基于Aladdin的GPU源代码编译指南
概述
Alaya NeW提供了VS Code插件Aladdin。Aladdin可以让用户在创建workshop,workshop将在Alaya NeW中启动一个pod供远程开发。为了节约资源,启动的pod没有GPU资源。 当需要使用GPU资源时,比如运行shell脚本或者Python代码,Aladdin将另外启动一个pod,并将GPU资源分配给该pod。 在开发中,用户可以使用Aladdin插件将代码编译成可执行文件,并在Alaya NeW中运行。本文档将介绍如何使用Aladdin插件编译GPU源代码。 本文档以编译vllm项目为例,介绍如何使用Aladdin插件编译GPU源代码。
准备工作
本教程假定您已经具备以下条件:
- Docker环境安装请参考: 安装Docker
- 在您的系统上安装了kubectl,具体步骤参考安装命令行工具(kubectl)。
- 开通了Alaya NeW弹性容器集群,具体步骤参考开通弹性容器集群
请参考使用Aladdin
vllm源代码下载:https://github.com/vllm-project/vllm
步骤
Workshop创建以及准备
- 参考创建workshop创建Workshop。创建Workshop的配置:
- 选择4CPU
- 镜像选择使用指南-弹性容器集群-Aladdin-build镜像中构建的镜像。
- PVC挂载:pvc-capacity-userdata, subPath: app/vllm, 挂载路径:/workspace。
- 参考使用指南-弹性容器集群-Aladdin-环境准备
- 切记按照步骤7,8设置TMP和TMPDIR环境变量,否则可能导致编译失败。
- 将下载的vllm项目上传到Workshop的/workspace目录下。并初始化conda环境py311。
使用GPU编译代码
- 编写编译脚本,比如build.sh,内容如下:
#!/bin/bash
# 切换到py311环境
conda init
source ~/.bashrc
conda activate py311
apt-get update && apt-get install procps kmod python3-dev -y
export MAX_JOBS=6
# 配置github加速
git config --global url."https://gh-proxy.com/".insteadOf https://
VLLM_CUDA_VERSION=12.3 pip install . -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple > /workspace/build.log
- build.sh脚本上执行Run shell,参考使用指南-弹性容器集群-Aladdin-Run shell,其配置如下:
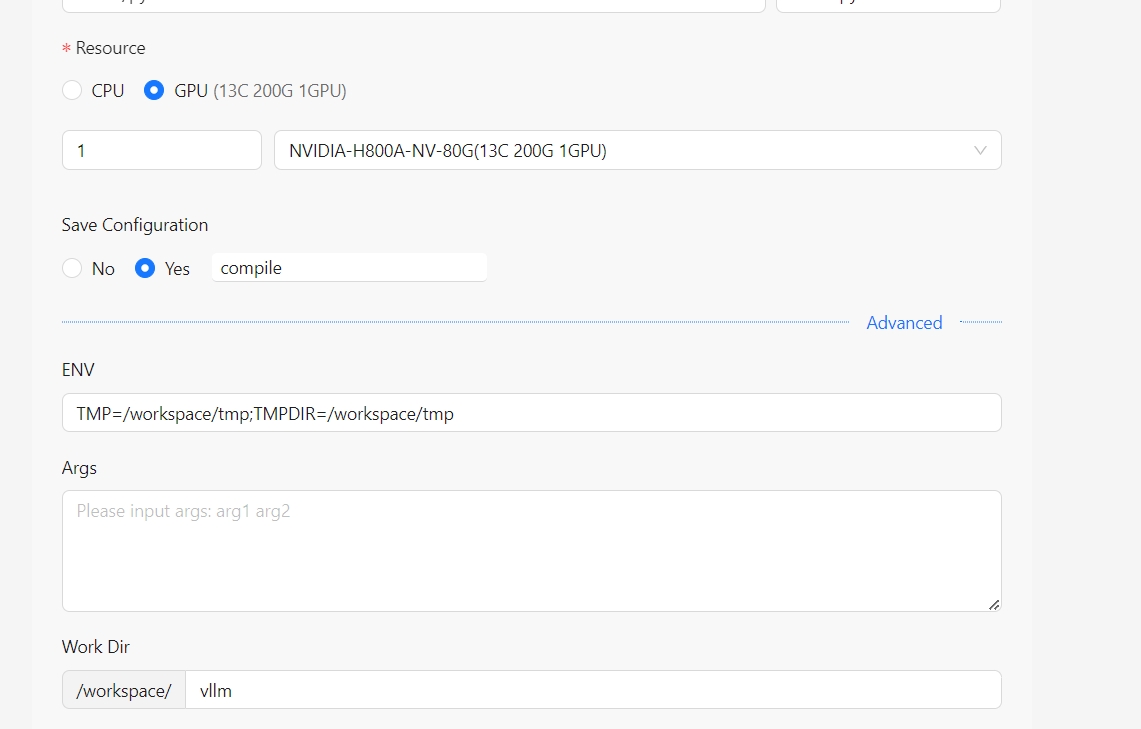
如果编译过程中出现错误,在排除错误后并重新运行build.sh脚本前,请先删除文件/workspace/vllm/build/temp.linux-x86_64-cpython-311/CMakeCache.txt,否则重新编译会失败。
