使用PyTorch在弹性容器集群中进行微调
PyTorch 是一个开源的机器学习库,在学术界和工业界都得到了广泛的应用,尤其是在自然语言处理(NLP)、计算机视觉(CV)、强化学习等领域。经常与 Jupyter Notebook 结合使用。
在这个简单的例子中,我们将带你使用 PyTorch 弹性容器集群进行模型微调。
前置条件
本教程假定您已经具备以下条件:
- 在您的系统上安装了kubectl。
- 开通了Alaya NeW弹性容器集群,具体步骤参考:开通弹性容器集群。
请确认 弹性容器集群 和后面使用的 镜像仓库 是在同一个智算中心开通的。
教程源代码
首先下载本教程所需要的源码文件。
清单
本教程包含以下文件,以下是文件的作用说明。
| 文件名 | 说明 |
|---|---|
| Dockerfile | 镜像构建文件:用来构建docker镜像 |
| deployment-1node-1gpu.yaml | 定义Deployment资源:定义单节点、单GPU情况下,如何启停pod |
| deployment-1node-2gpu.yaml | 定义Deployment资源:定义单节点、多GPU情况下,如何启停pod |
| deployment-2node-2gpu.yaml | 定义Deployment资源:定义多节点、多GPU情况下,如何启停pod |
| llama_sft | 微调示例代码(文件夹) |
llama_sft微调示例代码包含以下文件,以下是文件的作用说明。
| 文件名 | 说明 |
|---|---|
| ds_config.json | deepspeed配置文件 |
| sft_data.json | 微调数据集 |
| llama_sft.py | Python脚本 |
| llama_sft_1node_1gpu.sh | 单节点单GPU微调脚本 |
| llama_sft_1node_2gpu.sh | 单节点多GPU微调脚本 |
| llama_sft_2node_2gpu_ds.sh | 多节点多GPU微调脚本(master) |
| llama_sft_2node_2gpu_ds2.sh | 多节点多GPU微调脚本 |
Dockerfile
基于Pytorch的基础镜像,自定义镜像:安装额外的 Python 包,例如:transformers,torch,peft,jupyterlab;设置工作目录为/workspace等操作。
部署
在本示例中,部署信息由"deployment-1node-1gpu.yaml"、"deployment-1node-2gpu.yaml"、"deployment-2node-2gpu.yaml"三个文件指定,分别对应了单节点单GPU、单节点多GPU、多节点多GPU情况下,如何启停pod。
apiVersion: apps/v1
kind: Deployment
metadata:
name: llama-deploy-1node-1gpu
namespace: llama
spec:
replicas: 1
selector:
matchLabels:
app: llama
template:
metadata:
labels:
app: llama
spec:
restartPolicy: Always
containers:
- name: coding-dev-container
image: registry.hd-01.alayanew.com:8443/vc-huangxs/pytorch:2.3.1-cuda12.1-cudnn8-pyton310-transformers4.41.2-devel
resources:
requests:
memory: "200Gi"
cpu: "64"
nvidia.com/gpu-h800: 1
rdma/rdma_shared_device_a: 1
rdma/rdma_shared_device_b: 1
limits:
memory: "200Gi"
cpu: "64"
nvidia.com/gpu-h800: 1
rdma/rdma_shared_device_a: 1
rdma/rdma_shared_device_b: 1
command: ["sh", "-c", "tail -f /dev/null"]
volumeMounts:
- name: workspace
mountPath: "/workspace"
subPath: "pytorch/workspace"
env:
- name: NCCL_IB_DISABLE
value: "0"
- name: NCCL_SOCKET_IFNAME
value: "eth0"
- name: NCCL_IB_HCA
value: "ib7s"
imagePullSecrets:
- name: harbor-secret
volumes:
- name: workspace
persistentVolumeClaim:
claimName: pvc-capacity-userdata
具体指示弹性容器集群的Kubernetes control plane以下信息:
- 确保在任何时候只有一个Pod运行。这个实例是通过清单中的 spec.replicas 键值对定义的。
- 在运行pod的弹性容器集群计算节点上预留GPU、CPU和内存资源。在Kubernetes Pod中运行的每个pod实例分配了1个gpu,由下面的spec.template.spec.containers.resources.limits.nvidia.com/gpu-h800 键值对定义。
- 指定镜像,由 spec.template.spec.containers.image 键值对定义。
- 指定pvc的挂载目录,由 spec.template.spec.containers.volumeMounts 键值对定义。
- 指定pvc,由 spec.template.spec.volumes 定义。
编写jupyter_deploy.yaml文件时,请将以下信息替换成你自己的:
| 变量名 | 说明 | 来源 | 示例 |
|---|---|---|---|
| image | 镜像名称 | 自定义镜像 | registry.hd-01.alayanew.com:8443/[user]/pytorch:2.3.1-cuda12.1-cudnn8-devel |
| resources.requests.[GPU] | GPU资源信息 | 弹性容器集群 | nvidia.com/gpu-h800 |
操作步骤
镜像准备
请确认 镜像仓库 和 弹性容器集群 是在同一个智算中心开通的。
以下命令中,请将Dockerfile文件路径,Harbor账号/密码,镜像名称,镜像仓库地址等信息替换成你自己的。
用户名/密码:查看开通镜像仓库时的通知短信
镜像仓库域名:参考镜像仓库的使用
镜像仓库地址 :由 镜像仓库域名/项目 组成
# pull image
docker pull pytorch/pytorch:2.3.1-cuda12.1-cudnn8-devel
# build image
docker build -t pytorch:2.3.1-cuda12.1-cudnn8-pyton310-transformers4.41.2-devel -f Dockerfile文件路径 .
