推理Serverless 使用算力更省钱
在弹性容器集群使用kubeai实现推理服务的Serverless,适配算力包模式,可在不使用负载时自动停止,负载高的情况下自动扩容,实现使用即扣费,不使用即停止的弹性伸缩能力。
本文中我们将使用openweui和Qwen2.5-1.5B-Instruct模型,介绍如何在弹性容器集群中用kubeai作为推理服务的Serverless方案
提示
在该实践中,以“北京一区”作为示例来创建弹性集群。后续使用的镜像仓库等,也都是在“北京一区”的应用市场公共仓库。
前置条件
- 已开通弹性容器集群,且至少有一块GPU卡,如未开通请开通弹性容器集群。
- 已安装kubectl安装命令行工具(kubectl)。
- 已安装Helm,若未安装,请参考Helm使用
- 下载Kubeai Serveless App,若未下载,请参考 下载 Kubeai Serveless App
Serverless服务部署
# 解压Kubeai Serveless App
tar -zxvf serverless.tar.gz
提示
上表中各文件中的配置仅以“北京一区”为示例,若您选择在其他智算中心(北京二区,北京三区,北京四区等)开通弹性容器集群进行本教程的实践,您需要修改配置文件中镜像仓库的地址:
- 北京一区:registry.hd-01.alayanew.com:8443
- 北京二区:registry.hd-02.alayanew.com:8443
- 北京三区:registry.hd-03.alayanew.com:8443
- 北京四区:registry.xn-01.alayanew.com:8443
# 安装
helm install kubeai -n kubeai ./serverless/kubeai/ --set vksID=`kubectl cluster-info | awk -F'/' '{print $NF}' | head -n 1`
当执行这个命令后,将会看到类似以下的输出:
NAME: kubeai
LAST DEPLOYED: Wed Jan 22 13:47:43 2025
NAMESPACE: kubeai
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Application successfully deployed!
To access the OpenWebUI, use the following URL:
https://openwebui-x-kubeai-x-vckg0tnis123.sproxy.hd-01.alayanew.com:22443/
To interact with the KubeAI API, use the following URL:
https://kubeai-x-kubeai-x-vckg0tnis123.sproxy.hd-01.alayanew.com:22443
For example, to retrieve the list of models, run:
curl https://kubeai-x-kubeai-x-vckg0tnis123.sproxy.hd-01.alayanew.com:22443/openai/v1/models
To check the status of the deployed containers, use the following command:
kubectl get pods -n kubeai
执行 kubectl get pods -n kubeai 可查看输出如下
NAME READY STATUS RESTARTS AGE
devpod-67f9f5697b-hp67l 1/1 Running 0 1m40s
kubeai-784b9f7c8f-xk5wk 1/1 Running 0 1m40s
openwebui-9d5bcf687-9nhqb 1/1 Running 0 1m40s
提示
devpod是弹性容器集群中用于开发调试的Pod,cpu启动,计费较低,可在容器内下载模型等kubeai是Kubeai Serveless,基于Kubernetes的Operator,用于管理Model的生命周期openwebui是一个开源WebUI,用于在页面使用大模型聊天
下载模型文件
如已下载模型,可跳过此步骤
# exec dev pod
kubectl exec -it devpod-67f9f5697b-hp67l bash -n kubeai
# download model
cd /mnt
huggingface-cli download --resume-download Qwen/Qwen2.5-1.5B-Instruct --local-dir Qwen/Qwen2.5-1.5B-Instruct
模型部署
# 部署model
kubectl apply -f serverless/models/model.yaml
# 查看model资源对象
kubectl get models -n kubeai
以上命令输出如下
# 部署model
model.kubeai.org/qwen2.5-1.5b-instruct created
