基于NeMo微调Llama 3 实践
Nemo架构是一个用于构建、训练和部署大型语言模型(LLMs)、多模态模型、自动语音识别(ASR)、文本到语音(TTS)和计算机视觉(CV)的端到端云原生框架。NeMo框架提供了一套工具来执行Llama 3模型的LoRA微调,以适应特定的用例。使用LoRA技术,可以在保持参数数量较少的同时,对模型进行有效的微调,减少计算需求。NVIDIA H800 Tensor Core GPU结合TensorRT-LLM技术,为Llama 3模型提供了出色的训练、微调性能。通过这种方式,NeMo框架为Llama 3模型的微调提供了一个高效、灵活的解决方案,以满足多样化的应用需求。
使用场景
场景一:个性化模型服务
企业可以为客户提供个性化模型,用于推荐服务或根据特定角色或偏好进行调整。
场景二:企业AI应用中的模型定制
随着LLM在企业AI应用中的吸引力增加,定制化模型以理解和集成特定行业术语、领域专业知识和独特的组织要求变得重要。NeMo 提供了简化LLM微调和对齐的服务。
方案概述
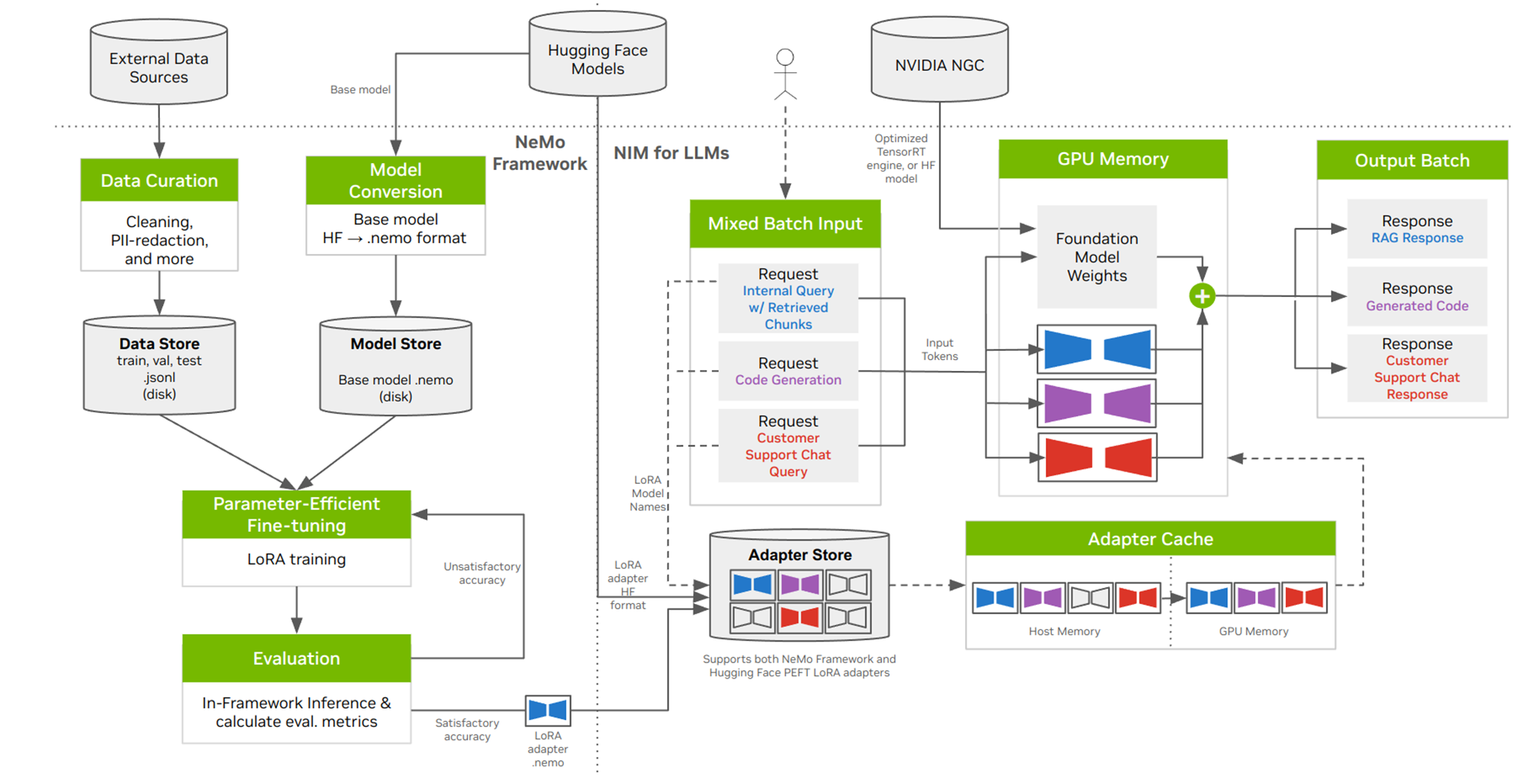
部署前准备工作
开通集群
具体步骤参考:开通弹性容器集群
请确认 弹性容器集群 和后面使用的 镜像仓库 是在同一个智算中心开通的。
模型,数据准备
下载以下模型及数据文件,并同步至对象存储,对象存储的同步方法请参考:对象存储的使用
- 下载lama3.nemo模型文件
- 下载 PubMedQA数据集
镜像准备
下载以下镜像并推送至你的镜像仓库,镜像仓库的使用请参考:
- 下载NeMo Framework Container
- 从NGC官网下载llama3-8b-instruct:1.0.3NIM推理镜像并推送到你的镜像仓库
请确认 镜像仓库 和 弹性容器集群 是在同一个智算中心开通的。
以下命令中,请将账号,密码,镜像名称,镜像仓库地址等信息替换成你自己的。
用户名/密码:查看开通镜像仓库时的通知短信
镜像仓库域名:参考镜像仓库的使用
镜像仓库地址 :由 镜像仓库域名/项目 组成
脚本准备
首先下载本教程所需要的源码文件
清单
本教程包含以下文件,以下是文件的作用说明。
| 文件名 | 说明 |
|---|---|
| config_harbor_secret.json | 配置与 Harbor 容器镜像仓库相关的敏感信息 |
| nemo_harbor_secret.yaml | 定义secret资源:在部署deployment资源时,用来拉取自定义镜像 |
| nemo_pod.yaml | 定义Pod资源:定义如何启停pod |
脚本简介
nemo_harbor_secret.yaml
定义secret资源:在部署deployment资源时,用来拉取自定义镜像
(1)编辑config_harbor_secret.json 的文件,内容如下:
{
"auths": {
"镜像仓库访问域名": {
"username": "用户名",
"password": "密码",
"email": "邮箱"
}
}
}
编写config.json文件时,请将以下信息替换为你的实际信息:镜像仓库访问域名,用户名,密码,邮箱
(2)使用 base64 命令对 config.json 文件进行编码
base64 config.json
(3)编写nemo_harbor_secret.yaml,将输出的 base64 编码字符串替换到文件中的 .dockerconfigjson 字段中
#sd_harbor_secret.yaml 文件
apiVersion: v1
kind: Secret
metadata:
name: harbor-secret
namespace: nemo
type: kubernetes.io/dockerconfigjson
data:
.dockerconfigjson: ******
将“******”替换为步骤4.2输出的base64编码
nemo_pod.yaml
定义Pod资源:定义如何启停pod
apiVersion: v1
kind: Pod
metadata:
name: nemo-test
namespace: nim
spec:
restartPolicy: Always
securityContext:
runAsUser: 1000
runAsGroup: 1000
fsGroup: 1000
containers:
- name: nemo-container
image: 镜像仓库访问地址/nemo:24.05 # 替换成你的镜像
command: ['tail','-f','/dev/null']
#command: ['bash']
workingDir: /workspace
resources:
requests:
memory: "60Gi"
ephemeral-storage: 15Gi
limits:
memory: "80Gi"
ephemeral-storage: 20Gi
nvidia.com/gpu-h800: 1 # requesting 1 GPU
volumeMounts:
- mountPath: /workspace
name: workspace
subPath: "nemo/worspace"
- mountPath: /dev/shm
name: dshm
env:
- name: NGC_API_KEY
valueFrom:
secretKeyRef:
name: ngc-api
key: NGC_API_KEY
imagePullSecrets:
- name: harbor-secret
volumes:
- name: workspace
persistentVolumeClaim:
claimName: pvc-capacity-userdata
- name: dshm
emptyDir:
medium: Memory
将镜像 "镜像仓库访问地址/nemo:24.05" 替换为你实际的镜像。
操作步骤
启动pod
# 声明弹性容器集群配置
export KUBECONFIG="[/path/to/kubeconfig]"
# 创建namespace
kubectl create namespace nemo
# 创建secret
kubectl apply -f nemo_harbor_secret.yaml
# 生成NGC仓库文件下载权限
export NGC_API_KEY=[Your ngc_api_key] # 替换成你的ngc_api_key
kubectl -n nim create secret docker-registry registry-secret
--docker-server=nvcr.io
--docker-username='$oauthtoken'
--docker-password=$NGC_API_KEY
kubectl -n nim create secret generic ngc-api --from-literal=NGC_API_KEY=$NGC_API_KEY
# 创建pod
kubectl apply -f nemo_pod.yaml
Yolo微调llama3大模型
- 数据准备,从对象存储中下载数据下载 PubMedQA数据集
# 从对象存储中下载数据
rclone cp s3_store:pubmedqa /workspace
- 数据拆分
# split it into train/val/test datasets
cd pubmedqa/preprocess
python split_dataset.py pqal
split_dataset.py为PubMedQA数据集自带的数据拆分脚本
- 数据处理
python convert_data.py
convert_data.py为PubMedQA数据集自带的数据处理脚本
- 模型参数格式转换:从Hugging Face格式转换成NeMo格式。(如果您已经有了Llama模型的.nemo文件,您可以跳过这一步)。
# convert_nemo.sh
python /opt/NeMo/scripts/checkpoint_converters/convert_llama_hf_to_nemo.py --input_name_or_path=./meta-llama/Meta-Llama-3-8B/ --output_path=llama3-8b-instruct.nemo
convert_llama_hf_to_nemo.py为Nemo架构自带的NeMo格式转换脚本
- Yolo微调大模型
以下为微调脚本,保存成lora_train.py文件到某路径下,在执行该脚本即可执行lora训练任务
# Set paths to the model, train, validation and test sets.
MODEL="/workspace/llama3-8b-instruct.nemo"
TRAIN_DS="[./pubmedqa/data/pubmedqa_train.jsonl]"
VALID_DS="[./pubmedqa/data/pubmedqa_val.jsonl]"
TEST_DS="[./pubmedqa/data/pubmedqa_test.jsonl]"
TEST_NAMES="[pubmedqa]"
export MPLCONFIGDIR=./.config/matplotlib
export TRANSFORMERS_CACHE=./.cache/huggingface/hub
SCHEME="lora"
TP_SIZE=1
PP_SIZE=1
mkdir /results/Meta-Llama-3-8B-Instruct
OUTPUT_DIR="/results/Meta-Llama-3-8B-Instruct"
#rm -r $OUTPUT_DIR
torchrun --nproc_per_node=1 \
/opt/NeMo/examples/nlp/language_modeling/tuning/megatron_gpt_finetuning.py \
exp_manager.exp_dir=${OUTPUT_DIR} \
exp_manager.explicit_log_dir=${OUTPUT_DIR} \
trainer.devices=1 \
trainer.num_nodes=1 \
trainer.precision=bf16-mixed \
trainer.val_check_interval=0.2 \
trainer.max_steps=50 \
model.megatron_amp_O2=True \
++model.mcore_gpt=True \
model.tensor_model_parallel_size=${TP_SIZE} \
model.pipeline_model_parallel_size=${PP_SIZE} \
model.micro_batch_size=1 \
model.global_batch_size=8 \
model.restore_from_path=${MODEL} \
model.data.train_ds.num_workers=0 \
model.data.validation_ds.num_workers=0 \
model.data.train_ds.file_names=${TRAIN_DS} \
model.data.train_ds.concat_sampling_probabilities=[1.0] \
model.data.validation_ds.file_names=${VALID_DS} \
model.peft.peft_scheme=${SCHEME}
微调结束后将创建一个LoRA适配器,一个名为megatron_gpt_peft_lora_tuning.nemo的文件,在/results/Meta-Llama-3-8B-Instruct/checkpoints/目录下。至此,基于Nemo架构lora微调llama3任务完成。
![]()