#login
docker login 镜像仓库域名 -u 用户名 -p 密码
# tag
docker tag \
pytorch:2.3.1-cuda12.1-cudnn8-pyton310-transformers4.41.2-devel \
镜像仓库地址/pytorch:2.3.1-cuda12.1-cudnn8-pyton310-transformers4.41.2-devel
# push
docker push 镜像仓库地址/pytorch:2.3.1-cuda12.1-cudnn8-pyton310-transformers4.41.2-devel
创建k8s基础资源
以下命令中,请将账号,密码,镜像名称,镜像仓库地址等信息替换成你自己的。
# 声明弹性容器集群配置
export KUBECONFIG="[/path/to/kubeconfig]"
# 创建namespace
kubectl create namespace llama
# 创建secret
kubectl create secret docker-registry harbor-secret \
--docker-server=registry.hd-01.alayanew.com:8443\
--docker-username="user" \
--docker-password="password" \
--docker-email="email" \
--namespace llama
单节点单GPU微调
创建部署
kubectl create -f deployment-1node-1gpu.yaml
kubectl get all -n llama

脚本准备
在宿主机执行以下命令,将微调脚本拷贝到持久化目录,本教程的模型目录为“/workspace/llama_sft”。
kubectl cp [/path/to/llama_sft] pod/llama-deploy-1node-1gpu-6d77656b9f-bxfbc:/workspace/llama_sft
进入pod中的工作目录
替换pod名称为你实际启动pod的名称。