- 编译日志将会输出到/workspace/build.log,可以查看编译日志。编译过程可能需要几个小时,请耐心等待。完成后,将在log中看到类似以下的输出:
.................
Building wheel for vllm (pyproject.toml): still running...
Building wheel for vllm (pyproject.toml): still running...
Building wheel for vllm (pyproject.toml): finished with status 'done'
Created wheel for vllm: filename=vllm-0.8.2.dev21+g742369d3.d20250326.cu123-cp311-cp311-linux_x86_64.whl size=675127774 sha256=5f1b6ebdde24d373d3d04589126848ce89f7547a0f507f7f636fb531ceb76394
Stored in directory: /workspace/tmp/pip-ephem-wheel-cache-udwmxv2n/wheels/42/b6/77/343ae7a1bcbcb79abb28c70a6ea0c4842c11ef5d69bbec0e59
Successfully built vllm
Installing collected packages: triton, sentencepiece, py-cpuinfo, nvidia-cusparselt-cu12, mpmath, ....
Attempting uninstall: numpy
Found existing installation: numpy 2.0.1
Uninstalling numpy-2.0.1:
Successfully uninstalled numpy-2.0.1
Successfully installed MarkupSafe-3.0.2 aiohappyeyeballs-2.6.1 aiohttp-3.11.14 aiosignal-1.3.2 ...
- 检查vllm安装结果。 在当前workshop中打开terminal,输入:
# 切换到py311环境
conda activate py311
pip show vllm
可以看到类似如下输出:
Name: vllm
Version: 0.8.2.dev21+g742369d3.d20250326.cu123
Summary: A high-throughput and memory-efficient inference and serving engine for LLMs
Home-page: https://github.com/vllm-project/vllm
Author: vLLM Team
...
