使用LLamaFactory微调Qwen2-VL构建文旅大模型
LLaMA Factory 是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过 Web UI 界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架之一,GitHub 星标超过 3 万。
使用场景
LLama Factory 由于其低代码特性,可以快速部署模型微调环境并进行测试,适用于各种场景,包括但不限于:
- 在医学、法律、金融、文化等垂直领域上,使用 LLaMA-Factory 微调基础 LLaMA 模型,提升模型在特定任务上的表现。
- 在资源有限的场景(如边缘设备或轻量服务器)中,通过微调后的模型快速部署服务。
- 用于开发诸如对话机器人、智能问答、内容生成等任务的应用。
- 为研究人员提供方便的工具来实验新方法(如参数高效微调),对比和评估不同微调策略的效果。
操作步骤
部署前准备工作
本次部署使用到Docker和Kubernetes,请准备好Docker环境,并确保本地有可用的Kubernestes客户端工具kubectl。
Docker环境安装请参考: 安装Docker
kubectl安装请参考:安装命令行工具(kubectl)
开通集群
资源最低要求
| 资源类型 | 数量 | 说明 |
|---|---|---|
| GPU | 1 | gpu-h800 |
| CPU | 8 core起 | |
| 内存 | 32G 起 | |
| 存储 | 300G 起 | |
| Harbor存储 | 100G | 用于保存镜像 |
申请开通
开通集群请参考:开通弹性容器集群
确认 弹性容器集群 和后面使用的 镜像仓库 是在同一个智算中心开通的。
镜像准备
包括以下步骤:
用户名密码:查看开通镜像仓库时的通知短信
镜像仓库域名:参考镜像仓库的使用
镜像仓库地址 :由 镜像仓库域名/项目 组成
-
下载LLaMA Factory项目源码,我们将使用0.9.1版本。
git clone -b v0.9.1 --depth=1 https://github.com/hiyouga/LLaMA-Factory.git -
进入项目根目录,执行Dockerfile文件,生成镜像。
docker build -t 镜像仓库地址/llama-factory:0.9.1 -f docker/docker-cuda/Dockerfile --build-arg PIP_INDEX=https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple . -
登录镜像仓库,推送镜像
docker login 镜像仓库域名 -u 用户名 -p 密码
docker push 镜像仓库地址/llama-factory:0.9.1
请将 镜像仓库地址, 域名, 用户名, 密码 替换为自己的
请确认 镜像仓库 和 弹性容器集群 是在同一个智算中心开通的。
当执行完毕后,请检查镜像仓库中是有镜像文件llama-factory:0.9.1存在。
关于如何查看镜像仓库,请参考:使用Harbor管理镜像资源
脚本准备
请下载脚本文件压缩包,并解压到本地目录。在前面下载并解压的模板脚本文件中,对所有文件进行变量替换。
需要替换的变量有:
| 变量名 | 所在文件 | 示例 |
|---|---|---|
| 镜像仓库地址 | deployment.yaml | registry.hd-01.alayanew.com:8443/alayanew-******-5cfd029439a8 |
| GPU_resource_name | deployment.yaml | gpu-h800 |
| 镜像仓库域名 | harbor-config.json | registry.hd-01.alayanew.com:8443 |
| 用户名 | harbor-config.json | hb_abc123 |
| 密码 | harbor-config.json | 123456 |
secret准备
secret文件是用于保存敏感信息的,如对象存储的密钥等。本次部署中需要对harbor registry的用户名和密码进行加密,并保存到secret文件中。
- 当执行过前面的步骤后,请将harbor-config.json中的内容做base64编码。linux中可以使用base64命令进行编码。或者在线网站也可以进行编码。可以参考:https://tool.lu/encdec/
- 将编码后的内容保存到harbor-secret.yaml的.dockerconfigjson字段。 例如:
apiVersion: v1
kind: Secret
metadata:
name: alaya-harbor-secret
type: kubernetes.io/dockerconfigjson
data:
.dockerconfigjson: <base64编码后的内容>
部署应用
包含以下步骤:
- 执行k8s配置文件,部署应用
- 检查k8s部署结果
- 进入pod,并进行初始化
1.执行部署脚本
请在脚本目录下执行以下命令:
kubectl apply -k .
确保执行过程中没有错误。请注意:其中ServiceExporter的输出需要记录,后面将以这个url访问LLaMA Factory的Web UI。
2.检查部署结果
请执行以下命令:
kubectl get pods -n ns-lf
如果出现以下输出,说明部署成功:
NAME READY STATUS RESTARTS AGE
llamafactory-6f45d5c9d6-hvq59 1/1 Running 0 5h10m
其中llamafactory-6f45d5c9d6-hvq59是pod的名字,每次部署都会产生一个新的pod名字,后面的命令都需要使用这个名字。
3.进入pod,并进行初始化
请执行以下命令:
kubectl exec -it llamafactory-6f45d5c9d6-hvq59 -n ns-lf -- /bin/bash
请使用实际的pod名字替换上面的llamafactory-6f45d5c9d6-hvq59。 进入后,执行以下命令以确认llamafactory安装成功:
llamafactory-cli version
# 结果示例:
----------------------------------------------------------
| Welcome to LLaMA Factory, version 0.9.1 |
| |
| Project page: https://github.com/hiyouga/LLaMA-Factory |
----------------------------------------------------------
安装modelscope包,本教程中使用的模型从modelscope下载,请确保正确安装了modelscope:
pip install modelscope
数据准备
使用以下命令准备数据:
cd /app #确保在/app目录下
wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/llama_factory/Qwen2-VL-History.zip
unzip Qwen2-VL-History.zip -d data
开始使用
进入/app/目录,执行以下命令:
USE_MODELSCOPE_HUB=1 llamafactory-cli webui
命令运行成功后,就可以以前文提到的ServiceExporter的url访问LLaMA Factory的Web UI。
微调
1.加载微调数据并设置参数
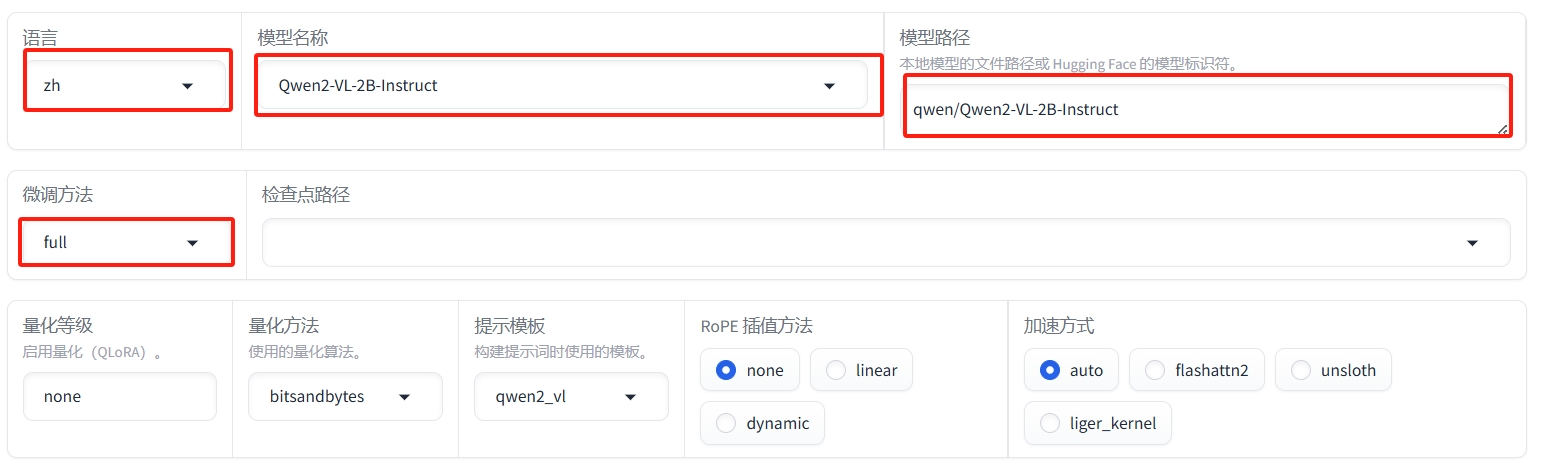
① 打开UI,看到以下页面并按照下图设置参数:
②选择"Train"标签页, 选择数据集"train"
具体请参照下图:
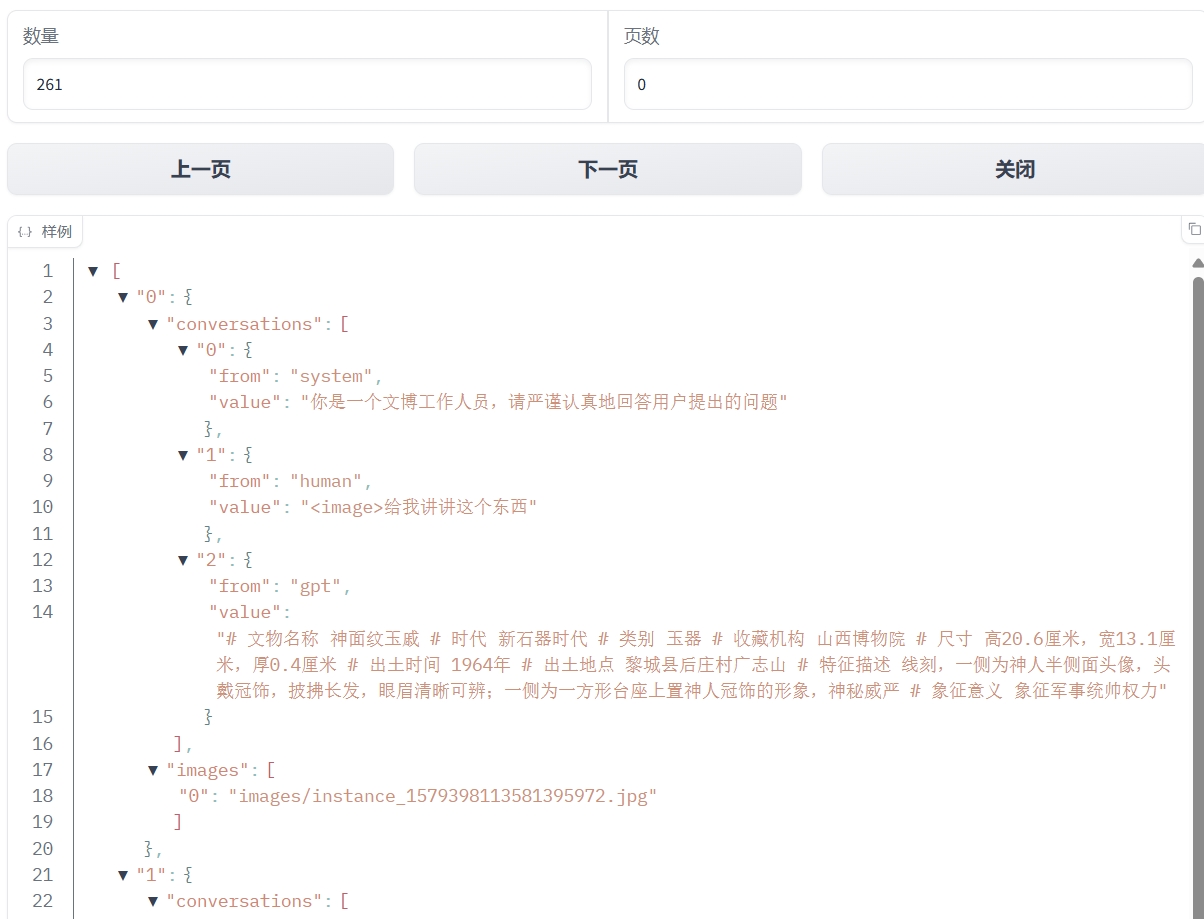
 当点击"预览数据集"按钮后,可以看到数据集的预览。
当点击"预览数据集"按钮后,可以看到数据集的预览。
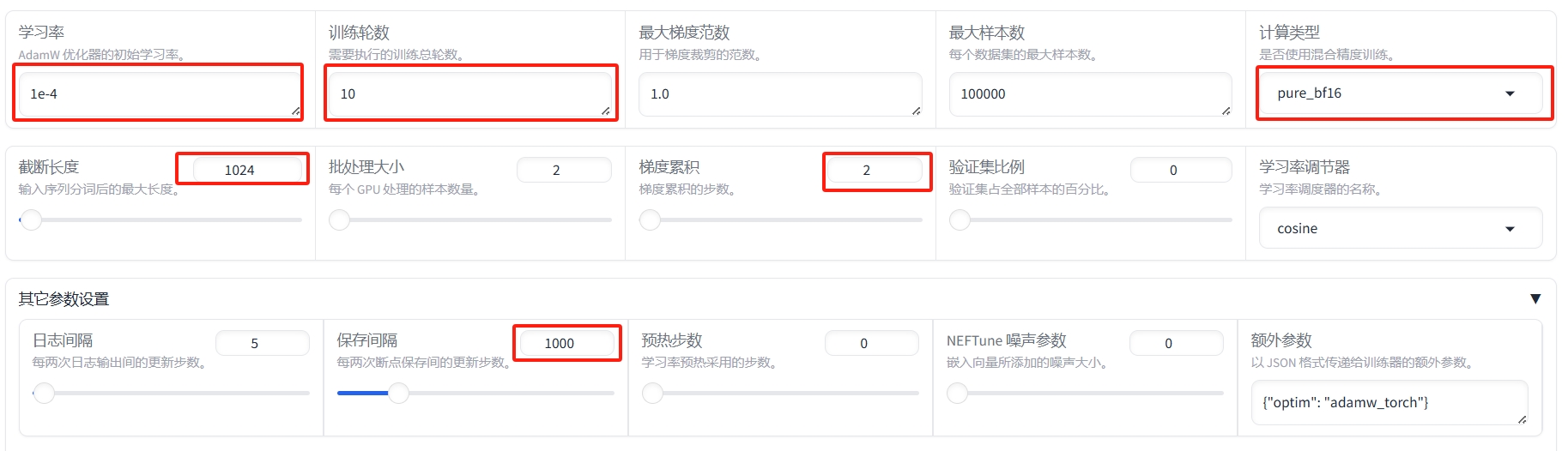
 ③ 如下图设置参数:
③ 如下图设置参数:
2.开始微调
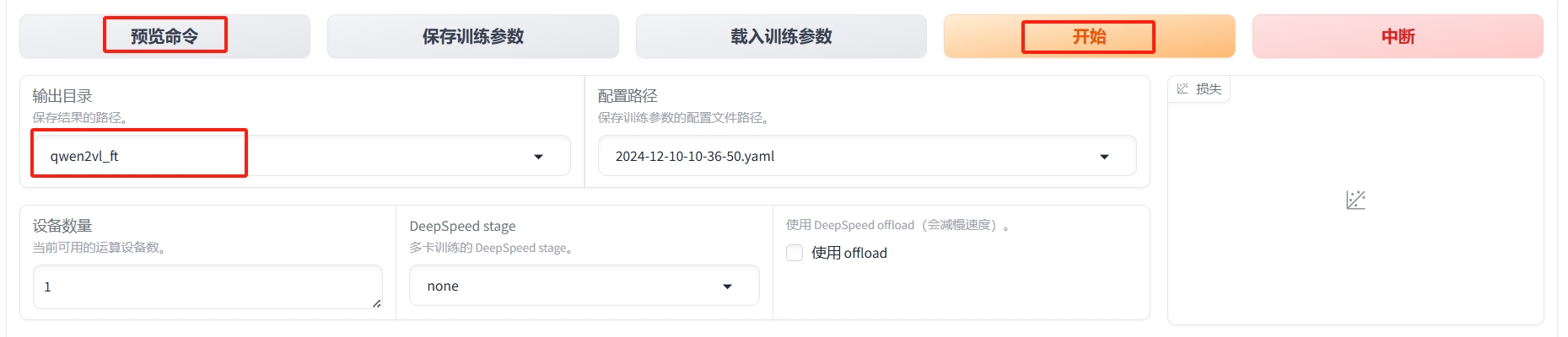
按下图设置输出目录,点击"预览命令"按钮,可以看到微调命令。如果想要在命令行下运行,可以复制命令到终端运行。
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path qwen/Qwen2-VL-2B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type full \
--template qwen2_vl \
--flash_attn auto \
--dataset_dir data \