kubectl exec -it pod/llama-deploy-1node-1gpu-6d77656b9f-bxfbc bash -n llama
cd llama_sft
ls -l
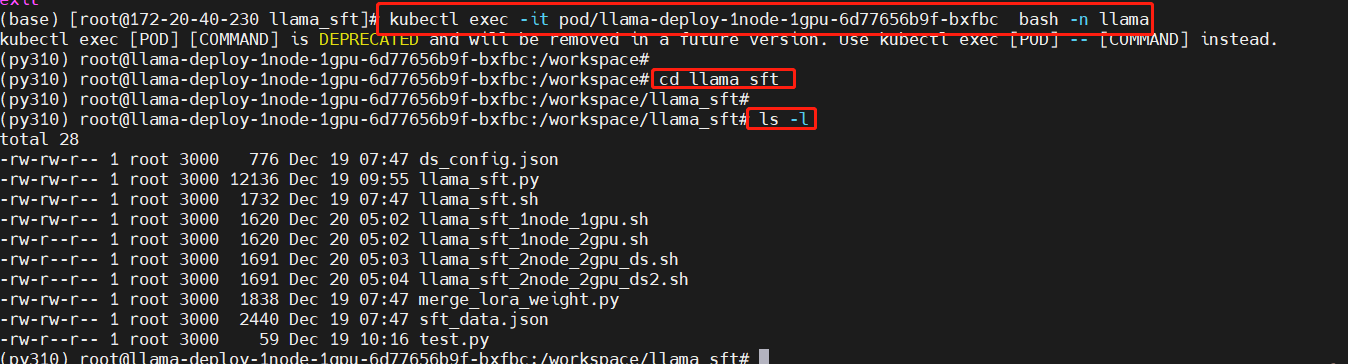
下载模型
将模型下载到持久化目录,之后就不用再次下载了,本教程的模型目录为“/workspace/Meta-Llama-3-8B-Instruct”
pip install modelscope
modelscope download --model LLM-Research/Meta-Llama-3-8B-Instruct --local_dir /workspace/Meta-Llama-3-8B-Instruct
执行单节点单GPU微调脚本
bash llama_sft_1node_1gpu.sh
开始训练
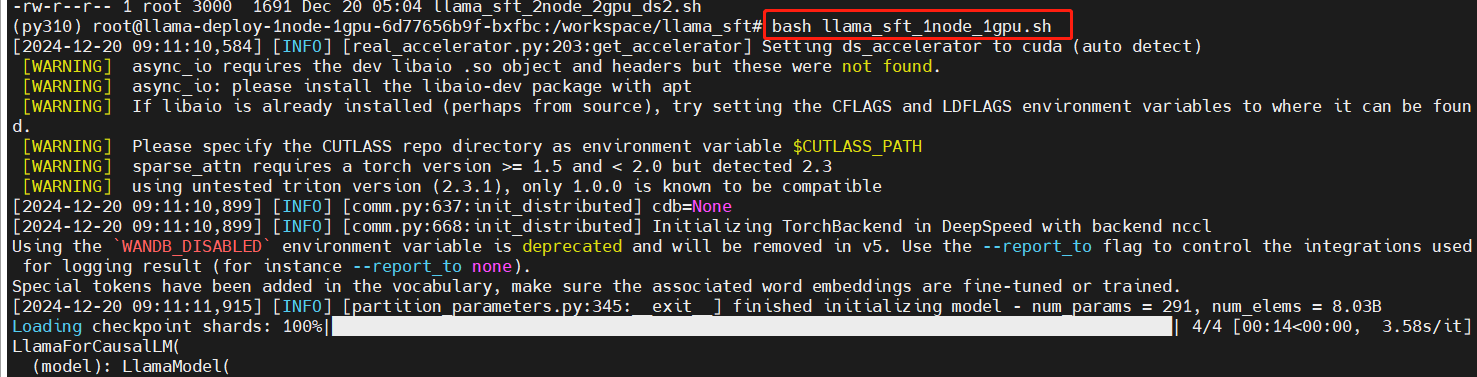
训练中

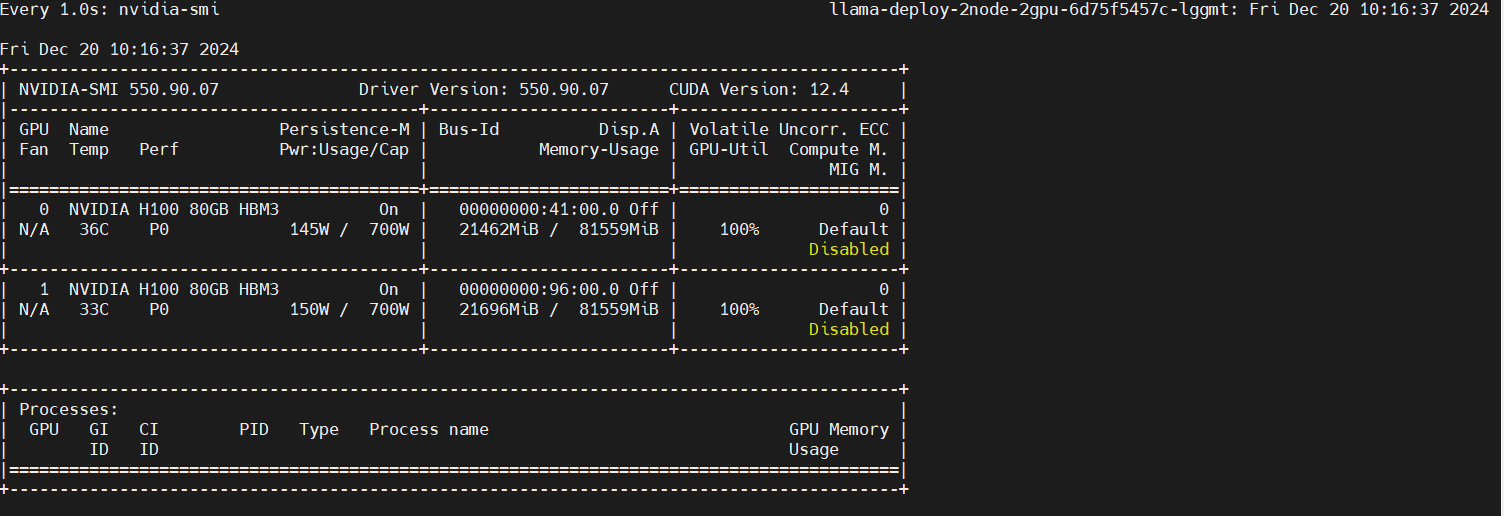
