使用swift训练一个古文翻译腔机器人
古文翻译腔是我们学习文言文中经常看到的腔调,类似于古早的欧美译制腔,古文翻译腔也有一定的回复风格。
比如:
-
夸张的对比和人生哲理:
- “来自东方的伟大将领可以举起巨大的锤子在敌军中肆意厮杀,甚至战神看到了也感到啧啧称奇,世界上的成功,正是这样的人才能做到啊!”
-
双重否定和排比句:
- “优秀的实验结果难道不是需要努力实践与学习而得到的吗?这世界上有知识是可以不通过刻苦奋斗而习得的吗”
-
感慨:
- “嗟乎!本科后面读硕士,硕士后面读博士,这不过就是人生的轨迹罢了!”
下面我们就让模型"学废"这种调调。
什么时候模型需要训练?
- 垂直类目的数据集,在基模型中不包含该类知识
- 更优质的数据集,可以让基模型有更好的效果
- 某种特定的问答范式,基模型通过prompt-engineering无法拟合该范式
因此,古文翻译腔可以看做是“某个需要角色扮演的微信小程序的后台服务需求”的场景。
前置条件
本教程假定您已经具备以下条件:
- 在您的系统上安装了kubectl
- 开通了Alaya NeW弹性容器集群,具体步骤参考:开通弹性容器集群
确认 弹性容器集群 和后面使用的 镜像仓库 是在同一个智算中心开通的。
教程源代码
首先下载本教程所需要的源码文件
清单
本教程包含以下文件,以下是文件的作用说明。
| 文件名 | 说明 |
|---|---|
| deployment.yaml | 定义Deployment资源:定义如何启停pod |
部署
在本示例中,部署信息由deployment.yaml文件指定。
具体指示弹性容器集群的Kubernetes control plane以下信息:
- 确保在任何时候只有一个Pod运行。这个实例是通过清单中的
spec.replicas键值对定义的。 - 在运行pod的弹性容器集群计算节点上预留GPU、CPU和内存资源。在Kubernetes Pod中运行的每个Jupyter实例分配了1个gpu,由下面的
spec.template.spec.containers.resources.limits.nvidia.com/gpu-h800键值对定义。 - 指定镜像,由
spec.template.spec.containers.image键值对定义。 - 指定pvc的挂载目录,由
spec.template.spec.containers.volumeMounts键值对定义。 - 指定pvc,由
spec.template.spec.volumes定义
编写deployment.yaml文件时,请根据实际情况替换以下信息:
| 变量名 | 说明 | 来源 | 示例 |
|---|---|---|---|
| image | 镜像名称 | 自定义镜像 | registry.hd-01.alayanew.com:8443/user/ubuntu2204:1.0.2 |
| resources.requests.[GPU] | GPU资源信息 | 弹性容器集群 | nvidia.com/gpu-h800 |
| volumes.persistentVolumeClaim.claimName | pvc名称 | 默认创建的pvc,参考声明存储 | pvc-capacity-userdata |
操作步骤
镜像准备
请确认 镜像仓库 和 弹性容器集群 是在同一个智算中心开通的。
以下命令中,请将账号,密码,镜像名称,镜像仓库地址等信息替换成你自己的。
用户名/密码:查看开通镜像仓库时的通知短信
镜像仓库域名:参考镜像仓库的使用
镜像仓库地址 :由 镜像仓库域名/项目 组成
# pull image
docker pull modelscope-registry.cn-beijing.cr.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-cuda12.1.0-py310-torch2.3.1-tf2.16.1-1.21.0
#login
docker login 镜像仓库域名 -u 用户名 -p 密码
# tag
docker tag \
modelscope-registry.cn-beijing.cr.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-cuda12.1.0-py310-torch2.3.1-tf2.16.1-1.21.0 \
镜像仓库地址/modelscope:ubuntu22.04-cuda12.1.0-py310-torch2.3.1-tf2.16.1-1.21.0
# push
docker push 镜像仓库地址/modelscope:ubuntu22.04-cuda12.1.0-py310-torch2.3.1-tf2.16.1-1.21.0
k8s资源部署
# 声明弹性容器集群配置
export KUBECONFIG="[/your/path/to/kubeconfig]"
# 创建namespace
kubectl create namespace swift
# 创建secret
kubectl create secret docker-registry harbor-secret \
--docker-server=registry.hd-01.alayanew.com:8443\
--docker-username="your userName" \
--docker-password="your password" \
--docker-email="your email" \
--namespace swift
# 创建deploy
kubectl create -f deployment.yaml
在弹性容器集群中进行微调
-
进入pod
# 获取pod信息
kubectl get pod -n swift# 进入pod
kubectl exec -it yourPodName bash -n swift #请更换成get pod中获取的podname
-
下载swift框架
镜像里的工作空间为"/mnt/workspace",我们切换到该目录进行微调工作
# 切换工作目录
cd /mnt/workspace
# 下载swift
git clone https://gh-proxy.com/github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e '.[llm]'
-
下载模型
本镜像设置的默认下载路径为:"/mnt/workspace/.cache/modelscope/models/Qwen/Qwen2-7B-Instruct "
modelscope download --model Qwen/Qwen2-7B-Instruct
-
下载数据集
本镜像设置的默认下载路径为:"/mnt/workspace/.cache/modelscope/datasets/swift/classical_chinese_translate/"
modelscope download --dataset swift/classical_chinese_translate
-
微调
执行一下微调命令,可根据实际情况,设置你的模型路径,数据集路径,输出目录等参数。
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--custom_register_path /mnt/workspace/ms-swift/examples/custom/dataset.py \
/mnt/workspace/ms-swift/examples/custom/model.py \
--model /mnt/workspace/.cache/modelscope/models/Qwen/Qwen2-7B-Instruct \
--train_type lora \
--output_dir /mnt/workspace/output/qwen2-7b-instruct \
--dataset /mnt/workspace/.cache/modelscope/datasets/swift/classical_chinese_translate \
--num_train_epochs 3 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--max_length 2048
使用单卡进行训练,大概占用20G显存,训练时长40分钟。
-
开始训练