--dataset train \
--cutoff_len 1024 \
--learning_rate 0.0001 \
--num_train_epochs 10.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 2 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 1000 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Qwen2-VL-2B-Instruct/full/qwen2vl_ft \
--pure_bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--optim adamw_torch
点击“开始”按钮,开始微调。页面最下方会显示微调过程的日志。同时,也将呈现微调的进度以及loss曲线。
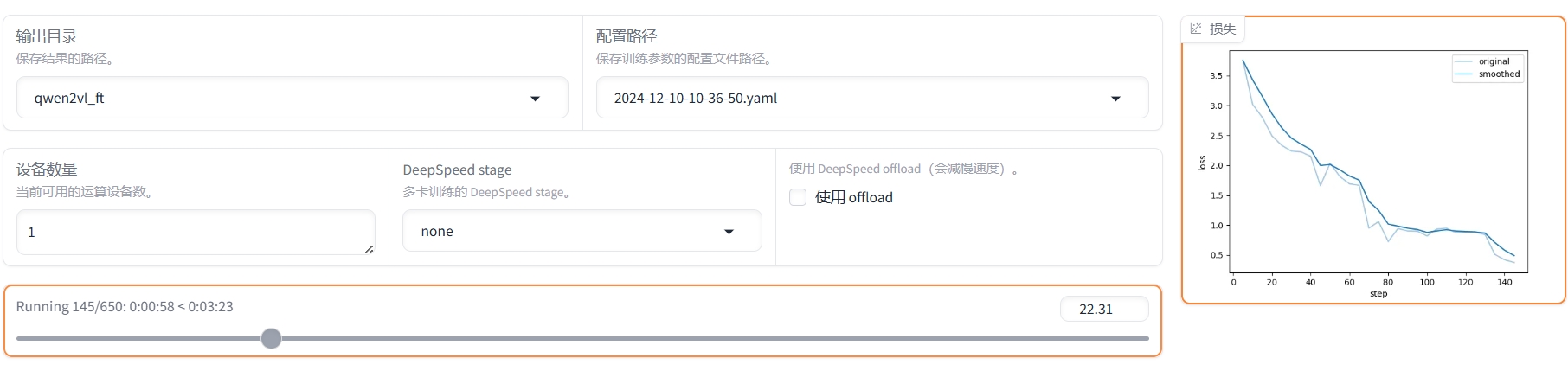
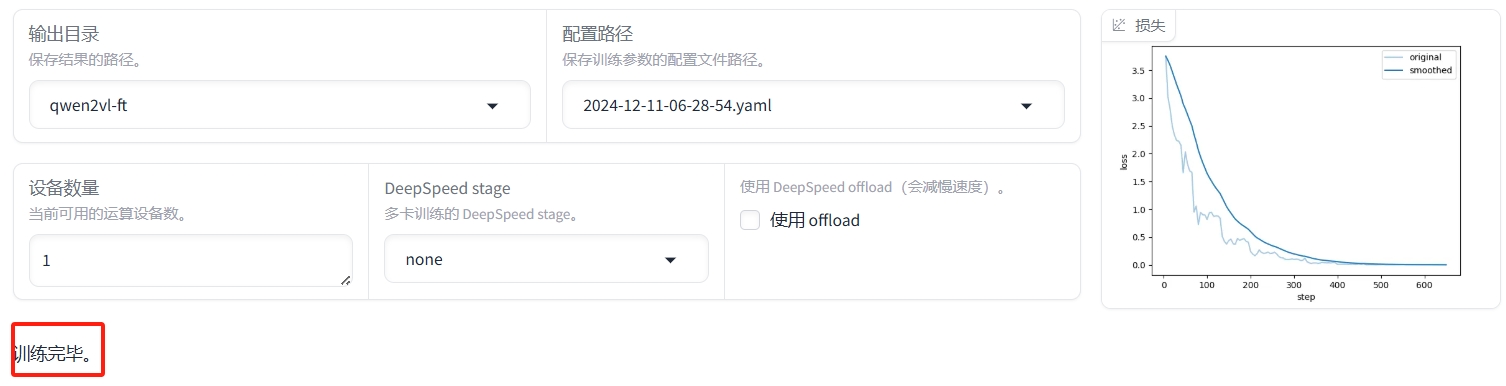
微调需要一定时间,请耐心等待。微调完成后,输出框显示“训练完毕”。
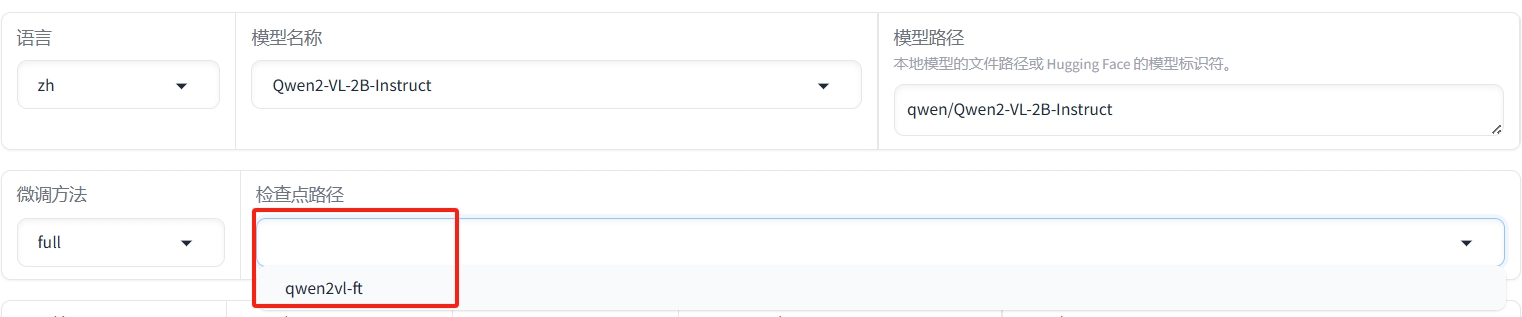
3.加载微调模型及对话
①在对话框的顶部,在检查点路径中选择微调模型的路径。
 ②在"chat"标签页中,点击加载模型按钮,加载微调模型。
②在"chat"标签页中,点击加载模型按钮,加载微调模型。
 如下图,输入系统角色,上传图片,然后给出问题,系统将给出答案。
如下图,输入系统角色,上传图片,然后给出问题,系统将给出答案。
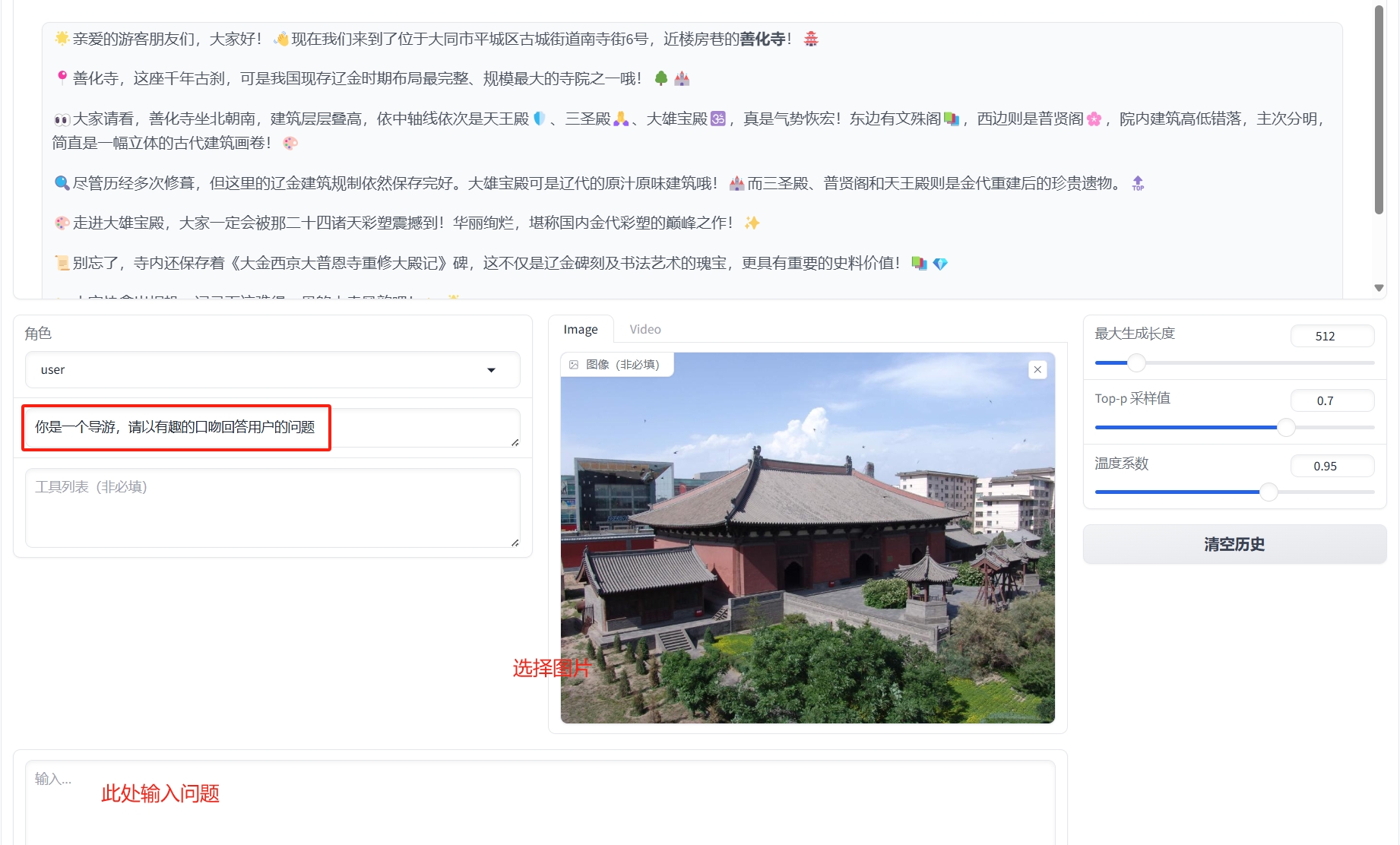 ③使用测试图片测试图片1或者测试图片2进行测试。
③使用测试图片测试图片1或者测试图片2进行测试。