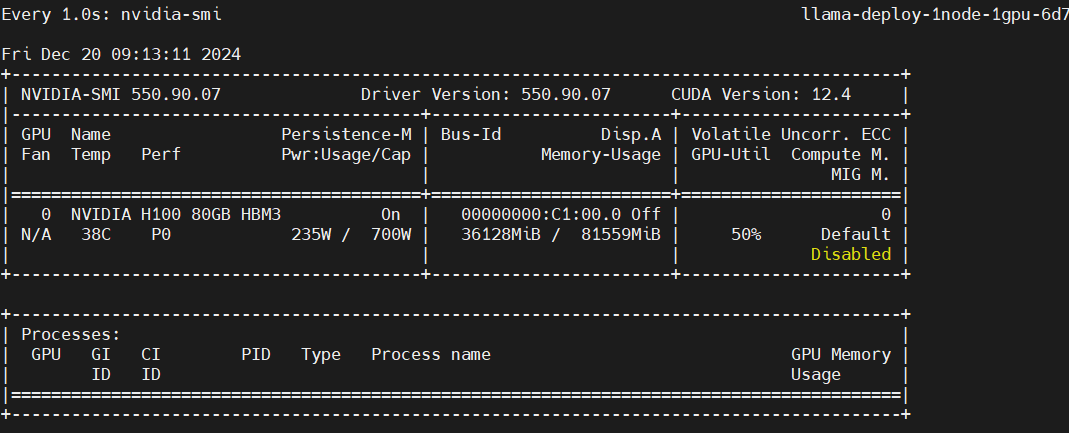
监控GPU使用情况
在另一个终端进入pod,执行以下命令。
watch -n 1 nvidia-smi
单节点多GPU微调
创建部署
kubectl create -f deployment-1node-2gpu.yaml
kubectl get all -n llama
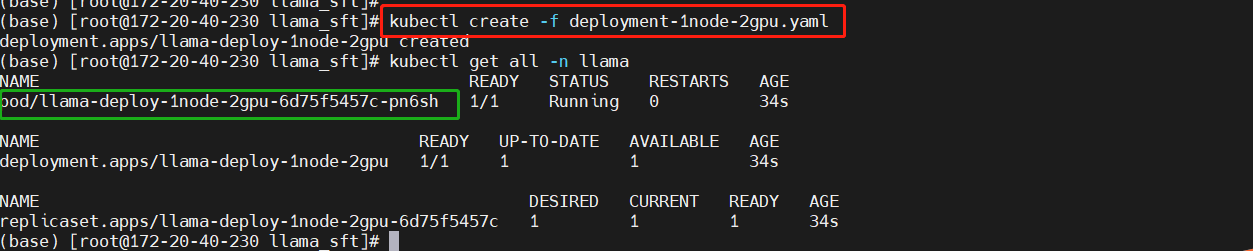
进入pod中的工作目录
替换pod名称为你实际启动pod的名称。
# pod-1
kubectl exec -it pod/llama-deploy-1node-2gpu-6d75f5457c-pn6sh bash -n llama
cd llama_sft
ls -l
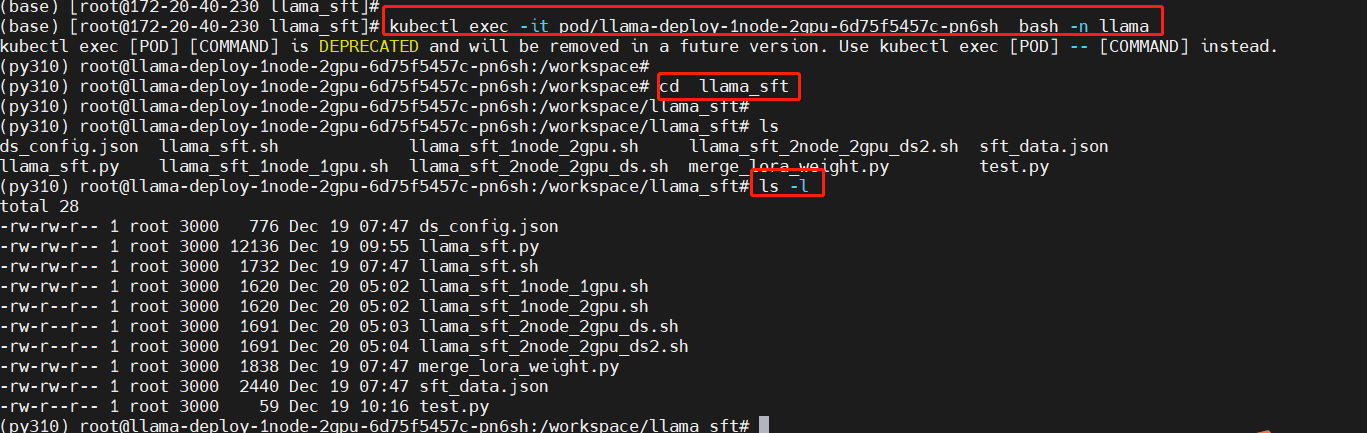
执行单节点多GPU微调脚本
bash llama_sft_1node_2gpu.sh
开始训练