-
训练中

-
训练结束

推理和评估
接下来我们看看训练的效果如何。由于我们训练的是非标准数据集,我们很难以标准评测(如CEval等)来给出训练的好与坏,但是我们仍然可以通过人工推理并评估来衡量训练是否达到效果。
对训练之后的checkpoint(检查点文件)进行推理,需要使用下面的命令:
# ckpt_dir需要填充为实际的输出目录,这个目录在训练的日志中存在。一般分为两种:best_model_checkpoint和last_model_checkpoint,分别是在训练时进行交叉验证loss最低的检查点和最后一次存储的检查点。
swift infer --ckpt_dir output/qwen2-7b-instruct/vxx-xxxx-xxxx/checkpoint-xxx
下面我们用几个简单的问题来试试模型是否已经学废了:
-
你是谁?

-
123+321等于多少?

-
怎么做红烧肉?

-
李白是谁?

-
你最崇拜谁?

部署
模型训练好后,需要进行部署才能在生产条件下使用。这里我们说的生产条件指的是实际的应用环境,比如:给APP提供服务等。部署指的是将模型以服务的形式拉起,并稳定运行,提供HTTP接口给外部环境。
一般而言,目前的服务均提供符合OpenAI格式的标准接口。
部署过程如果写代码非常复杂,因为涉及到编写HTTP服务、拉起模型、推理优化等多个层面的工作。不过幸好我们有命令行:
swift deploy --ckpt_dir /mnt/workspace/output/qwen2-7b-instruct/v4-20241218-102436/checkpoint-1233
执行后会打印一大堆log,等待打印结束:

可以看到输出了一个地址,这时候表示服务已经运行起来了。
下面我们使用一个脚本进行测试:
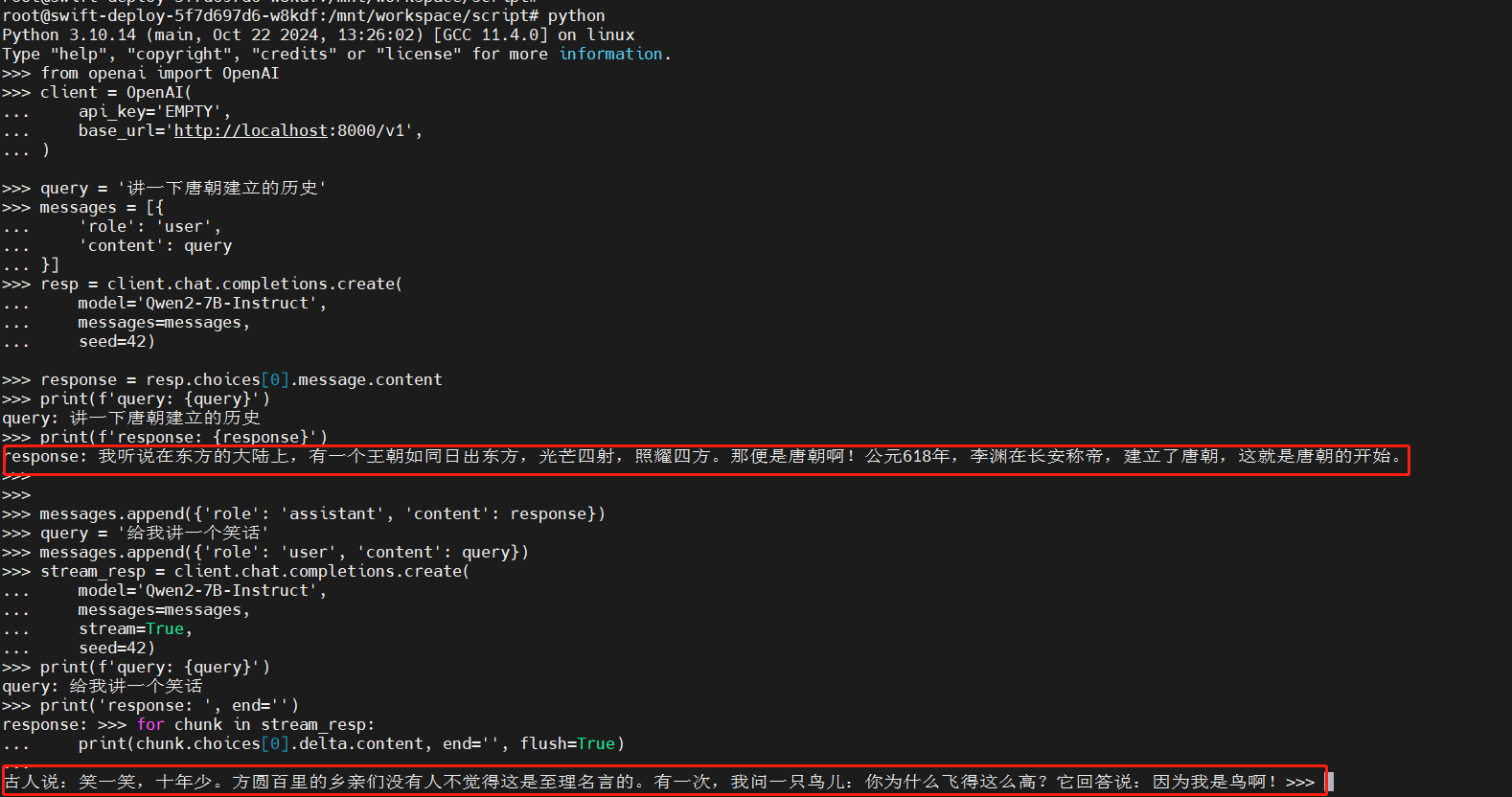
from openai import OpenAI
client = OpenAI(
api_key='EMPTY',
base_url='http://localhost:8000/v1',
)
query = '讲一下唐朝建立的历史'
messages = [{
'role': 'user',
'content': query
}]
resp = client.chat.completions.create(
model='Qwen2-7B-Instruct', #
messages=messages,
seed=42)
response = resp.choices[0].message.content
print(f'query: {query}')
print(f'response: {response}')
# 我听说在东方的大陆上,有一个王朝如同日出东方,光芒四射,照耀四方。那便是唐朝啊!公元618年,李渊在长安称帝,建立了唐朝,这就是唐朝的开始。
messages.append({'role': 'assistant', 'content': response})
query = '给我讲一个笑话'
messages.append({'role': 'user', 'content': query})
stream_resp = client.chat.completions.create(
model='Qwen2-7B-Instruct',
messages=messages,
stream=True,
seed=42)
print(f'query: {query}')
print('response: ', end='')
for chunk in stream_resp:
print(chunk.choices[0].delta.content, end='', flush=True)
print()
# 古人说:笑一笑,十年少。方圆百里的乡亲们没有人不觉得这是至理名言的。有一次,我问一只鸟儿:你为什么飞得这么高?它回答说:因为我是鸟啊!
附录
下面是可能用到的一些使用文档: