从零开始:使用vLLM私有化部署满血版DeepSeek-R1实战指南
DeepSeek-R1是一款拥有671B参数规模的推理大模型,其在数学、编程和推理等复杂任务上的表现,已经与当前主流商业大模型不相上下。
本文将演示如何采用vLLM 和KubeRayKubeRay作为分布式推理解决方案,并利用Alaya NeW算力云提供的弹性容器集群服务作为部署平台,实现DeepSeek-R1模型的高效私有化部署。通过这一整合方案,我们旨在提供一个既灵活又强大的框架,确保深度学习模型在私有环境中的高性能运行与便捷管理。
在该实践中,以“北京一区”作为示例来创建弹性集群。后续使用的镜像仓库等,也都是在“北京一区”开通的。
前提条件
准备工作
配置环境变量
本次部署会用到 helm和 Kubernetes,请先确保本地有可用的Kubernestes客户端工具kubectl,此次的最佳实践以Windows 11系统添加环境为例,配置环境变量的操作步骤如下所示。
- 通过以下网址下载最新版本的kubectl,本实践下载“windows-amd64-v1.27.3-kubectl.exe”文件,在本地新建“kubectl”文件夹,将下载的
.exe文件名称修改为“kubectl”并移动到新建的文件夹下,如果用户需要获取其他版本安装包可通过以下网址获取安装kubectl命令行工具。 - 通过以下网址下载最新版本的helm。本实践下载“helm-v3.17.1-windows-amd64.zip”文件,在本地解压上述文件,将文件名修改为“helm”,如果用户需要获取其他版本安装包可通过以下网址获取helm。
- 右键点击[此电脑/属性]菜单项,进入[系统/系统信息]配置页面,点击“高级系统设置”链接。
- 在[系统属性]页面中,点击[环境变量]按钮,进入环境变量配置页面。
- 在“系统变量”处双击
Path变量新建环境变量,新建如下图所示的环境。新建完成后,单击[确定]按钮,配置环境变量操作完成。
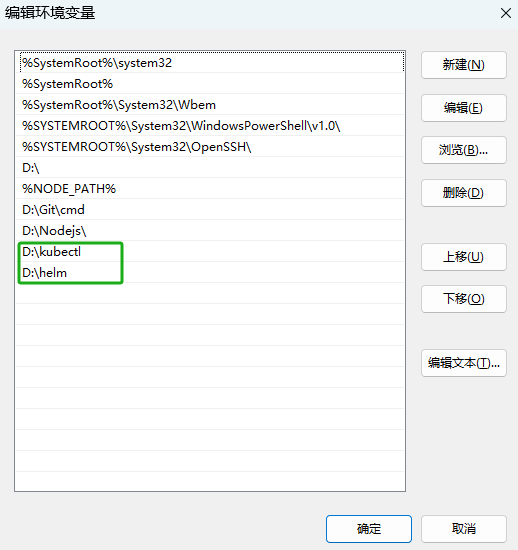
- 在实际的使用中,用户需要将上图中高亮部分替换为“kubectl.exe”、“helm.exe”文件所在的本地路径。
- Linux系统配置环境变量:将helm文件移动到目录“ /usr/local/bin”。
配置弹性容器集群
DeepSeek-R1模型的参数规模为6710亿,模型的文件大小约为642G。因此,在部署前需要准备足够的资源,用户需要保证资源至少满足下表中的配置要求。
