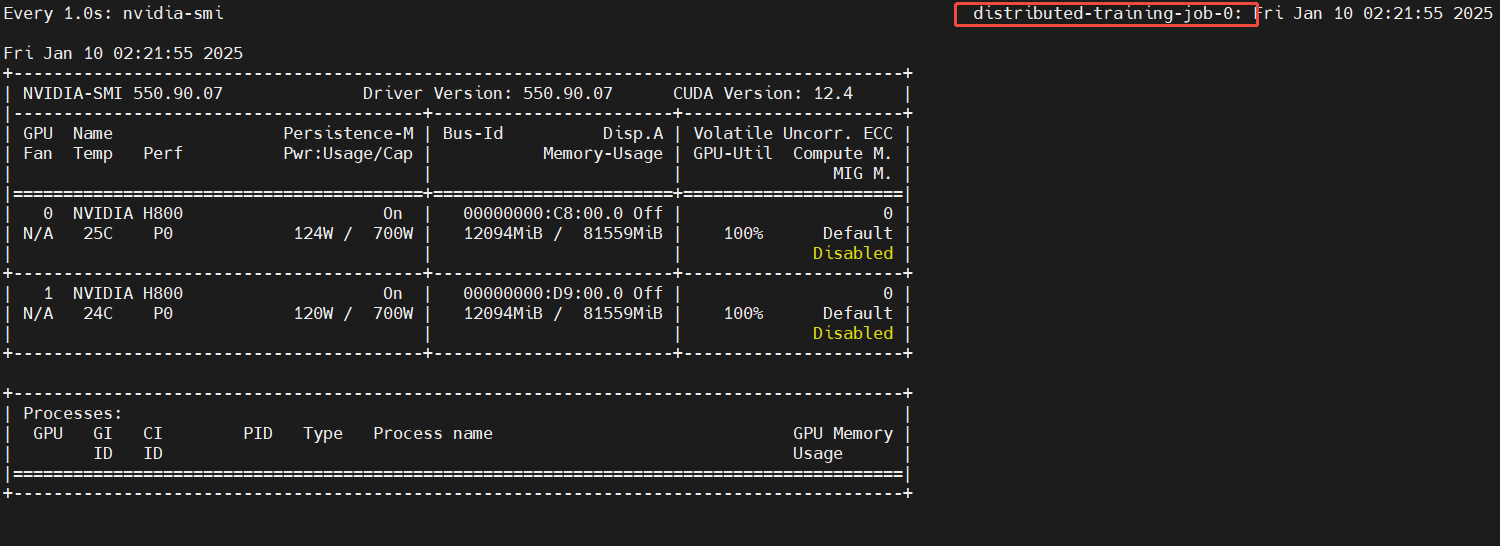
监控GPU使用情况
主节点
kubectl exec -it pod/distributed-training-job-0-lmsgr bash -n llama
watch -n 1 nvidia-smi
从节点
kubectl exec -it pod/distributed-training-job-0-lmsgr bash -n llama
watch -n 1 nvidia-smi