---
# 查看model资源对象
NAME AGE
qwen2.5-1.5b-instruct 3m22s
model.yaml 内容如下
apiVersion: kubeai.org/v1
kind: Model
metadata:
name: qwen2.5-1.5b-instruct
namespace: kubeai
spec:
features: [TextGeneration]
owner: NousResearch
url: pvc://pvc-capacity-userdata/Qwen/Qwen2.5-1.5B-Instruct
engine: VLLM
imagePullSecrets: ["harbor-secret"]
resourceProfile: nvidia-gpu-h800:1
minReplicas: 0
maxReplicas: 2
targetRequests: 250
scaleDownDelaySeconds: 45
提示
kubectl get models -n kubeai可查看已部署的模型url: 其中pvc-capacity-userdata为集群固定pvc, Qwen/Qwen2.5-1.5B-Instruct为在存储中的路径,在下载模型文件时下载到此路径resourceProfile: 使用哪些GPU,目前支持nvidia.com/gpu-h800,nvidia.com/gpu-l40s,default, 其中冒号后面为卡数量,按需使用engine: VLLM,表示使用VLLM引擎,VLLM是Kubeai Serveless App中用于处理文本生成任务的引擎minReplicas: 最小扩容,在闲时可以缩容到此数量maxReplicas:最大扩容,在忙时可以扩容到此数量TargetRequests: autoscaler将尝试模型运行的Pod上平均活动请求数。scaleDownDelaySeconds: 是在自动缩放算法确定应缩减部署后,缩减部署之前的最短时间。
模型的使用
使用OpenWebUI
打开浏览器,输入如下网址,免登录
https://openwebui-x-kubeai-x-{vksID}.sproxy.hd-01.alayanew.com:22443/
其中 {vksId}: 替换为您实际使用集群的vksId,获取方式如下
kubectl cluster-info | awk -F'/' '{print $NF}' | head -n 1
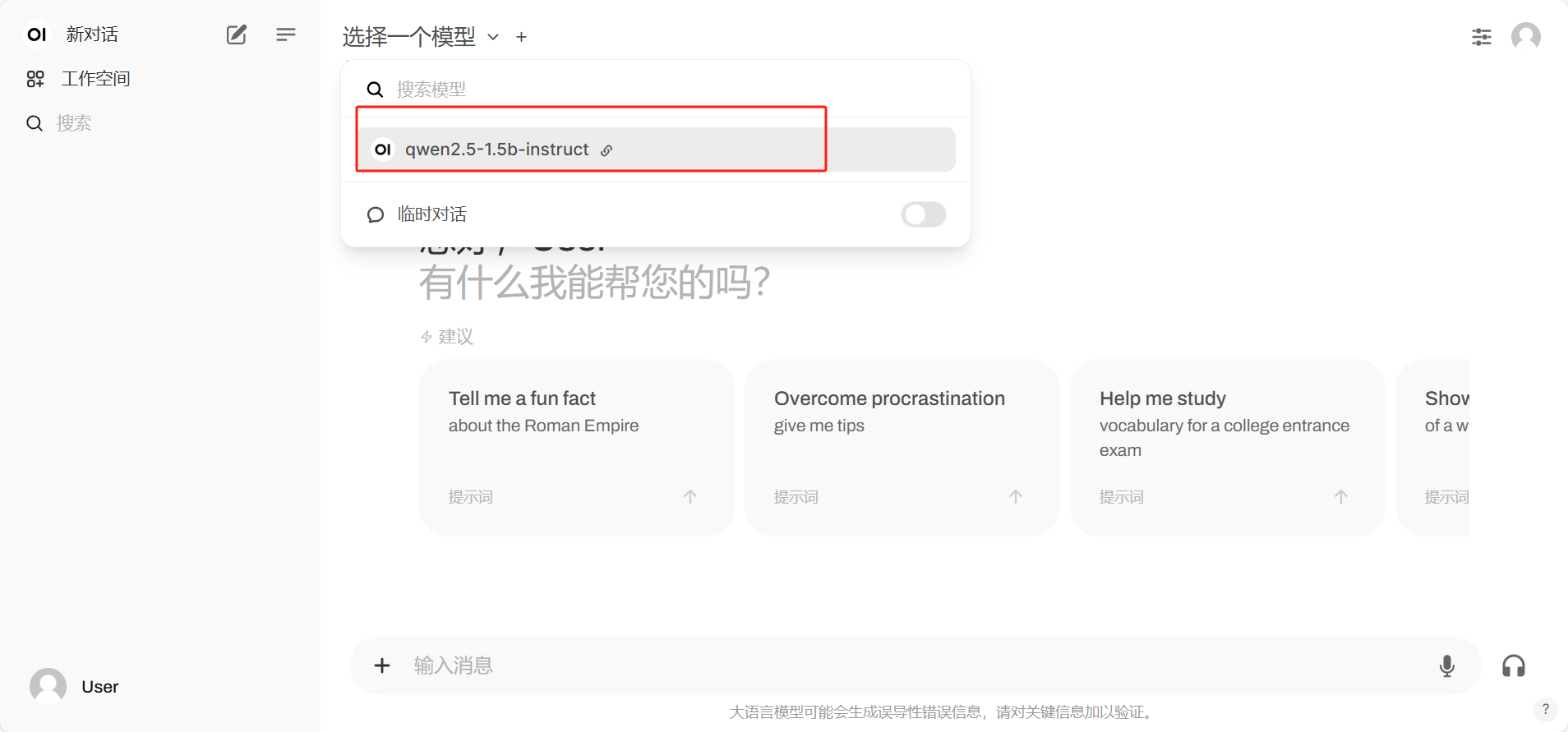
选择模型进行聊天
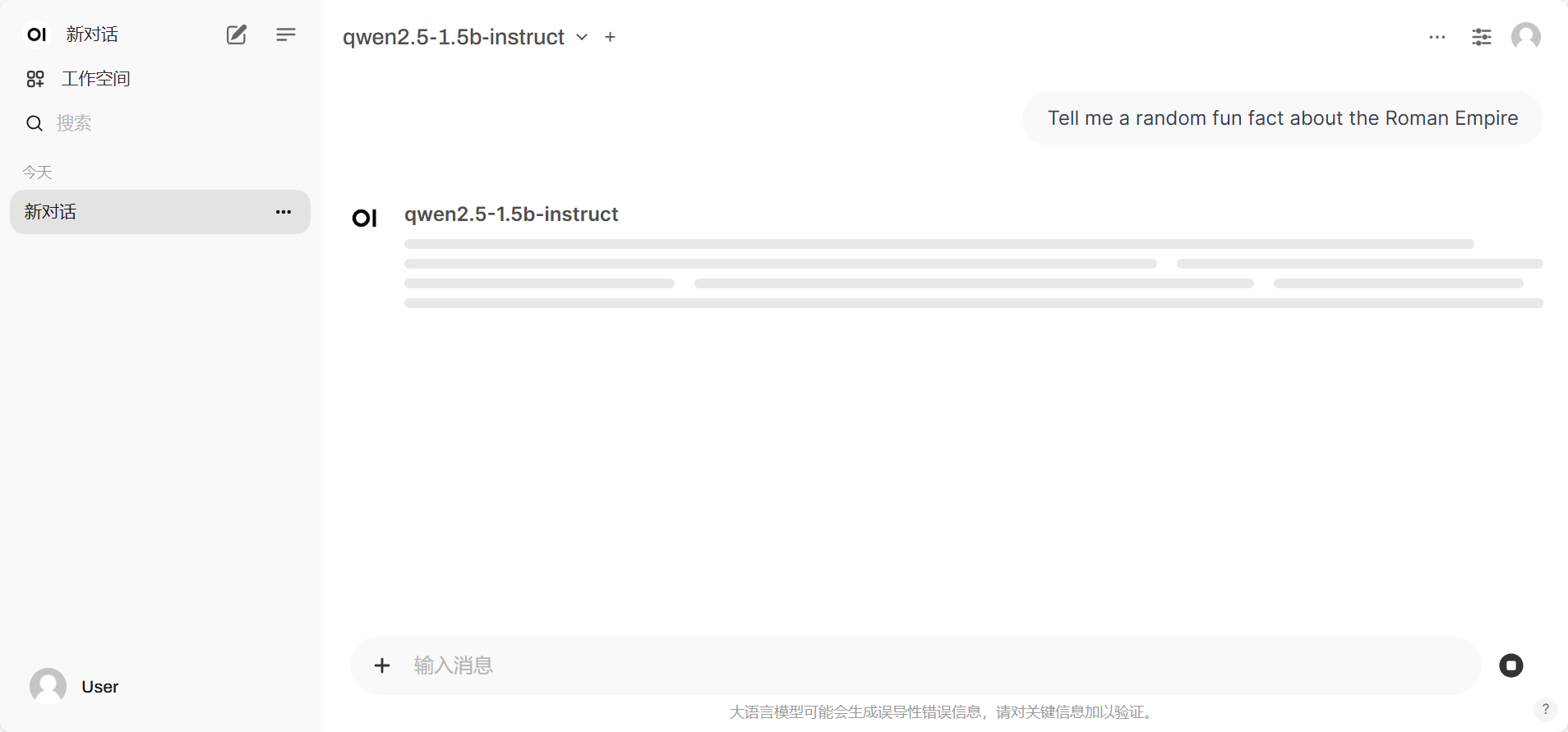
同时kubectl get pod -w -n kubeai 观察pod的启动,可以发现会启动pod进行模型的推理
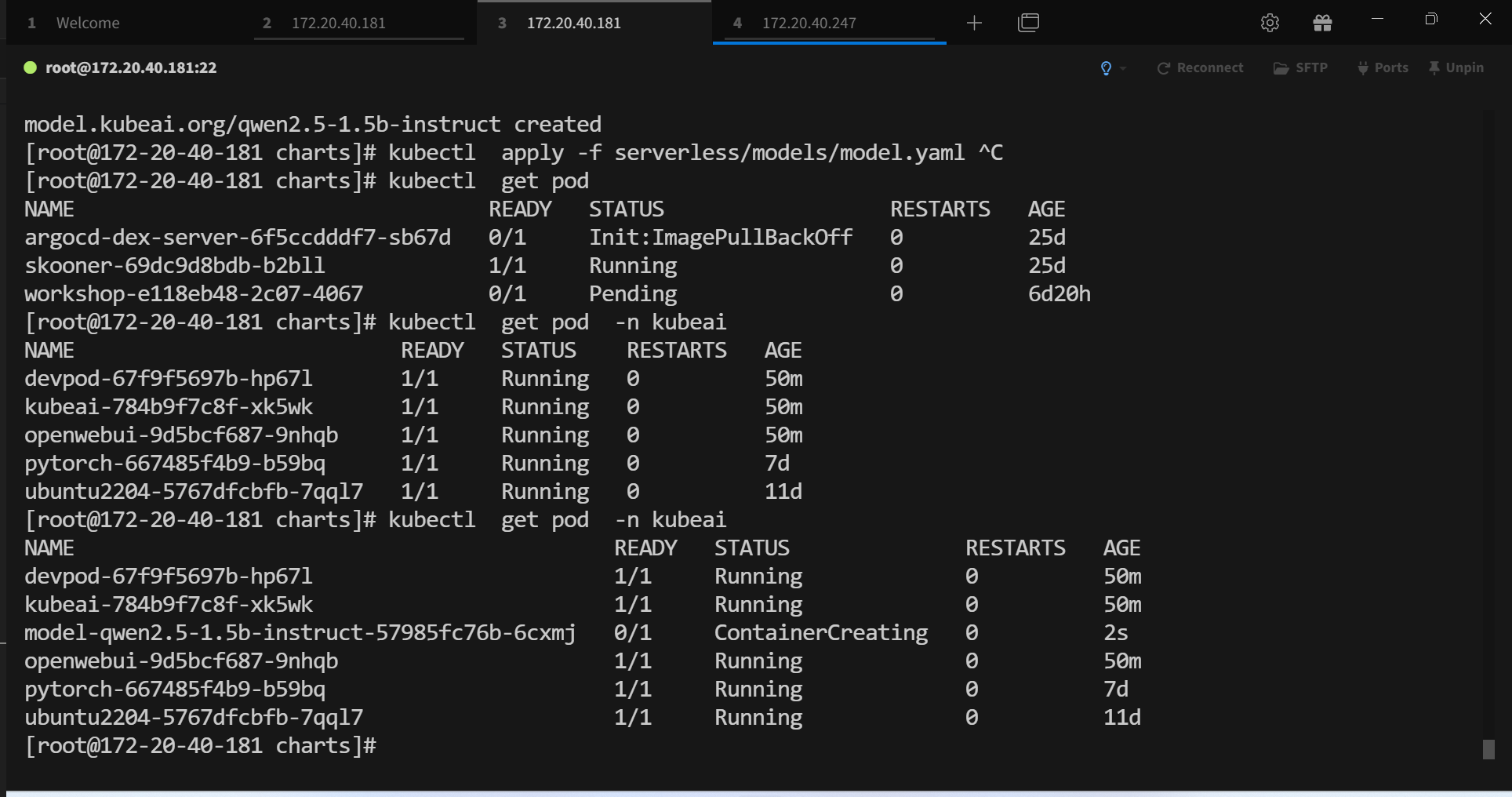
可查看模型的推理结果
 过10min如果一直没有活动的请求进来会自动回收pod,停止GPU计费
过10min如果一直没有活动的请求进来会自动回收pod,停止GPU计费
使用API
获取模型
uri:
/openai/v1/models
curl https://kubeai-x-kubeai-x-vckg0tnis123.sproxy.hd-01.alayanew.com:22443/openai/v1/models
推理
uri:
/openai/v1/chat/completions
curl --location --request POST 'https://kubeai-x-kubeai-x-vckg0tnis123.sproxy.hd-01.alayanew.com:22443/openai/v1/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "qwen2.5-1.5b-instruct",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many letters <r> in the word strawberry?"
}
]
}'
如果模型未启动,和使用openwebui一样会自动启动pod进行推理
提示
/openai为kubeai的API路径,/chat/completions为模型推理的API路径
kubeai可代理的模型uri如下
- /openai/v1/chat/completions -> 代理到模型 /v1/chat/completions
- /openai/v1/completions -> 代理到模型 /v1/completions
- /openai/v1/embeddings -> 代理到模型 /v1/embeddings
- /openai/v1/audio/transcriptions -> 代理到模型 /v1/audio/transcriptions
- /openai/api/v1/* -> 代理到模型 /api/v1/*
- /openai/gradio_api/v1/* -> 代理到模型 /gradio_api/v1/*