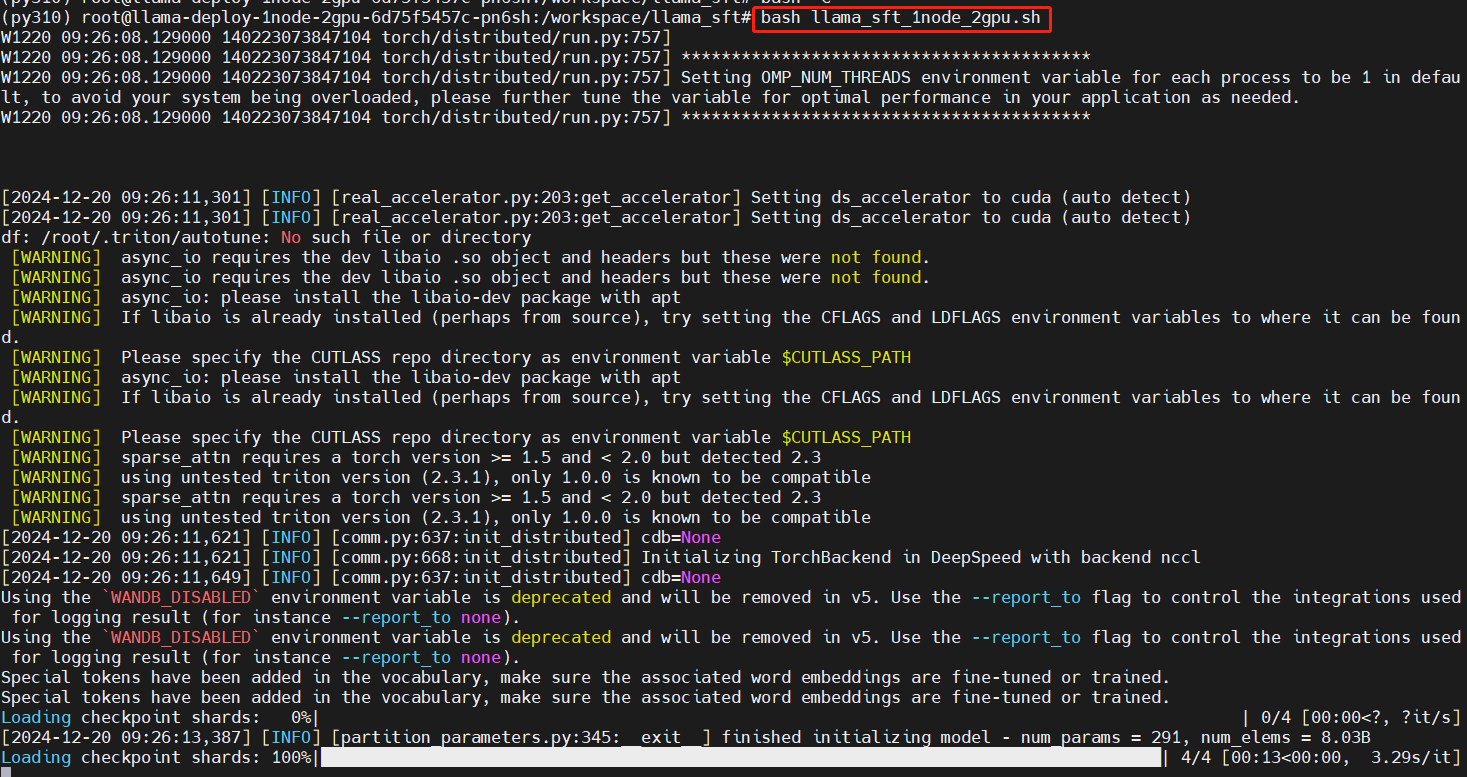
训练中

监控GPU使用情况
在另一个终端进入pod,执行以下命令。
kubectl exec -it pod/llama-deploy-1node-2gpu-6d75f5457c-pn6sh bash -n llama
watch -n 1 nvidia-smi
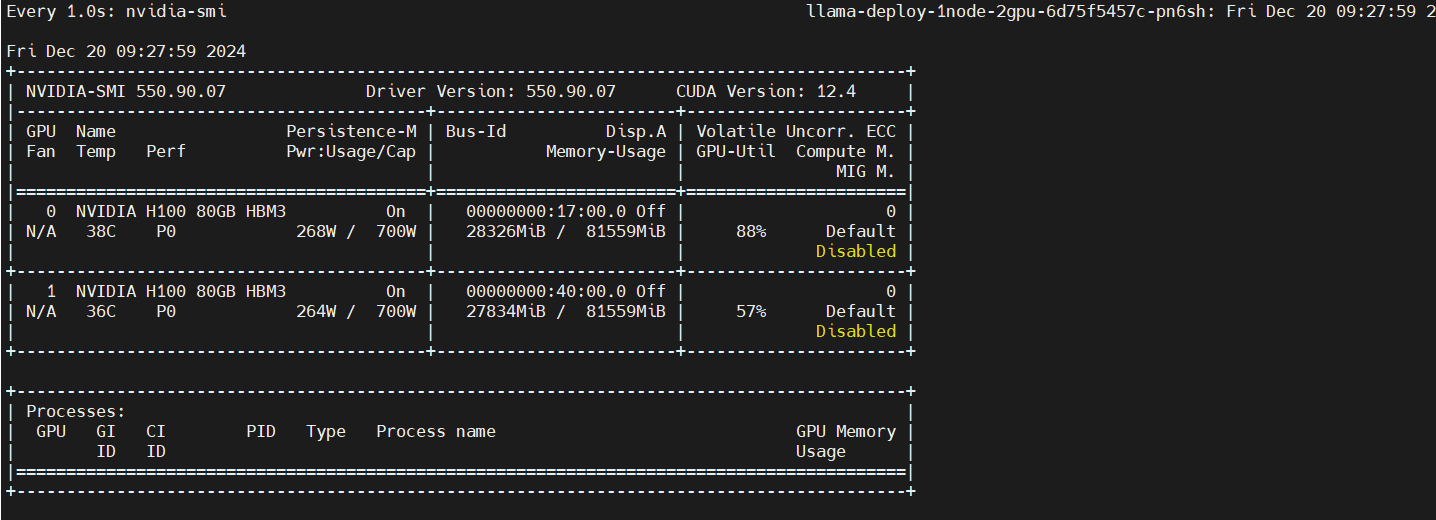
多节点多GPU微调
创建部署
kubectl create -f deployment-2node-2gpu.yaml
kubectl get all -n llama -o wide
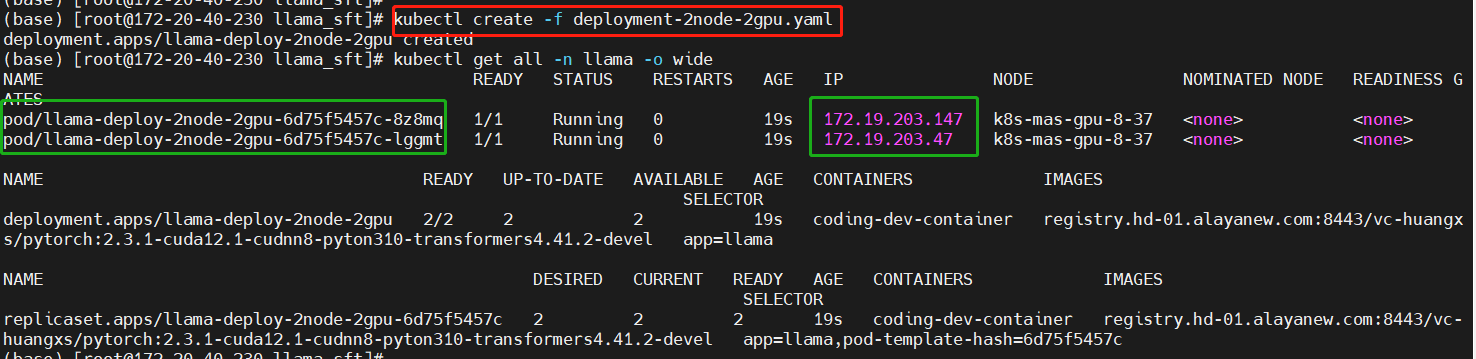
进入主节点中的工作目录
选择一个pod作为你的主节点,进入pod中进行配置。本示例选择IP为“172.29.203.147”的pod作为主节点。
替换pod名称为你实际启动pod的名称。
# pod-1
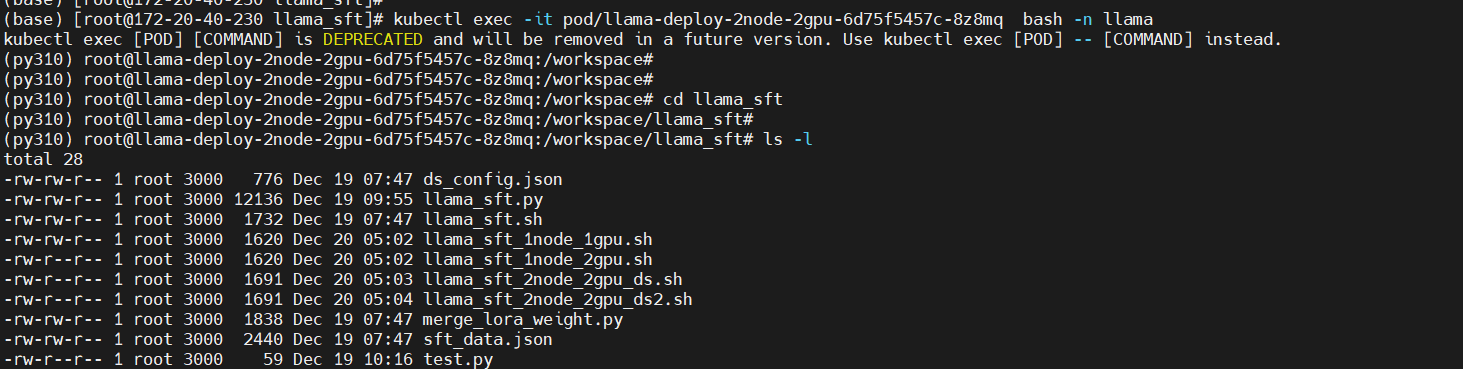