虽然我们在一个新启动的session中编译vllm(为了编译Cuda版本的vllm),因为都在py311环境下,所以我们可以直接使用pip show命令查看vllm的版本信息。 当我们需要在一个新的session中使用vllm时,只需要激活py311环境,就可以直接使用vllm包了。 下面的步骤我们将使用vllm包来提供模型推理服务的demo。
使用vllm启动模型推理服务
本次演示使用模型为DeepSeek-R1-Distill-Llama-8B。
我们使用以下脚本启动一个session来部署vllm模型推理服务。
#!/bin/bash
# 创建模型存储目录
cd /workspace
mkdir models
# 初始化conda环境并切换到py311环境
conda init
source ~/.bashrc
conda activate py311
# 配置模型下载加速
export HF_ENDPOINT=http://hfmirror.mas.zetyun.cn:8082
export HF_HUB_DOWNLOAD_TIMEOUT=120
export HF_HUB_ETAG_TIMEOUT=1800
# 下载模型
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Llama-8B \
--max-workers 8 \
--local-dir /workspace/models/deepseek-ai/DeepSeek-R1-Distill-Llama-8B
# 启动vllm模型推理服务并将日志输出到/workspace/serve.log
CUDA_VISIBLE_DEVICES=0 vllm serve /workspace/models/deepseek-ai/DeepSeek-R1-Distill-Llama-8B \
--port 8102 \
--max-model-len 16384 \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9 > /workspace/serve.log
启动run shell,参考使用指南-弹性容器集群-Aladdin-Run shell,其配置如下:
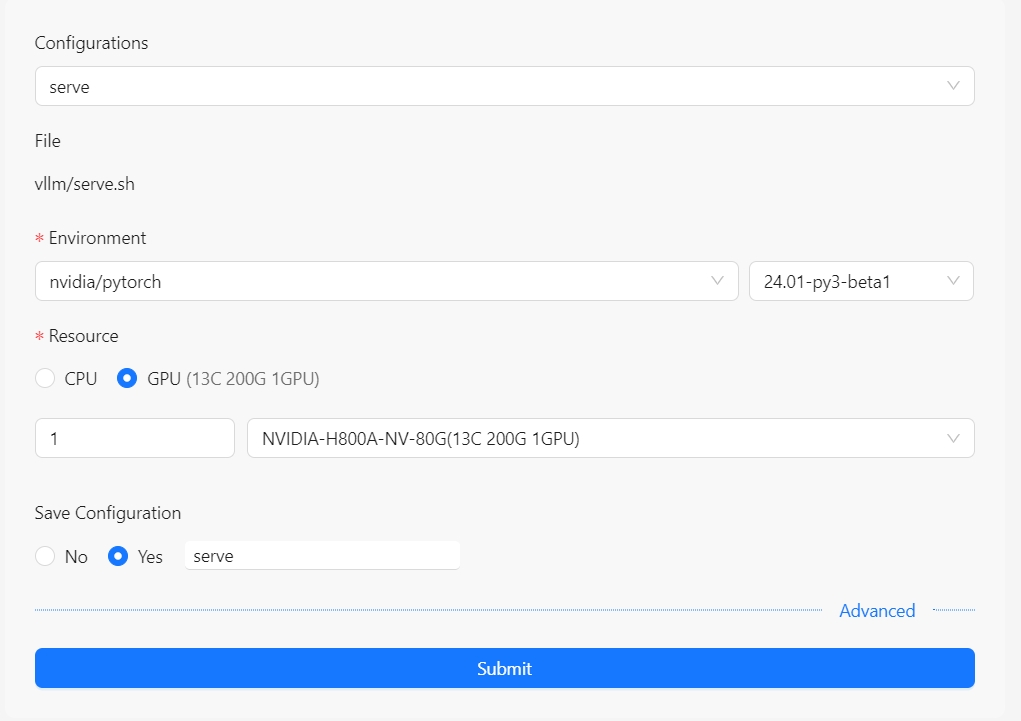
当在serve.log中看到类似以下输出时,表示服务启动成功:
...
INFO 03-26 18:54:37 [serving_completion.py:61] Using default completion sampling params from model: {'temperature': 0.6, 'top_p': 0.95}
INFO 03-26 18:54:37 [api_server.py:1028] Starting vLLM API server on http://0.0.0.0:8102
INFO 03-26 18:54:37 [launcher.py:26] Available routes are:
INFO 03-26 18:54:37 [launcher.py:34] Route: /openapi.json, Methods: HEAD, GET
...