| 配置项 | 配置需求 |
|---|---|
| GPU | H800 * 16 |
| CPU | 128核 |
| 内存 | 512GB |
| 磁盘 | 1TB |
开通弹性容器集群可参看开通弹性容器集群操作步骤章节所述。集群开通完成后可在使用弹性容器集群处查看弹性容器集群的使用方式。
此次的最佳实践配置弹性容器集群的操作步骤如下所示。
-
使用已注册的企业账号登录Alaya NeW系统,选择[产品/弹性容器集群]菜单项,单击“新建集群”按钮,进入[弹性容器集群]配置页面。
-
在集群新建页面配置基本信息,例如:集群名称,集群描述,智算中心,此次使用的集群配置如下所示。
配置项 配置详情 集群名称 deeepseek-test 智算中心 北京一区 算力配置 1、型号:H800
2、配额:16卡GPU存储配置 1、选择大容量存储
2、开启StorageClass开关对外服务 开启对外服务开关
在该实践中,创建弹性集群页面上存在但表格中未列出的参数,均采用默认配置。
本实践以“北京一区”作为示例来创建弹性集群。后续使用的镜像仓库等,也都是在“北京一区”开通的。若您选择在其他智算中心(北京二区,北京三区等)开通弹性容器集群进行本教程的实践,请确认您的弹性容器集群和镜像仓库在同一个智算中心。
-
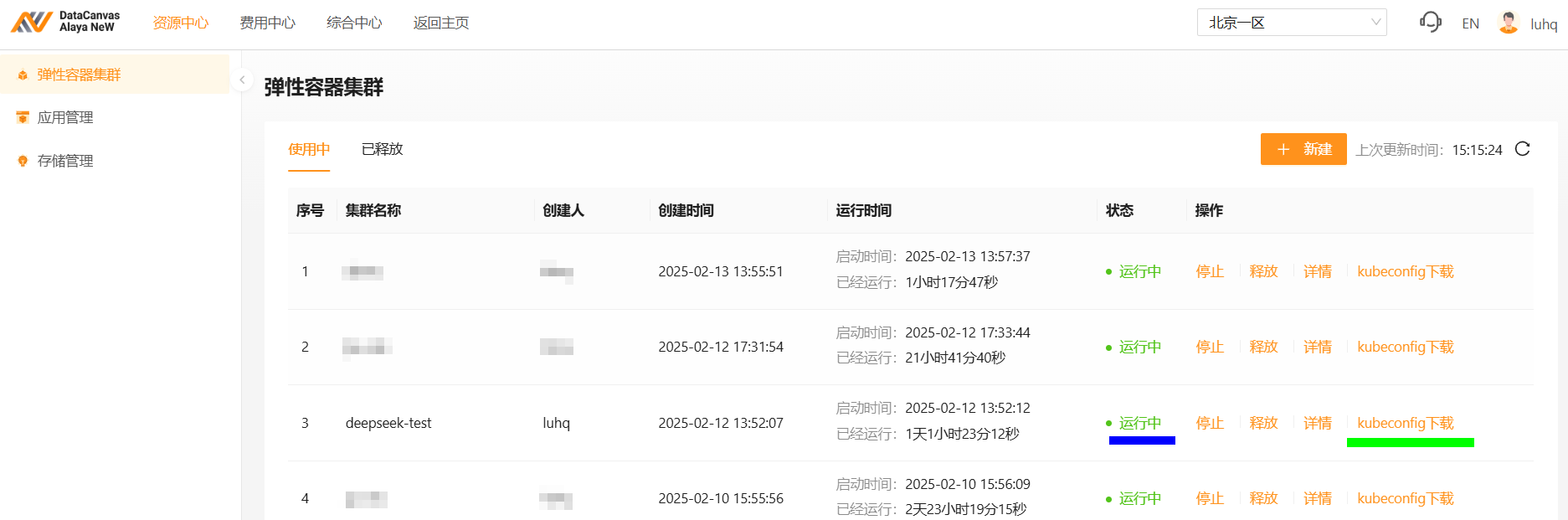
弹性容器集群参数配置完成后,单击“立即开通”按钮,资源开通操作完成,用户可在[资源中心/弹性容器集群]页面查看已创建的容器集群,弹性容器集群状态为“运行中”表示集群可正常使用,如下图蓝色高亮处所示。
-
集群可正常使用后,点击“kubuconfig下载”链接,如上图绿色高亮处所示,将集群的kubeconfig配置文件下载到本机上。
-
在本机上找到上步已经下载的文件,本实践中为“deepseek-test-config.json”,使用
certutil -decode命令解压该文件,如下图所示。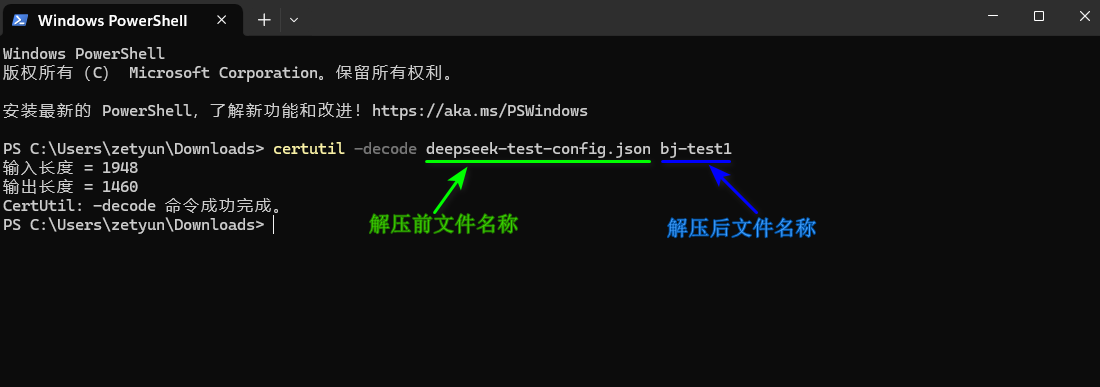
certutil -decode deepseek-test-config.json bj-test1
用户在解压文件的过程中需要注意以下两点:
- 将上图中“解压前文件名称”替换为本机已下载的
kubeconfig文件的名称。 - 将上图中“解压后文件名称”替换为自己实际所需的文件名称。
-
在终端页面,使用
$env:KUBECONFIG命令配置访问弹性容器集群的环境变量,配置时需要将高亮处引号内的路径替换为上步解压后文件的实际路径,本实践的路径如下图所示。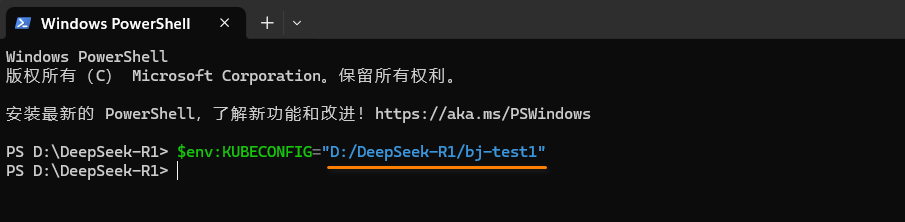
$env:KUBECONFIG="D:/DeepSeek-R1/bj-test1"
- 配置时需要将高亮处引号内的路径替换为上步解压后文件的实际路径。
- 弹性集群环境变量的配置只在当前窗口有效。
- Linux系统使用环境变量的方法为:export KUBECONFIG="kubeconfig配置文件路径"。
-
在终端页面执行如下命令,查看集群信息是否连接成功。若显示如下图所示,表示弹性容器集群连接成功。
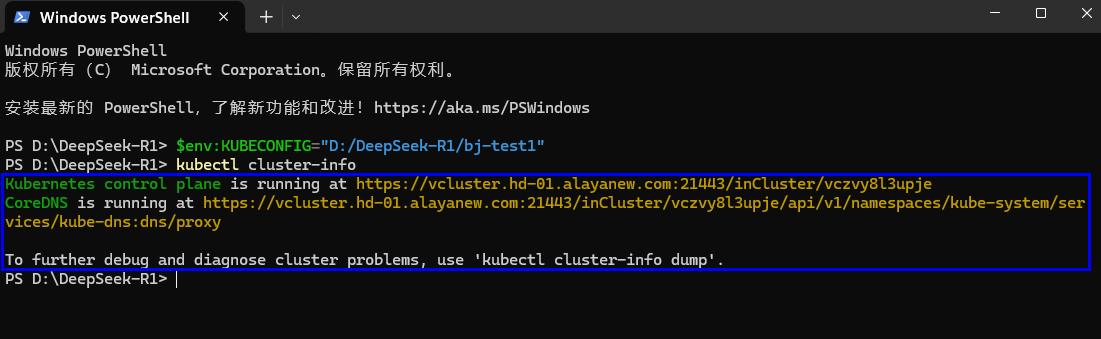
kubectl cluster-info
下载大模型
- 为了方便操作,下载配套的配置文件及示例代码,请点击此处下载,下载并解压后的文件内容如下表所示。
| 文件名 | 描述 |
|---|---|
| prepare.yaml | 准备工作的运行环境,不使用GPU资源,用于模型下载等工作 |
| kuberay-operator | KubeRay Operator的配置文件目录,用于启动operator |
| ray-cluster/ray-cluster.yaml | KubeRay集群的配置文件,用于启动KubeRay集群 |
| ray-cluster/ray-svcExporter-chat.yaml | 网络配置文件,用于暴露DeepSeek的推理服务端口,供外部访问 |
上表中各文件中的配置仅以“北京一区”为示例,若您选择在其他智算中心(北京二区,北京三区,北京四区等)开通弹性容器集群进行本教程的实践,您需要修改以下配置文件:
-
prepare.yaml 文件中HF_ENDPOINT环境变量: 来使用模型的高速下载服务,其他中心的配置可查看模型下载加速。
-
prepare.yaml, sglang-cluster/sglang.yaml,sglang-cluster/sglang-svcExporter-chat.yaml 以上各文件中对应的 “image” 字段需要改成匹配的镜像仓库地址:
- 北京一区:registry.hd-01.alayanew.com:8443
- 北京二区:registry.hd-02.alayanew.com:8443
- 北京三区:registry.hd-03.alayanew.com:8443
- 北京四区:registry.xn-01.alayanew.com:8443
-
双击上步已解压“Deepseek-R1”的文件夹,打开终端页面,使用如下的命令,创建一个名为“deepseek”的NameSpace。
kubectl create namespace deepseek -
在终端使用如下命令,将YAML文件中定义的资源配置应用到集群中。
kubectl apply -f prepare.yaml -
资源应用完成后,请执行以下命令查看“deepseek”命名空间下Pod的运行状态。当Pod的状态显示为“Running”时,表明其已成功启动并正常运行,即可用于后续配置。
kubectl.exe get pod -n deepseek
用户在实际的应用中,需要将“deepseek”替换为实际创建的NameSpace名称。
-
Pod启动成功后,在终端页面执行如下命令进入上一步骤创建的Pod。

kubectl exec -it prepare-deploy-74f545496-9bl62 -n deepseek -- bash
执行上述操作时,需要将“prepare-deploy-74f545496-9bl62”替换为实际使用的Pod名称。
- 为了简化后续操作,建议在终端中执行
tmux命令以创建一个新的会话。有关此工具的详细使用方法,请参阅Tmux的使用的使用。然后,在新开启的Tmux会话页面执行如下所示的命令安装huggingface工具。
pip install huggingface
-
工具安装完成后,在终端执行以下命令下载DeepSeek-R1模型,如下图所示。
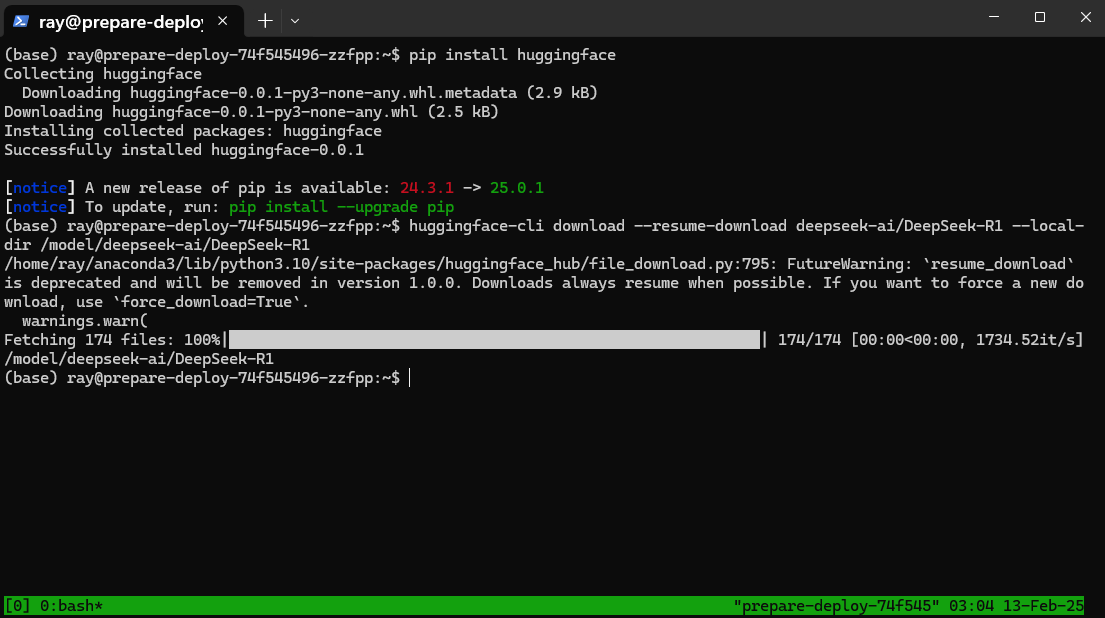
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1 --local-dir /model/deepseek-ai/DeepSeek-R1
模型文件大约642G,初次下载时间可能较长,请耐心等待。
- 本实践使用KubeRay做为分布式计算框架来实现多机多卡的分布式推理环境,进入kuberay-operator目录,使用如下的命令部署kuberay-operator。
helm install kuberay-operator -n deepseek --version 1.2.2 .
- kuberay-operator部署成功后,执行下面的命令查看已部署的资源的状态,部署成功后kuberay-operator状态为“deployed”,表示该资源可正常使用。
helm list -n deepseek
- 在终端页面进入ray-cluster目录,执行如下所示的命令,启动KubeRay集群。
kubectl apply -f ray-cluster.yaml
-
集群启动成功后,在终端页面执行如下命令查看服务运行情况,所有Pod运行状态均为“Running”,如下图所示,表示资源可正常使用。
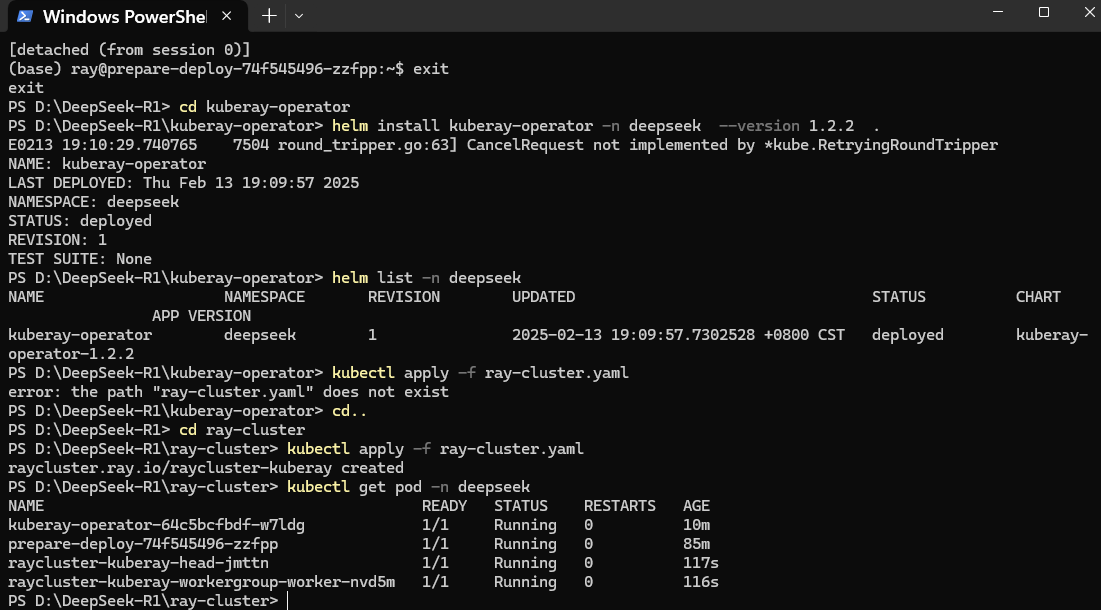
kubectl get pod -n deepseek
外部访问配置
在弹性容器集群中,无法直接使用 NodePort方式暴露服务。对于需要外部访问的服务,我们可以使用 ServiceExporter。ServiceExporter是弹性容器集群中用于将服务暴露到外部的组件,将其与需要对外提供服务的 Service绑定,为用户提供外部访问的地址。获取访问地址的步骤如下所示。
- 在终端页面执行如下所示的命令,创建ServiceExporter资源。
kubectl apply -f ray-svcExporter-chat.yaml
-
资源创建成功后,在终端页面执行如下所示命令可以查看
ServiceExporter的信息获取服务访问的地址。通过ServiceExporter方式暴露的服务端口均为“22443”。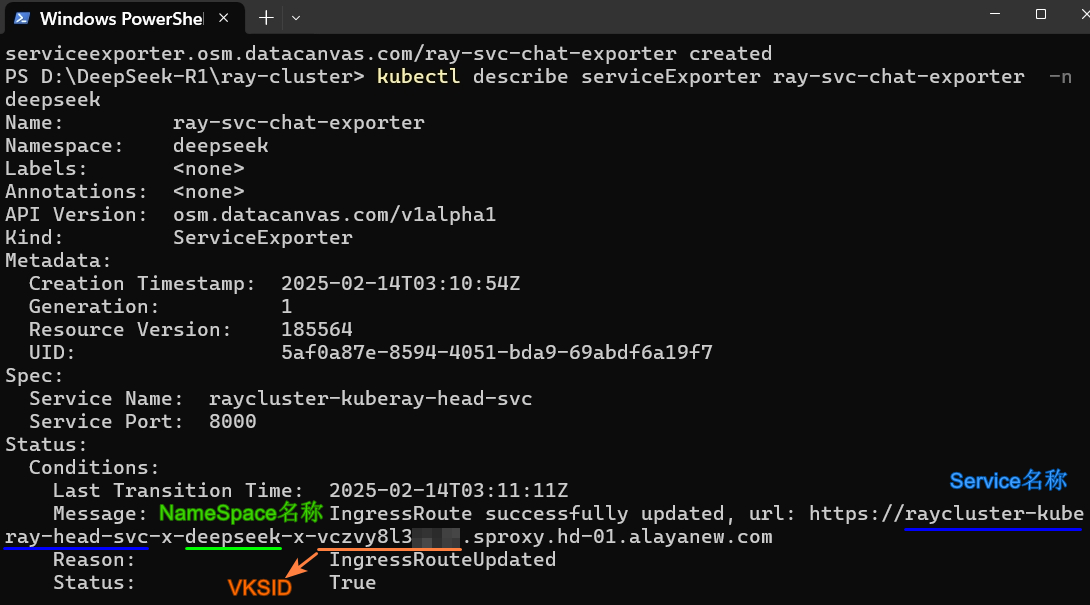
kubectl describe serviceExporter ray-svc-chat-exporter -n deepseek
用户在实际的应用中,需要将本实践中的参数替换为实际的参数,以上图中高亮的URL地址为例,其组成有如下几个部分。
| 属性 | 参数说明 | 参数示例 |
|---|---|---|
| Service Name | 已创建ServiceExporter服务的名称 | raycluster-kuberay-head-svc |
| NameSpace名称 | 部署ServiceExporter服务的NameSpace名称 | deepseek |
| VKSID | 已开通弹性容器集群的ID,用户可通过以下命令查看集群ID | vczvy8l3xxxx |
不同操作系统获取VKSID的命令行如下所示。
- Windows
- Linux
kubectl cluster-info | ForEach-Object { ($_ -split '/')[-1] } | Select-Object -First 1
kubectl cluster-info | awk -F'/' '{print $NF}' | head -n 1
部署DeepSeek-R1模型
- KubeRay集群启动成功后,在上一章节所用终端页面执行如下命令进入容器。
kubectl get pod -n deepseek
kubectl exec -it pod/raycluster-kuberay-head-zh4t6 bash -n deepseek
执行上述操作时,用户需将“raycluster-kuberay-head-zh4t6”替换为实际的Pod名称,填写以“raycluster”开头的Pod名称。
-
执行
tmux命令打开新会话,在新会话页面执行以下命令部署DeepSeek-R1模型,部署页面如下图所示。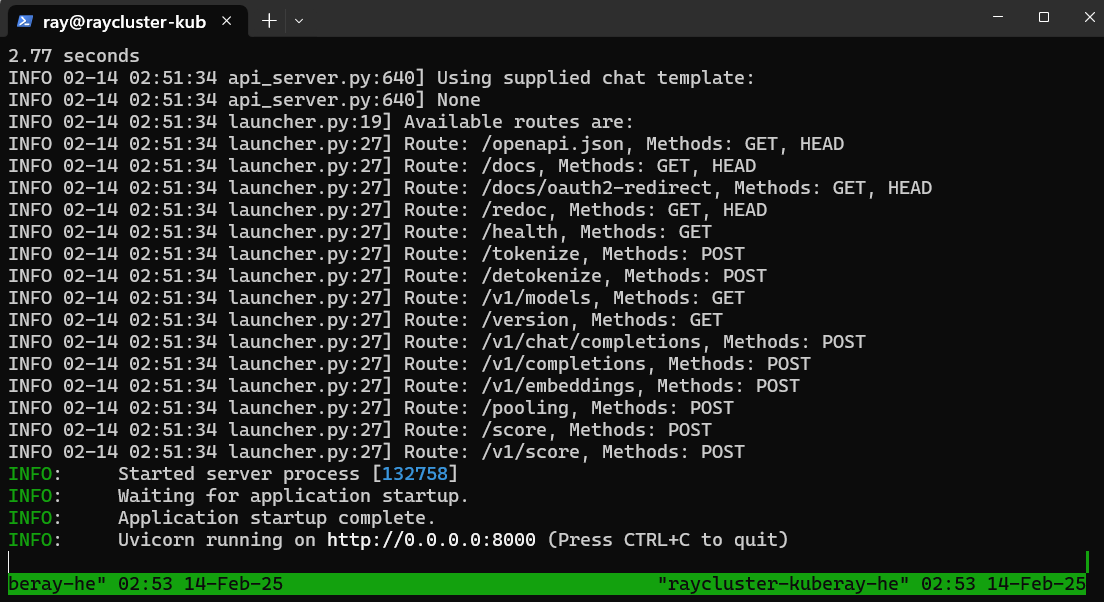
vllm serve /model/deepseek-ai/DeepSeek-R1 \
--tensor-parallel-size 16 \
--gpu-memory-utilization 0.9 \
--num-scheduler-steps 1 \
--max-model-len 8192 \
--trust-remote-code
访问模型
🎉️ 模型部署成功后,用户在终端管理页面可使用curl命令行工具向已部署的服务发送HTTP请求,观察数据响应情况,如下所示,以此来验证服务已经部署成功。
curl https://raycluster-kuberay-head-svc-x-deepseek-x-vczvy8l3xxxx.sproxy.hd-01.alayanew.com:22443/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/model/deepseek-ai/DeepSeek-R1",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "讲个笑话."}
]
}'
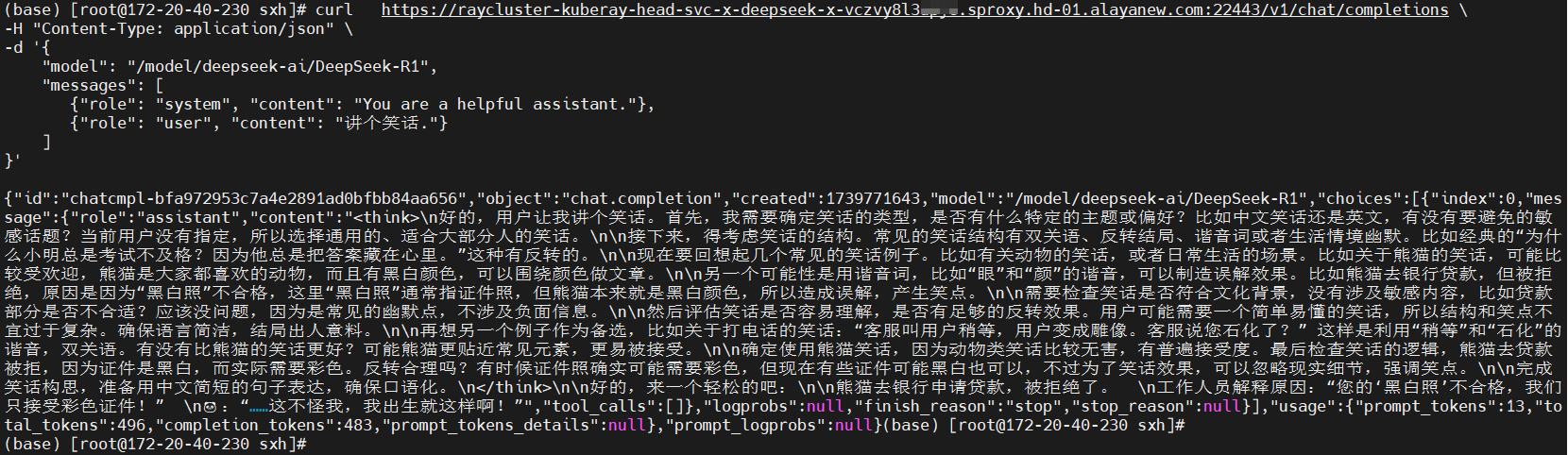
{"id":"chatcmpl-bfa972953c7a4e2891ad0bfbb84aa656","object":"chat.completion","created":1739771643,"model":"/model/deepseek-ai/DeepSeek-R1","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\n好的,用户让我讲个笑话。首先,我需要确定笑话的类型,是否有什么特定的主题或偏好?比如中文笑话还是英文,有没有要避免的敏感话题?当前用户没有指定,所以选择通用的、适合大部分人的笑话。\n\n接下来,得考虑笑话的结构。常见的笑话结构有双关语、反转结局、谐音词或者生活情境幽默。比如经典的“为什么小明总是考试不及格?因为他总是把答案藏在心里。”这种有反转的。\n\n现在要回想起几个常见的笑话例子。比如有关动物的笑话,或者日常生活的场景。比如关于熊猫的笑话,可能比较受欢迎,熊猫是大家都喜欢的动物,而且有黑白颜色,可以围绕颜色做文章。\n\n另一个可能性是用谐音词,比如“眼”和“颜”的谐音,可以制造误解效果。比如熊猫去银行贷款,但被拒绝,原因是因为“黑白照”不合格,这里“黑白照”通常指证件照,但熊猫本来就是黑白颜色,所以造成误解,产生笑点。\n\n需要检查笑话是否符合文化背景,没有涉及敏感内容,比如贷款部分是否不合适?应该没问题,因为是常见的幽默点,不涉及负面信息。\n\n然后评估笑话是否容易理解,是否有足够的反转效果。用户可能需要一个简单易懂的笑话,所以结构和笑点不宜过于复杂。确保语言简洁,结局出人意料。\n\n再想另一个例子作为备选,比如关于打电话的笑话:“客服叫用户稍等,用户变成雕像。客服说您石化了?” 这样是利用“稍等”和“石化”的谐音,双关语。有没有比熊猫的笑话更好?可能熊猫更贴近常见元素,更易被接受。\n\n确定使用熊猫笑话,因为动物类笑话比较无害,有普遍接受度。最后检查笑话的逻辑,熊猫去贷款被拒,因为证件是黑白,而实际需要彩色。反转合理吗?有时候证件照确实可能需要彩色,但现在有些证件可能黑白也可以,不过为了笑话效果,可以忽略现实细节,强调笑点。\n\n完成笑话构思,准备用中文简短的句子表达,确保口语化。\n</think>\n\n好的,来一个轻松的吧:\n\n熊猫去银行申请贷款,被拒绝了。 \n工作人员解释原因:“您的‘黑白照’不合格,我们只接受彩色证件!” \n🐼:“……这不怪我,我出生就这样啊!”","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":13,"total_tokens":496,"completion_tokens":483,"prompt_tokens_details":null},"prompt_logprobs":null}(base) [root@172-20-40-230 sxh]#
🎉️ 除了上述访问方式外,用户还可以通过Python代码使用已部署的服务。
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "https://raycluster-kuberay-head-svc-x-deepseek-x-vczvy8l3xxxx.sproxy.hd-01.alayanew.com:22443/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="/model/deepseek-ai/DeepSeek-R1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "讲个笑话."},
],
stream=True
)
🎉️ 此外用户也可使用跨平台 AI 客户端工具,例如AnythingLLM、Chatbox AI、Cherry Studio等客户端工具,调用已部署的服务。本实践以Chatbox AI工具为例,服务调用页面如下所示。
在实际应用访问中,请将本实践中的访问地址替换为已部署的服务地址。具体来说,需要将 "(https://raycluster-kuberay-head-svc-x-deepseek-x-vczvy8l3xxxx.sproxy.hd-01.alayanew.com)" 替换为用户实际部署的服务地址。
总结
至此,我们已经完成了使用KubeRay和vLLM部署DeepSeek-R1模型的全部流程。本文档为DeepSeek-R1的私有化部署提供了一个全面的指南,内容涵盖了从环境配置到模型推理访问的各个技术环节。借助分布式推理模式,不仅能够充分发挥大型模型的性能潜力,还加速了AI应用的规模化实施。