作为对比,我们使用原生的Qwen2-VL-2B-Instruct模型进行对话。首先卸载模型:
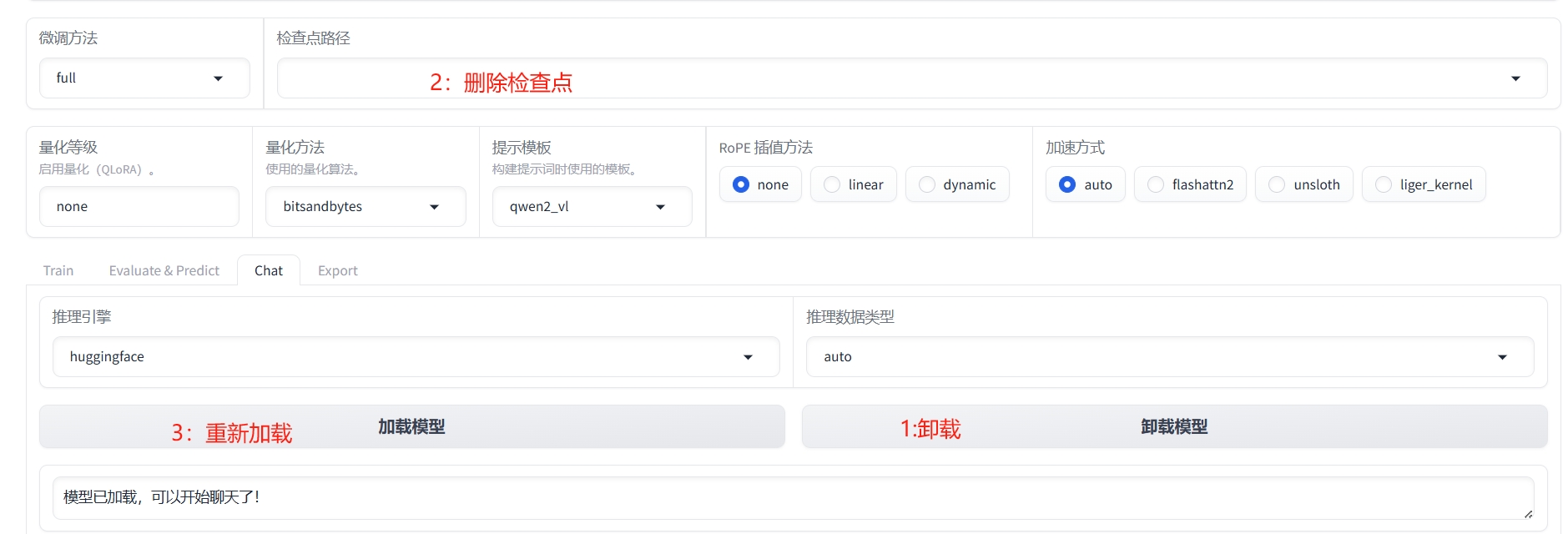 然后使用原生模型进行对话:
然后使用原生模型进行对话:
 可以看出,经过微调后的模型,能够按照指定的角色,以更符合实际场景的方式回答问题。
可以看出,经过微调后的模型,能够按照指定的角色,以更符合实际场景的方式回答问题。
总结
本教程介绍了如何在Alaya NeW平台上,使用LLaMA Factory微调Qwen2-VL构建文旅大模型,并使用测试图片进行了测试。用户可以根据自己的需求,选择不同的基模型,以及不同的数据集进行微调,并结合实际业务集成使用。
关于license
请按照LLamaFactory的版权要求使用,请参考:https://github.com/hiyouga/LLaMA-Factory/tree/main?tab=Apache-2.0-1-ov-file