kubectl exec -it pod/llama-deploy-2node-2gpu-6d75f5457c-8z8mq bash -n llama
cd llama_sft
ls -l
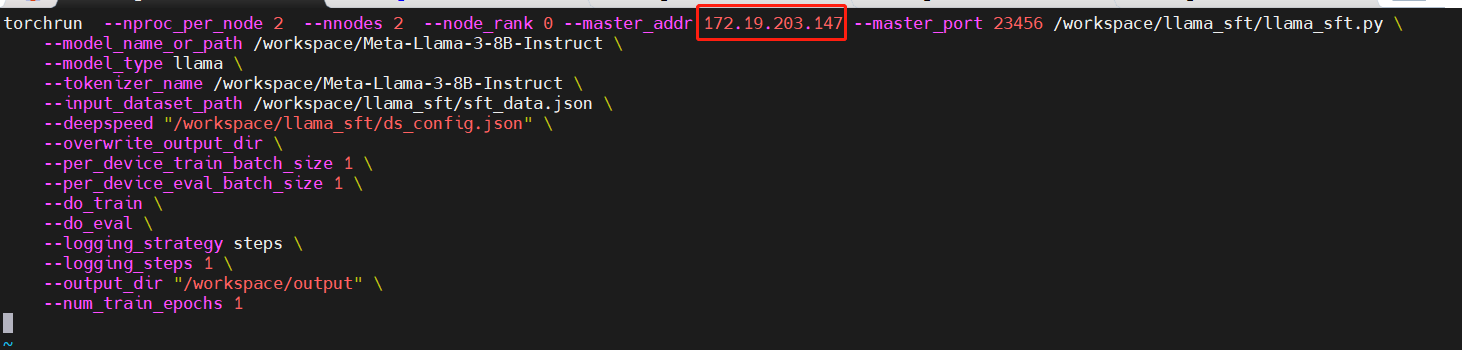
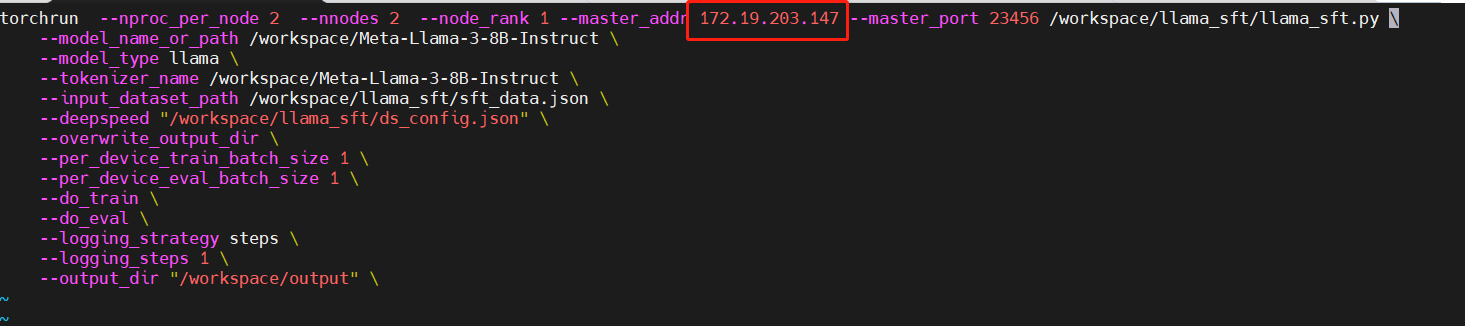
修改多节点多GPU微调脚本
分别修改“llama_sft_2node_2gpu_ds.sh”,“llama_sft_2node_2gpu_ds2.sh”脚本中的"master_addr" 参数值,如下图所示:
llama_sft_2node_2gpu_ds.sh文件
llama_sft_2node_2gpu_ds2.sh文件
主节点执行多节点多GPU微调脚本
bash llama_sft_2node_2gpu_ds.sh
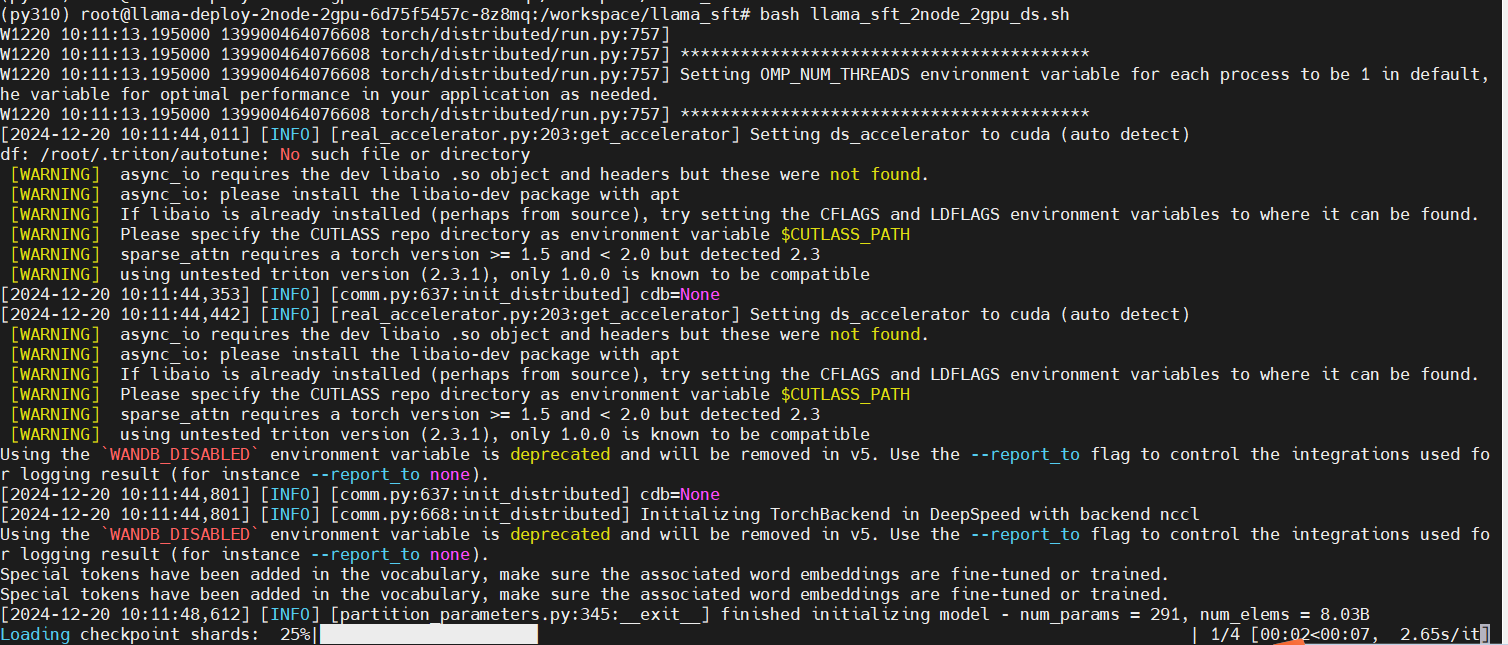
从节点执行多节点多GPU微调脚本