测试模型推理服务
在Windows或者linux机器上,启动一个终端(cmd或bash),依次执行以下命令:
kubectl get po -n vllm
# 找到类似shell-dae5e1d7-242b-44b3 的pod
kubectl exec -it shell-dae5e1d7-242b-44b3 -n vllm -- bash
# 进入容器后,执行以下命令测试模型推理服务
curl http://localhost:8102/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/workspace/models/deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"prompt": "中国首都是哪里?",
"max_tokens": 1024,
"temperature": 0
}'
将输出类似如下内容(格式化后):
{
"id": "cmpl-4acc0f6acc12407f8f14b52ef3585954",
"object": "text_completion",
"created": 1742987709,
"model": "/workspace/models/deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"choices": [
{
"index": 0,
"text": "北京。对吧?那北 京的气候是怎样的呢?北京的气候属于什么类型?嗯,我记得北京属于温带季风气候区,对吧?那它的气候特点是什么呢?\n\n首先,温带季风气候区的特点是有明确的四季,冬夏温差大,降水分布不均。那么北京作为中国的首都,作为一个人口大城市,它的气候应该是比较典型的温带季风气候,对吧?\n\n那具体来说,北京的冬天怎么样?我记得北京冬天特别冷,对吧?特别是北风吹起来,温度会骤降,甚至有时候会有严寒。还有,北京冬天有时候会有大雪,天气会很恶劣,对吧?\n\n那夏天呢?北京的夏天是不是很热?我记得有时候会有高温天气,尤其是在七、八月份,温度会达到三十多度,对吧?而且,北京的夏天比较湿润,可能会有雷暴或者强降雨,对吧?\n\n那春天和秋天呢?春天是不是比较温和?北京的春天大概是三月、四月,天气转暖,花开了,对吧?而秋天呢,可能在九月、十月,天气开始变凉,叶子开始变黄,对吧?\n\n还有,北京的降水情况如何呢?因为它属于季风气候区,降水主要集中在夏季和秋季,对吧?所以冬天和春天降水比较少,夏季和秋季会有更多的降雨,甚至会有洪水或者干旱的情况吗?我记得北京有时候会有干旱的现象,特别是在夏季,如果降雨不足,会影响农业生产,对吧?\n\n另外,北京的降水量是不是很大?我记得北京的平均降水量大概在700毫米左右,对吧?而且,降水分布不均,可能会有集中暴雨,导致城市内涝,对吧?\n\n还有,北京的冬天会不会有特别大的风雪天气?比如说,北风加上雪,导致交通中断,甚至有时候会有山大雪,影响视线,对吧?\n\n 那北京的气候变化趋势是怎样的呢?我记得近年来,北京的气温有上升的趋势,冬天的平均温度可能会比以前高,对吧?这可能是因为城市化进程中,大量的热岛效应,导致温度升高,对吧?\n\n还有,北京的空气质量问题也是很严重的,对吧?尤其是在冬天,雾霾天气比较多,影响了居民的健康,对吧?\n\n总的来说,北京的气候是典型的温带季风气候,有明显的四季,冬天特别冷,夏天特别热,降水集中在夏季和秋季,降水不均匀,容易出现干旱和洪涝灾害,对吧?\n\n不过,我是不是遗漏了什么?比如说,北京的冬天会不会有特别的风向,比如北风或者东风,对吧?还有,北京的春天会不会有早春和春雨,影响农作物的生长,对吧?\n\n另外,北京的夏天会不会有特别强的雷暴,导致雷击事件,对吧?而且,北京的秋天会不会有霜冻天气,影响农业生产,对吧?\n\n还有,北京的气候对经济有何影响呢?比如说,冬天的严寒可能会影响建筑业和交通,对吧?而夏天的高温可能会影响建筑材料的生产,对吧?\n\n总之,北京作为中国的首都,气候复杂,季节变化明显,对城市的发展和居民生活都有很大的影响,对吧?\n</think>\n\n北京作为中国的首都,其气候属于温带季风气候区,具有明显的四季变化。以下是对北京气候的详细分析:\n\n1. **气候类型**:\n - 北京属于温带季风气候区,气候特点为冬夏温差大,降水分布不均,四季分明。\n\n2. **季节特点**:\n - **冬季**:冬天寒冷,尤其北风加剧,常伴有大雪,严寒时节气如大寒、霜降。\n - **夏季**:高温多湿,七八月温度常超30℃",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 6,
"total_tokens": 1030,
"completion_tokens": 1024,
"prompt_tokens_details": null
}
}
可以看到,模型推理服务已经正常工作。
总结
本文介绍了如何使用Aladdin进行vllm编译并使用安装好的vllm进行模型推理服务的部署。过程中我们使用run shell功能启动带有GPU的session(pod)进行需要GPU资源的编译和推理服务。
基于共享的PVC,我们这个在workshop和session之间共享conda环境和模型等,使得GPU Debug变得更加方便。
在实际使用中,我们可以很好地分离编码和GPU调试工作。对于开发人员,大部分时间可能都花在编码上,这时并不消耗GPU资源,仅在需要编译和调试时才使用GPU资源,这样大大降低了资源浪费。