# 另外起一个终端
kubectl exec -it pod/llama-deploy-85678bfb74-sbdxc bash -n llam
cd llama_sft
bash llama_sft_2node_2gpu_ds2.sh
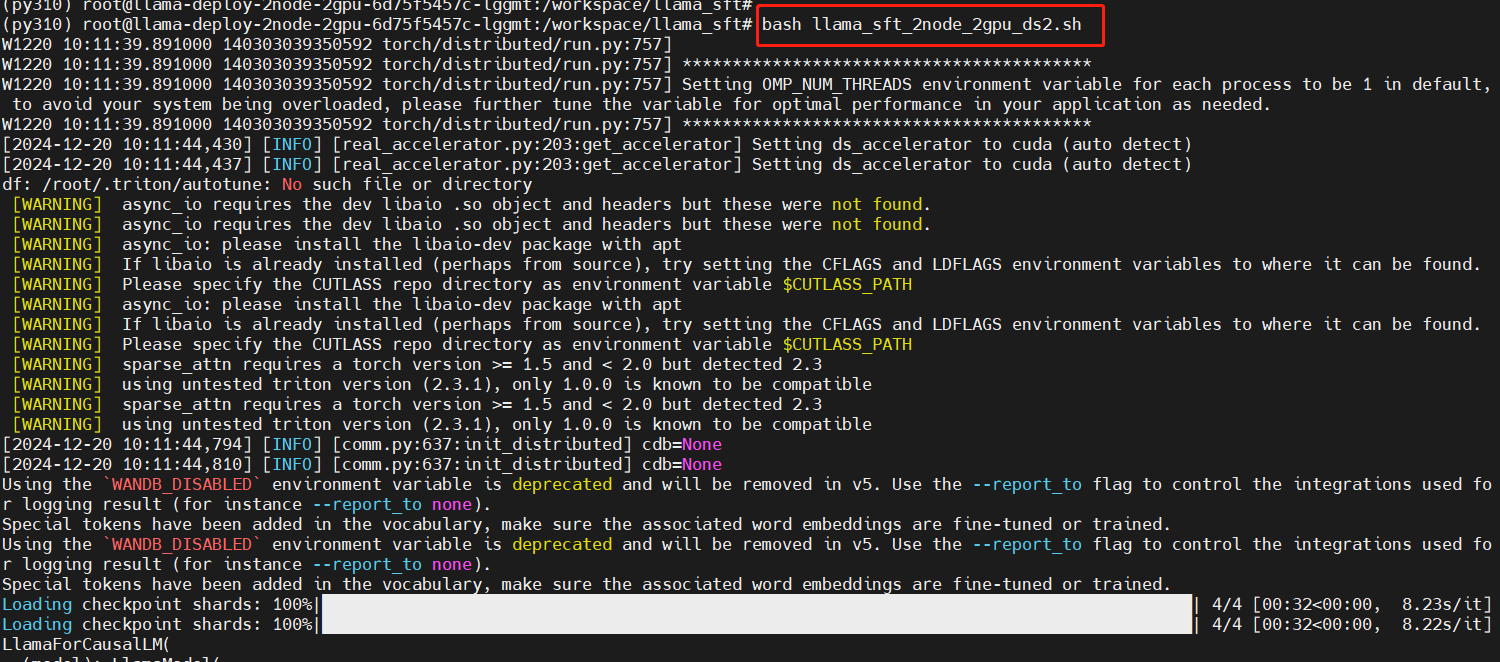
训练中

监控GPU使用情况
在另外两个终端分别进入主节点和从节点,执行以下命令,查看GPU使用情况。
主节点
kubectl exec -it pod/llama-deploy-2node-2gpu-6d75f5457c-8z8mq bash -n llama
watch -n 1 nvidia-smi
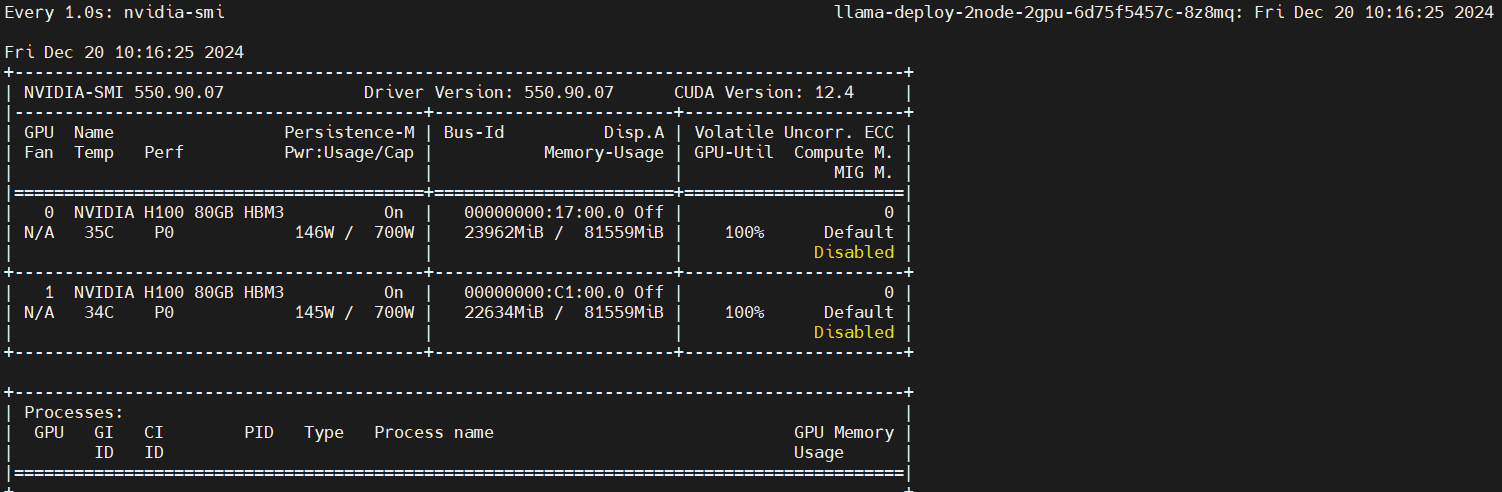
从节点
kubectl exec -it pod/llama-deploy-1node-2gpu-6d75f5457c-pn6sh bash -n llama
watch -n 1 nvidia-smi